 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics of Affective States During Takeover Requests in Conditionally Automated Driving Among Older Adults with and without Cognitive Impairment
May 23, 2025
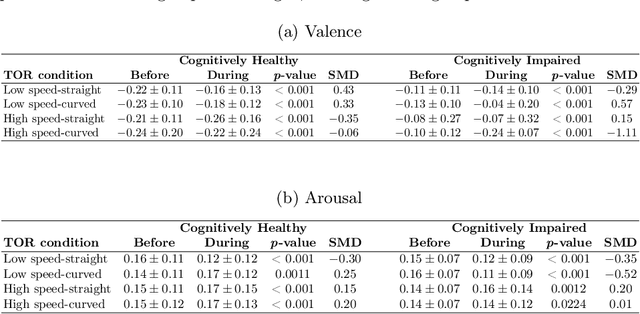
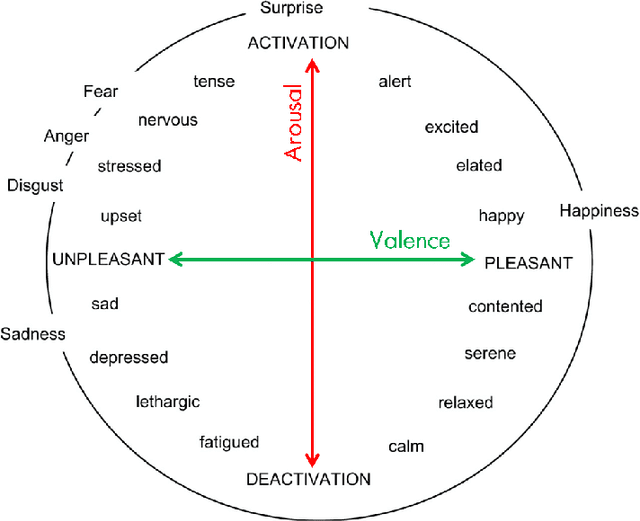
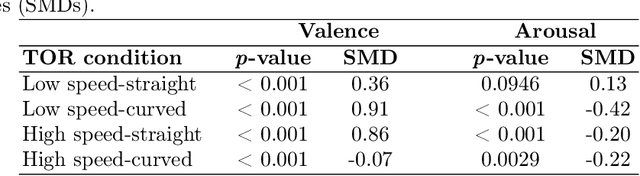
Driving is a key component of independence and quality of life for older adults. However, cognitive decline associated with conditions such as mild cognitive impairment and dementia can compromise driving safety and often lead to premature driving cessation. Conditionally automated vehicles, which require drivers to take over control when automation reaches its operational limits, offer a potential assistive solution. However, their effectiveness depends on the driver's ability to respond to takeover requests (TORs) in a timely and appropriate manner. Understanding emotional responses during TORs can provide insight into drivers' engagement, stress levels, and readiness to resume control, particularly in cognitively vulnerable populations. This study investigated affective responses, measured via facial expression analysis of valence and arousal, during TORs among cognitively healthy older adults and those with cognitive impairment. Facial affect data were analyzed across different road geometries and speeds to evaluate within- and between-group differences in affective states. Within-group comparisons using the Wilcoxon signed-rank test revealed significant changes in valence and arousal during TORs for both groups. Cognitively healthy individuals showed adaptive increases in arousal under higher-demand conditions, while those with cognitive impairment exhibited reduced arousal and more positive valence in several scenarios. Between-group comparisons using the Mann-Whitney U test indicated that cognitively impaired individuals displayed lower arousal and higher valence than controls across different TOR conditions. These findings suggest reduced emotional response and awareness in cognitively impaired drivers, highlighting the need for adaptive vehicle systems that detect affective states and support safe handovers for vulnerable users.
Depth-Weighted Detection of Behaviours of Risk in People with Dementia using Cameras
Aug 28, 2024



The behavioural and psychological symptoms of dementia, such as agitation and aggression, present a significant health and safety risk in residential care settings. Many care facilities have video cameras in place for digital monitoring of public spaces, which can be leveraged to develop an automated behaviours of risk detection system that can alert the staff to enable timely intervention and prevent the situation from escalating. However, one of the challenges in our previous study was the presence of false alarms due to obstruction of view by activities happening close to the camera. To address this issue, we proposed a novel depth-weighted loss function to train a customized convolutional autoencoder to enforce equivalent importance to the events happening both near and far from the cameras; thus, helping to reduce false alarms and making the method more suitable for real-world deployment. The proposed method was trained using data from nine participants with dementia across three cameras situated in a specialized dementia unit and achieved an area under the curve of receiver operating characteristic of $0.852$, $0.81$ and $0.768$ for the three cameras. Ablation analysis was conducted for the individual components of the proposed method and the performance of the proposed method was investigated for participant-specific and sex-specific behaviours of risk detection. The proposed method performed reasonably well in detecting behaviours of risk in people with dementia motivating further research toward the development of a behaviours of risk detection system suitable for deployment in video surveillance systems in care facilities.
Temporal Shift -- Multi-Objective Loss Function for Improved Anomaly Fall Detection
Nov 06, 2023Falls are a major cause of injuries and deaths among older adults worldwide. Accurate fall detection can help reduce potential injuries and additional health complications. Different types of video modalities can be used in a home setting to detect falls, including RGB, Infrared, and Thermal cameras. Anomaly detection frameworks using autoencoders and their variants can be used for fall detection due to the data imbalance that arises from the rarity and diversity of falls. However, the use of reconstruction error in autoencoders can limit the application of networks' structures that propagate information. In this paper, we propose a new multi-objective loss function called Temporal Shift, which aims to predict both future and reconstructed frames within a window of sequential frames. The proposed loss function is evaluated on a semi-naturalistic fall detection dataset containing multiple camera modalities. The autoencoders were trained on normal activities of daily living (ADL) performed by older adults and tested on ADLs and falls performed by young adults. Temporal shift shows significant improvement to a baseline 3D Convolutional autoencoder, an attention U-Net CAE, and a multi-modal neural network. The greatest improvement was observed in an attention U-Net model improving by 0.20 AUC ROC for a single camera when compared to reconstruction alone. With significant improvement across different models, this approach has the potential to be widely adopted and improve anomaly detection capabilities in other settings besides fall detection.
StairNet: Visual Recognition of Stairs for Human-Robot Locomotion
Oct 31, 2023Human-robot walking with prosthetic legs and exoskeletons, especially over complex terrains such as stairs, remains a significant challenge. Egocentric vision has the unique potential to detect the walking environment prior to physical interactions, which can improve transitions to and from stairs. This motivated us to create the StairNet initiative to support the development of new deep learning models for visual sensing and recognition of stairs, with an emphasis on lightweight and efficient neural networks for onboard real-time inference. In this study, we present an overview of the development of our large-scale dataset with over 515,000 manually labeled images, as well as our development of different deep learning models (e.g., 2D and 3D CNN, hybrid CNN and LSTM, and ViT networks) and training methods (e.g., supervised learning with temporal data and semi-supervised learning with unlabeled images) using our new dataset. We consistently achieved high classification accuracy (i.e., up to 98.8%) with different designs, offering trade-offs between model accuracy and size. When deployed on mobile devices with GPU and NPU accelerators, our deep learning models achieved inference speeds up to 2.8 ms. We also deployed our models on custom-designed CPU-powered smart glasses. However, limitations in the embedded hardware yielded slower inference speeds of 1.5 seconds, presenting a trade-off between human-centered design and performance. Overall, we showed that StairNet can be an effective platform to develop and study new visual perception systems for human-robot locomotion with applications in exoskeleton and prosthetic leg control.
Undersampling and Cumulative Class Re-decision Methods to Improve Detection of Agitation in People with Dementia
Feb 07, 2023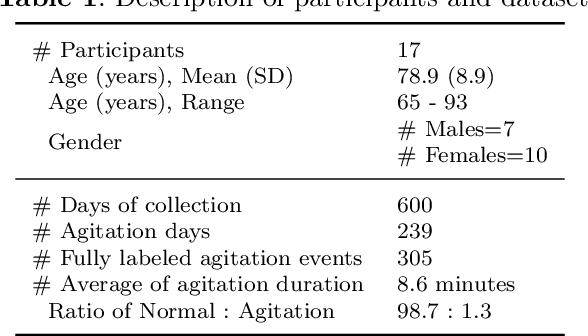
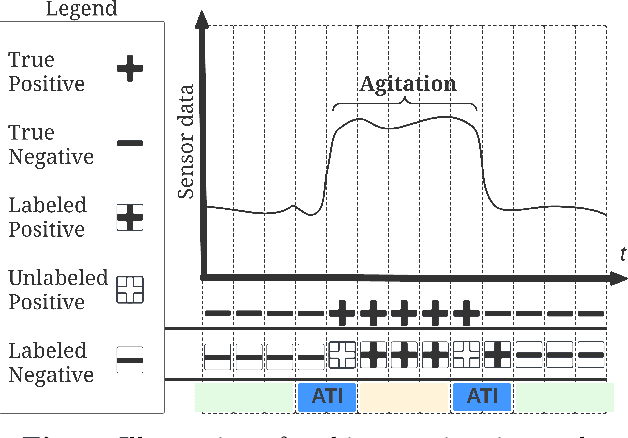
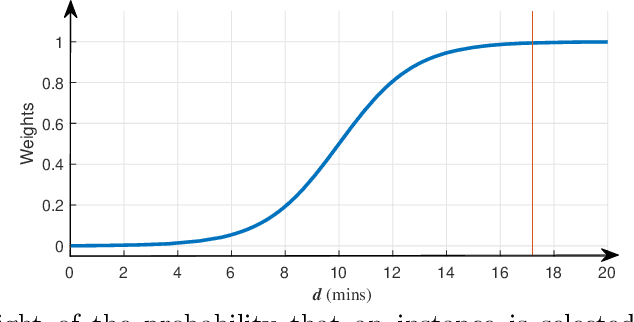
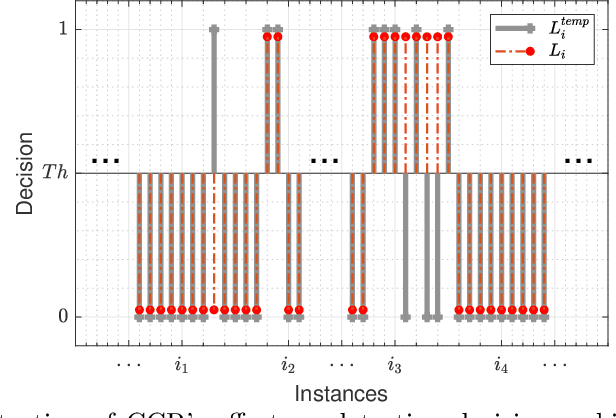
Agitation is one of the most prevalent symptoms in people with dementia (PwD) that can place themselves and the caregiver's safety at risk. Developing objective agitation detection approaches is important to support health and safety of PwD living in a residential setting. In a previous study, we collected multimodal wearable sensor data from 17 participants for 600 days and developed machine learning models for predicting agitation in one-minute windows. However, there are significant limitations in the dataset, such as imbalance problem and potential imprecise labels as the occurrence of agitation is much rarer in comparison to the normal behaviours. In this paper, we first implement different undersampling methods to eliminate the imbalance problem, and come to the conclusion that only 20% of normal behaviour data are adequate to train a competitive agitation detection model. Then, we design a weighted undersampling method to evaluate the manual labeling mechanism given the ambiguous time interval (ATI) assumption. After that, the postprocessing method of cumulative class re-decision (CCR) is proposed based on the historical sequential information and continuity characteristic of agitation, improving the decision-making performance for the potential application of agitation detection system. The results show that a combination of undersampling and CCR improves best F1-score by 26.6% and other metrics to varying degrees with less training time and data used, and inspires a way to find the potential range of optimal threshold reference for clinical purpose.
Skeletal Video Anomaly Detection using Deep Learning: Survey, Challenges and Future Directions
Dec 31, 2022The existing methods for video anomaly detection mostly utilize videos containing identifiable facial and appearance-based features. The use of videos with identifiable faces raises privacy concerns, especially when used in a hospital or community-based setting. Appearance-based features can also be sensitive to pixel-based noise, straining the anomaly detection methods to model the changes in the background and making it difficult to focus on the actions of humans in the foreground. Structural information in the form of skeletons describing the human motion in the videos is privacy-protecting and can overcome some of the problems posed by appearance-based features. In this paper, we present a survey of privacy-protecting deep learning anomaly detection methods using skeletons extracted from videos. We present a novel taxonomy of algorithms based on the various learning approaches. We conclude that skeleton-based approaches for anomaly detection can be a plausible privacy-protecting alternative for video anomaly detection. Lastly, we identify major open research questions and provide guidelines to address them.
Privacy-Protecting Behaviours of Risk Detection in People with Dementia using Videos
Dec 20, 2022People living with dementia often exhibit behavioural and psychological symptoms of dementia that can put their and others' safety at risk. Existing video surveillance systems in long-term care facilities can be used to monitor such behaviours of risk to alert the staff to prevent potential injuries or death in some cases. However, these behaviours of risk events are heterogeneous and infrequent in comparison to normal events. Moreover, analyzing raw videos can also raise privacy concerns. In this paper, we present two novel privacy-protecting video-based anomaly detection approaches to detect behaviours of risks in people with dementia. We either extracted body pose information as skeletons and use semantic segmentation masks to replace multiple humans in the scene with their semantic boundaries. Our work differs from most existing approaches for video anomaly detection that focus on appearance-based features, which can put the privacy of a person at risk and is also susceptible to pixel-based noise, including illumination and viewing direction. We used anonymized videos of normal activities to train customized spatio-temporal convolutional autoencoders and identify behaviours of risk as anomalies. We show our results on a real-world study conducted in a dementia care unit with patients with dementia, containing approximately 21 hours of normal activities data for training and 9 hours of data containing normal and behaviours of risk events for testing. We compared our approaches with the original RGB videos and obtained an equivalent area under the receiver operating characteristic curve performance of 0.807 for the skeleton-based approach and 0.823 for the segmentation mask-based approach. This is one of the first studies to incorporate privacy for the detection of behaviours of risks in people with dementia.
AI-powered Language Assessment Tools for Dementia
Sep 13, 2022
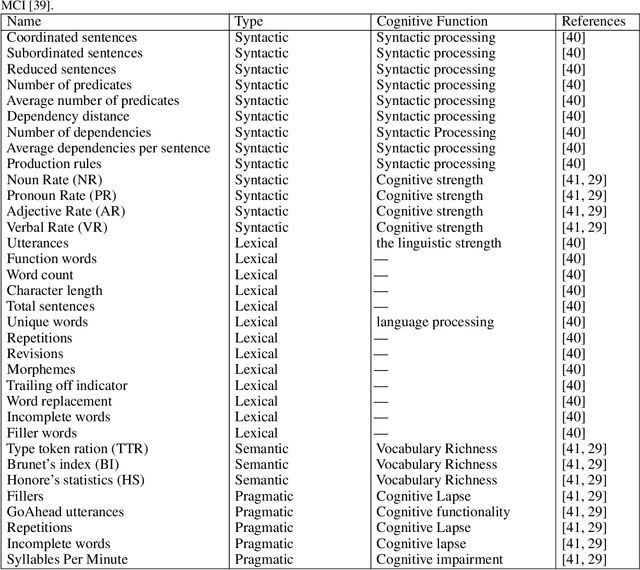

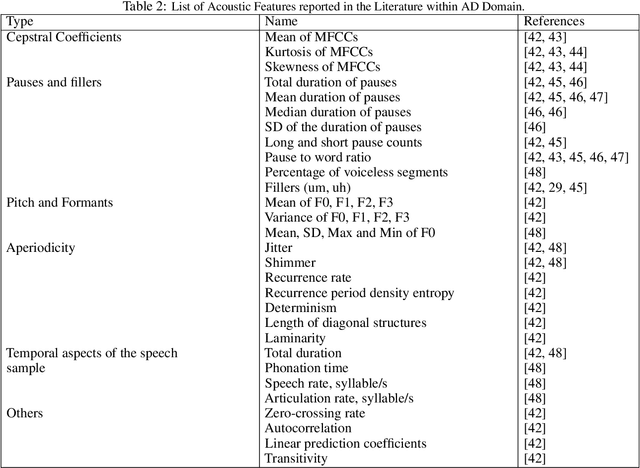
The main objective of this paper is to propose an approach for developing an Artificial Intelligence (AI)-powered Language Assessment (LA) tool. Such tools can be used to assess language impairments associated with dementia in older adults. The Machine Learning (ML) classifiers are the main parts of our proposed approach, therefore to develop an accurate tool with high sensitivity and specificity, we consider different binary classifiers and evaluate their performances. We also assess the reliability and validity of our approach by comparing the impact of different types of language tasks, features, and recording media on the performance of ML classifiers.
Multi Visual Modality Fall Detection Dataset
Jun 25, 2022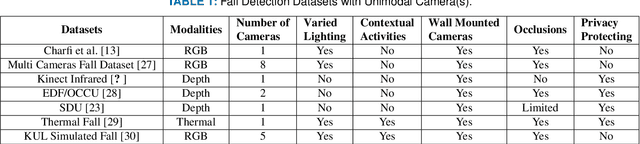

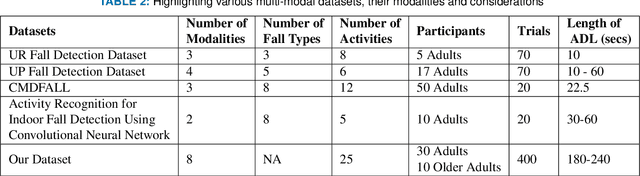
Falls are one of the leading cause of injury-related deaths among the elderly worldwide. Effective detection of falls can reduce the risk of complications and injuries. Fall detection can be performed using wearable devices or ambient sensors; these methods may struggle with user compliance issues or false alarms. Video cameras provide a passive alternative; however, regular RGB cameras are impacted by changing lighting conditions and privacy concerns. From a machine learning perspective, developing an effective fall detection system is challenging because of the rarity and variability of falls. Many existing fall detection datasets lack important real-world considerations, such as varied lighting, continuous activities of daily living (ADLs), and camera placement. The lack of these considerations makes it difficult to develop predictive models that can operate effectively in the real world. To address these limitations, we introduce a novel multi-modality dataset (MUVIM) that contains four visual modalities: infra-red, depth, RGB and thermal cameras. These modalities offer benefits such as obfuscated facial features and improved performance in low-light conditions. We formulated fall detection as an anomaly detection problem, in which a customized spatio-temporal convolutional autoencoder was trained only on ADLs so that a fall would increase the reconstruction error. Our results showed that infra-red cameras provided the highest level of performance (AUC ROC=0.94), followed by thermal (AUC ROC=0.87), depth (AUC ROC=0.86) and RGB (AUC ROC=0.83). This research provides a unique opportunity to analyze the utility of camera modalities in detecting falls in a home setting while balancing performance, passiveness, and privacy.
Tracking agitation in people living with dementia in a care environment
Apr 26, 2021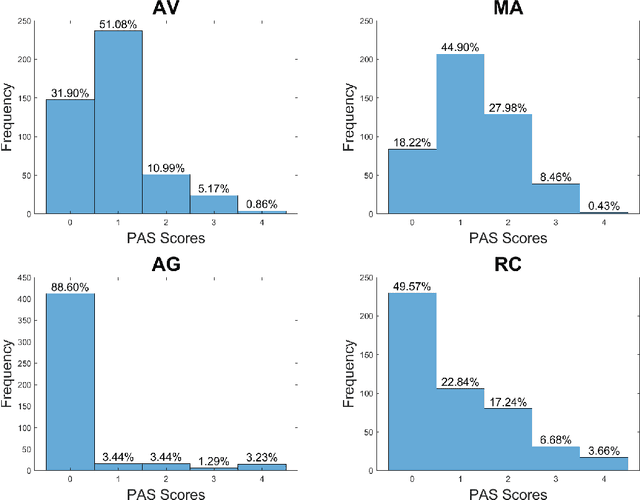
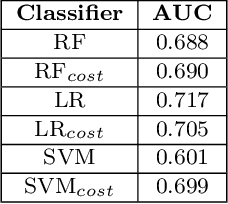
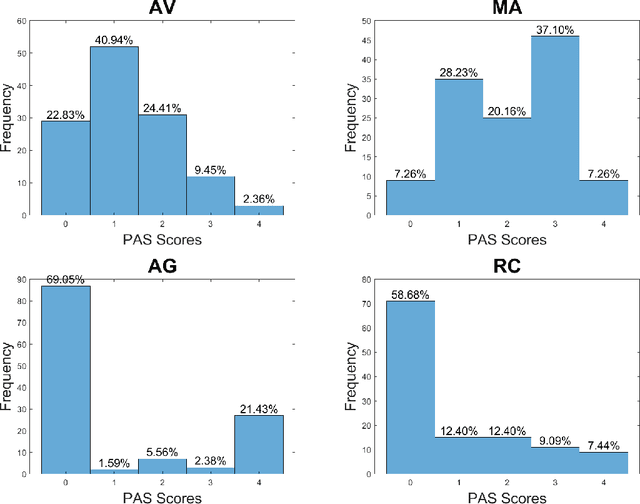

Agitation is a symptom that communicates distress in people living with dementia (PwD), and that can place them and others at risk. In a long term care (LTC) environment, care staff track and document these symptoms as a way to detect when there has been a change in resident status to assess risk, and to monitor for response to interventions. However, this documentation can be time-consuming, and due to staffing constraints, episodes of agitation may go unobserved. This brings into question the reliability of these assessments, and presents an opportunity for technology to help track and monitor behavioural symptoms in dementia. In this paper, we present the outcomes of a 2 year real-world study performed in a dementia unit, where a multi-modal wearable device was worn by $20$ PwD. In line with a commonly used clinical documentation tool, this large multi-modal time-series data was analyzed to track the presence of episodes of agitation in 8-hour nursing shifts. The development of a baseline classification model (AUC=0.717) on this dataset and subsequent improvement (AUC= 0.779) lays the groundwork for automating the process of annotating agitation events in nursing charts.