 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Shot Metric Depth from Focused Plenoptic Cameras
Dec 03, 2024



Metric depth estimation from visual sensors is crucial for robots to perceive, navigate, and interact with their environment. Traditional range imaging setups, such as stereo or structured light cameras, face hassles including calibration, occlusions, and hardware demands, with accuracy limited by the baseline between cameras. Single- and multi-view monocular depth offers a more compact alternative, but is constrained by the unobservability of the metric scale. Light field imaging provides a promising solution for estimating metric depth by using a unique lens configuration through a single device. However, its application to single-view dense metric depth is under-addressed mainly due to the technology's high cost, the lack of public benchmarks, and proprietary geometrical models and software. Our work explores the potential of focused plenoptic cameras for dense metric depth. We propose a novel pipeline that predicts metric depth from a single plenoptic camera shot by first generating a sparse metric point cloud using machine learning, which is then used to scale and align a dense relative depth map regressed by a foundation depth model, resulting in dense metric depth. To validate it, we curated the Light Field & Stereo Image Dataset (LFS) of real-world light field images with stereo depth labels, filling a current gap in existing resources. Experimental results show that our pipeline produces accurate metric depth predictions, laying a solid groundwork for future research in this field.
Unifying Local and Global Multimodal Features for Place Recognition in Aliased and Low-Texture Environments
Mar 20, 2024



Perceptual aliasing and weak textures pose significant challenges to the task of place recognition, hindering the performance of Simultaneous Localization and Mapping (SLAM) systems. This paper presents a novel model, called UMF (standing for Unifying Local and Global Multimodal Features) that 1) leverages multi-modality by cross-attention blocks between vision and LiDAR features, and 2) includes a re-ranking stage that re-orders based on local feature matching the top-k candidates retrieved using a global representation. Our experiments, particularly on sequences captured on a planetary-analogous environment, show that UMF outperforms significantly previous baselines in those challenging aliased environments. Since our work aims to enhance the reliability of SLAM in all situations, we also explore its performance on the widely used RobotCar dataset, for broader applicability. Code and models are available at https://github.com/DLR-RM/UMF
SRT3D: A Sparse Region-Based 3D Object Tracking Approach for the Real World
Oct 25, 2021

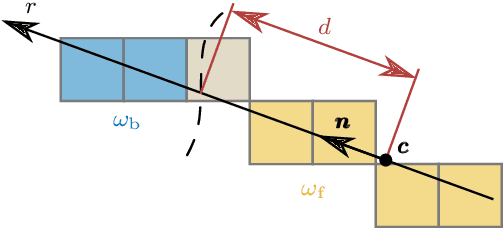
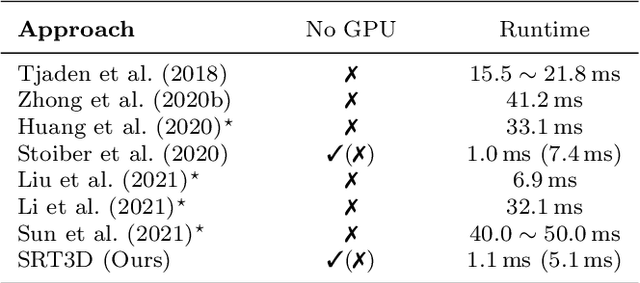
Region-based methods have become increasingly popular for model-based, monocular 3D tracking of texture-less objects in cluttered scenes. However, while they achieve state-of-the-art results, most methods are computationally expensive, requiring significant resources to run in real-time. In the following, we build on our previous work and develop SRT3D, a sparse region-based approach to 3D object tracking that bridges this gap in efficiency. Our method considers image information sparsely along so-called correspondence lines that model the probability of the object's contour location. We thereby improve on the current state of the art and introduce smoothed step functions that consider a defined global and local uncertainty. For the resulting probabilistic formulation, a thorough analysis is provided. Finally, we use a pre-rendered sparse viewpoint model to create a joint posterior probability for the object pose. The function is maximized using second-order Newton optimization with Tikhonov regularization. During the pose estimation, we differentiate between global and local optimization, using a novel approximation for the first-order derivative employed in the Newton method. In multiple experiments, we demonstrate that the resulting algorithm improves the current state of the art both in terms of runtime and quality, performing particularly well for noisy and cluttered images encountered in the real world.
DOT: Dynamic Object Tracking for Visual SLAM
Sep 30, 2020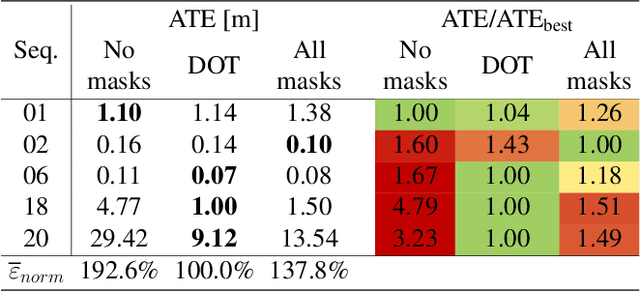

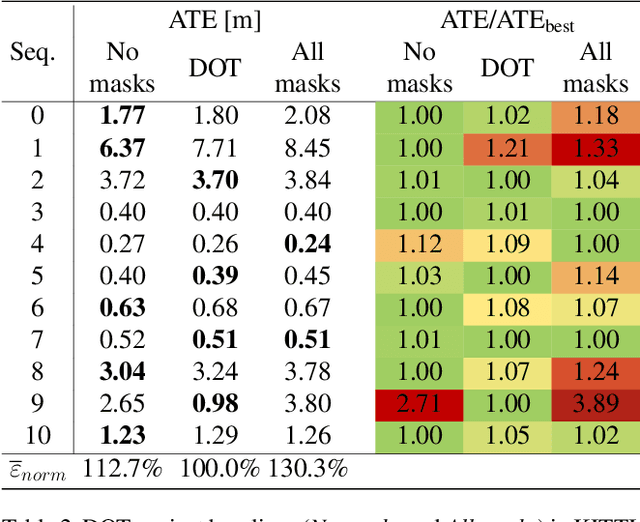

In this paper we present DOT (Dynamic Object Tracking), a front-end that added to existing SLAM systems can significantly improve their robustness and accuracy in highly dynamic environments. DOT combines instance segmentation and multi-view geometry to generate masks for dynamic objects in order to allow SLAM systems based on rigid scene models to avoid such image areas in their optimizations. To determine which objects are actually moving, DOT segments first instances of potentially dynamic objects and then, with the estimated camera motion, tracks such objects by minimizing the photometric reprojection error. This short-term tracking improves the accuracy of the segmentation with respect to other approaches. In the end, only actually dynamic masks are generated. We have evaluated DOT with ORB-SLAM 2 in three public datasets. Our results show that our approach improves significantly the accuracy and robustness of ORB-SLAM 2, especially in highly dynamic scenes.