 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Language Modelling with Noise-contrastive estimation
Paper and Code
Sep 22, 2017
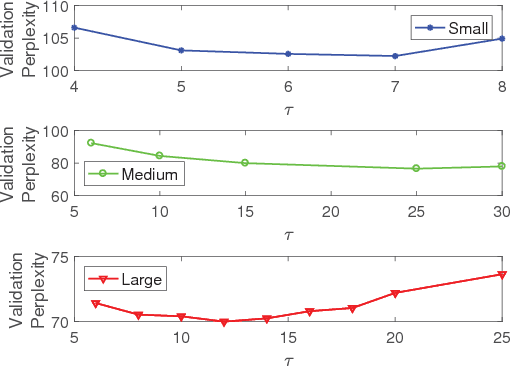

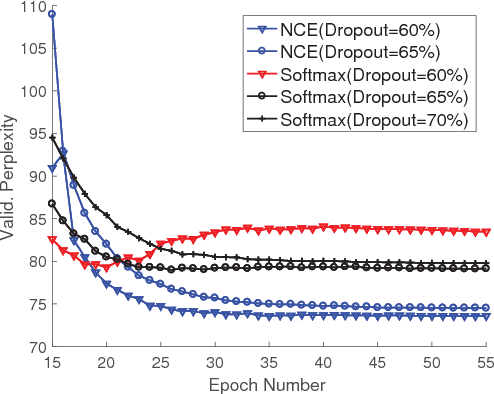
Neural language models do not scale well when the vocabulary is large. Noise-contrastive estimation (NCE) is a sampling-based method that allows for fast learning with large vocabularies. Although NCE has shown promising performance in neural machine translation, it was considered to be an unsuccessful approach for language modelling. A sufficient investigation of the hyperparameters in the NCE-based neural language models was also missing. In this paper, we showed that NCE can be a successful approach in neural language modelling when the hyperparameters of a neural network are tuned appropriately. We introduced the 'search-then-converge' learning rate schedule for NCE and designed a heuristic that specifies how to use this schedule. The impact of the other important hyperparameters, such as the dropout rate and the weight initialisation range, was also demonstrated. We showed that appropriate tuning of NCE-based neural language models outperforms the state-of-the-art single-model methods on a popular benchmark.