 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPiKE: 3D Human Pose from Point Cloud Sequences
Sep 03, 2024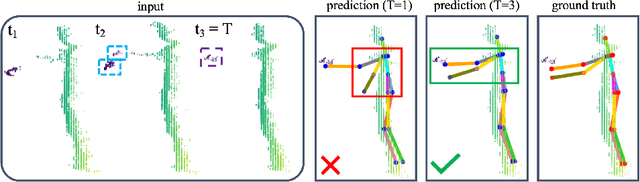
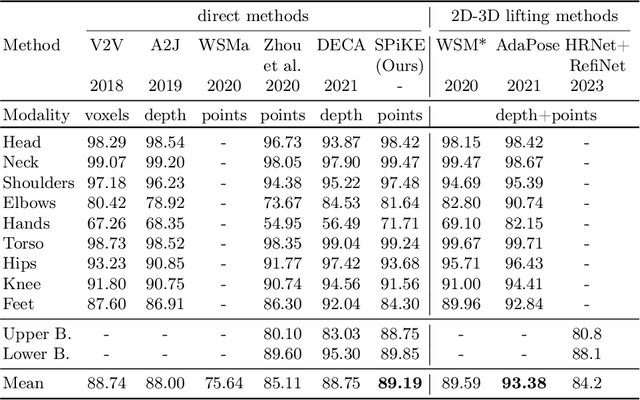
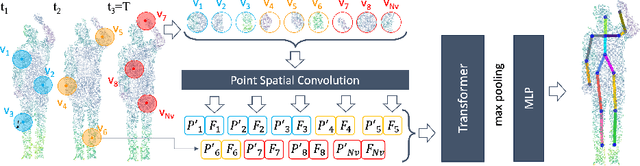
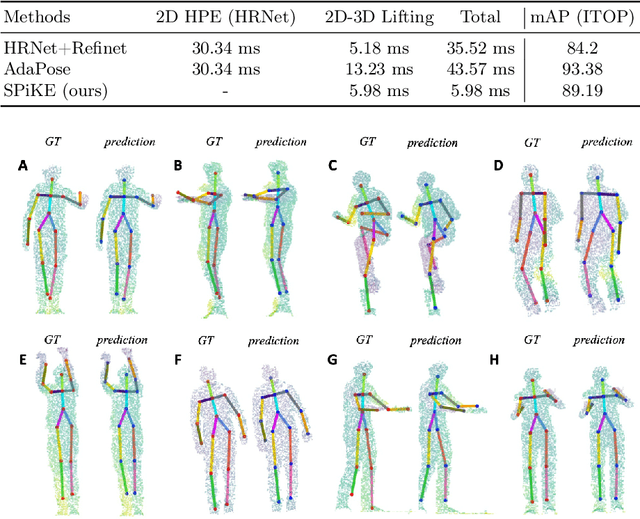
3D Human Pose Estimation (HPE) is the task of locating keypoints of the human body in 3D space from 2D or 3D representations such as RGB images, depth maps or point clouds. Current HPE methods from depth and point clouds predominantly rely on single-frame estimation and do not exploit temporal information from sequences. This paper presents SPiKE, a novel approach to 3D HPE using point cloud sequences. Unlike existing methods that process frames of a sequence independently, SPiKE leverages temporal context by adopting a Transformer architecture to encode spatio-temporal relationships between points across the sequence. By partitioning the point cloud into local volumes and using spatial feature extraction via point spatial convolution, SPiKE ensures efficient processing by the Transformer while preserving spatial integrity per timestamp. Experiments on the ITOP benchmark for 3D HPE show that SPiKE reaches 89.19% mAP, achieving state-of-the-art performance with significantly lower inference times. Extensive ablations further validate the effectiveness of sequence exploitation and our algorithmic choices. Code and models are available at: https://github.com/iballester/SPiKE
Depth-Weighted Detection of Behaviours of Risk in People with Dementia using Cameras
Aug 28, 2024



The behavioural and psychological symptoms of dementia, such as agitation and aggression, present a significant health and safety risk in residential care settings. Many care facilities have video cameras in place for digital monitoring of public spaces, which can be leveraged to develop an automated behaviours of risk detection system that can alert the staff to enable timely intervention and prevent the situation from escalating. However, one of the challenges in our previous study was the presence of false alarms due to obstruction of view by activities happening close to the camera. To address this issue, we proposed a novel depth-weighted loss function to train a customized convolutional autoencoder to enforce equivalent importance to the events happening both near and far from the cameras; thus, helping to reduce false alarms and making the method more suitable for real-world deployment. The proposed method was trained using data from nine participants with dementia across three cameras situated in a specialized dementia unit and achieved an area under the curve of receiver operating characteristic of $0.852$, $0.81$ and $0.768$ for the three cameras. Ablation analysis was conducted for the individual components of the proposed method and the performance of the proposed method was investigated for participant-specific and sex-specific behaviours of risk detection. The proposed method performed reasonably well in detecting behaviours of risk in people with dementia motivating further research toward the development of a behaviours of risk detection system suitable for deployment in video surveillance systems in care facilities.
Benchmarking Skeleton-based Motion Encoder Models for Clinical Applications: Estimating Parkinson's Disease Severity in Walking Sequences
May 28, 2024



This study investigates the application of general human motion encoders trained on large-scale human motion datasets for analyzing gait patterns in PD patients. Although these models have learned a wealth of human biomechanical knowledge, their effectiveness in analyzing pathological movements, such as parkinsonian gait, has yet to be fully validated. We propose a comparative framework and evaluate six pre-trained state-of-the-art human motion encoder models on their ability to predict the Movement Disorder Society - Unified Parkinson's Disease Rating Scale (MDS-UPDRS-III) gait scores from motion capture data. We compare these against a traditional gait feature-based predictive model in a recently released large public PD dataset, including PD patients on and off medication. The feature-based model currently shows higher weighted average accuracy, precision, recall, and F1-score. Motion encoder models with closely comparable results demonstrate promise for scalability and efficiency in clinical settings. This potential is underscored by the enhanced performance of the encoder model upon fine-tuning on PD training set. Four of the six human motion models examined provided prediction scores that were significantly different between on- and off-medication states. This finding reveals the sensitivity of motion encoder models to nuanced clinical changes. It also underscores the necessity for continued customization of these models to better capture disease-specific features, thereby reducing the reliance on labor-intensive feature engineering. Lastly, we establish a benchmark for the analysis of skeleton-based motion encoder models in clinical settings. To the best of our knowledge, this is the first study to provide a benchmark that enables state-of-the-art models to be tested and compete in a clinical context. Codes and benchmark leaderboard are available at code.
DOT: Dynamic Object Tracking for Visual SLAM
Sep 30, 2020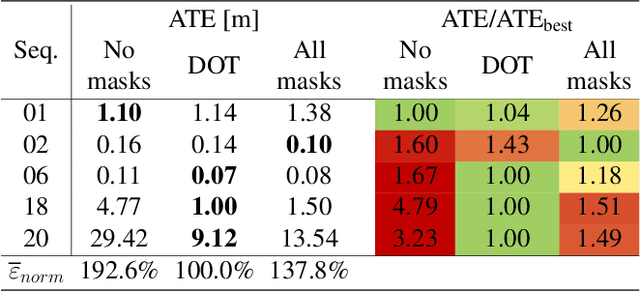

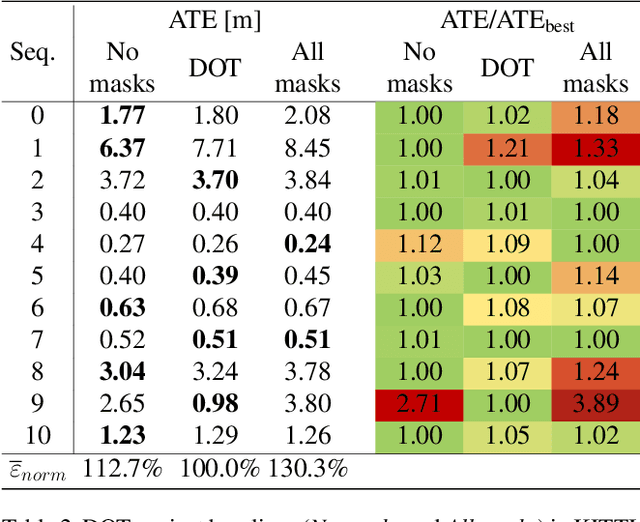

In this paper we present DOT (Dynamic Object Tracking), a front-end that added to existing SLAM systems can significantly improve their robustness and accuracy in highly dynamic environments. DOT combines instance segmentation and multi-view geometry to generate masks for dynamic objects in order to allow SLAM systems based on rigid scene models to avoid such image areas in their optimizations. To determine which objects are actually moving, DOT segments first instances of potentially dynamic objects and then, with the estimated camera motion, tracks such objects by minimizing the photometric reprojection error. This short-term tracking improves the accuracy of the segmentation with respect to other approaches. In the end, only actually dynamic masks are generated. We have evaluated DOT with ORB-SLAM 2 in three public datasets. Our results show that our approach improves significantly the accuracy and robustness of ORB-SLAM 2, especially in highly dynamic scenes.