 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Term Multi-Session 3D Reconstruction Under Substantial Appearance Change
Feb 24, 2026Long-term environmental monitoring requires the ability to reconstruct and align 3D models across repeated site visits separated by months or years. However, existing Structure-from-Motion (SfM) pipelines implicitly assume near-simultaneous image capture and limited appearance change, and therefore fail when applied to long-term monitoring scenarios such as coral reef surveys, where substantial visual and structural change is common. In this paper, we show that the primary limitation of current approaches lies in their reliance on post-hoc alignment of independently reconstructed sessions, which is insufficient under large temporal appearance change. We address this limitation by enforcing cross-session correspondences directly within a joint SfM reconstruction. Our approach combines complementary handcrafted and learned visual features to robustly establish correspondences across large temporal gaps, enabling the reconstruction of a single coherent 3D model from imagery captured years apart, where standard independent and joint SfM pipelines break down. We evaluate our method on long-term coral reef datasets exhibiting significant real-world change, and demonstrate consistent joint reconstruction across sessions in cases where existing methods fail to produce coherent reconstructions. To ensure scalability to large datasets, we further restrict expensive learned feature matching to a small set of likely cross-session image pairs identified via visual place recognition, which reduces computational cost and improves alignment robustness.
Robust Scene Coordinate Regression via Geometrically-Consistent Global Descriptors
Dec 19, 2025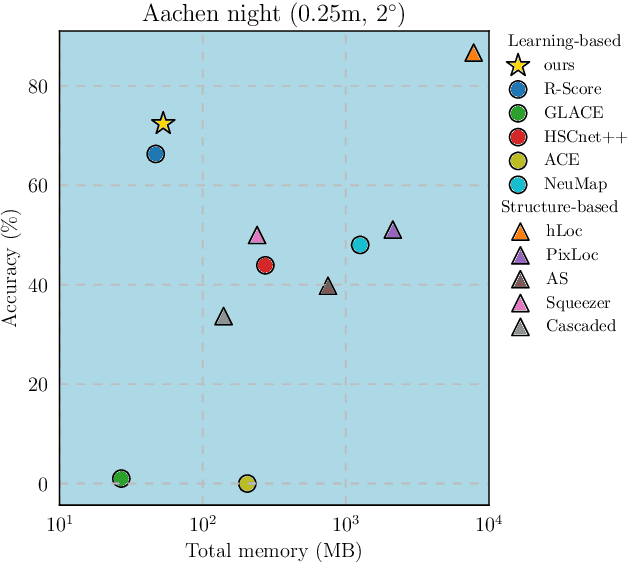
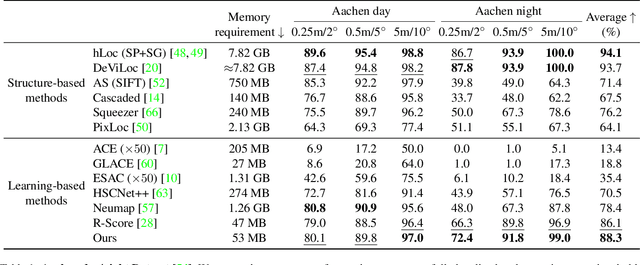
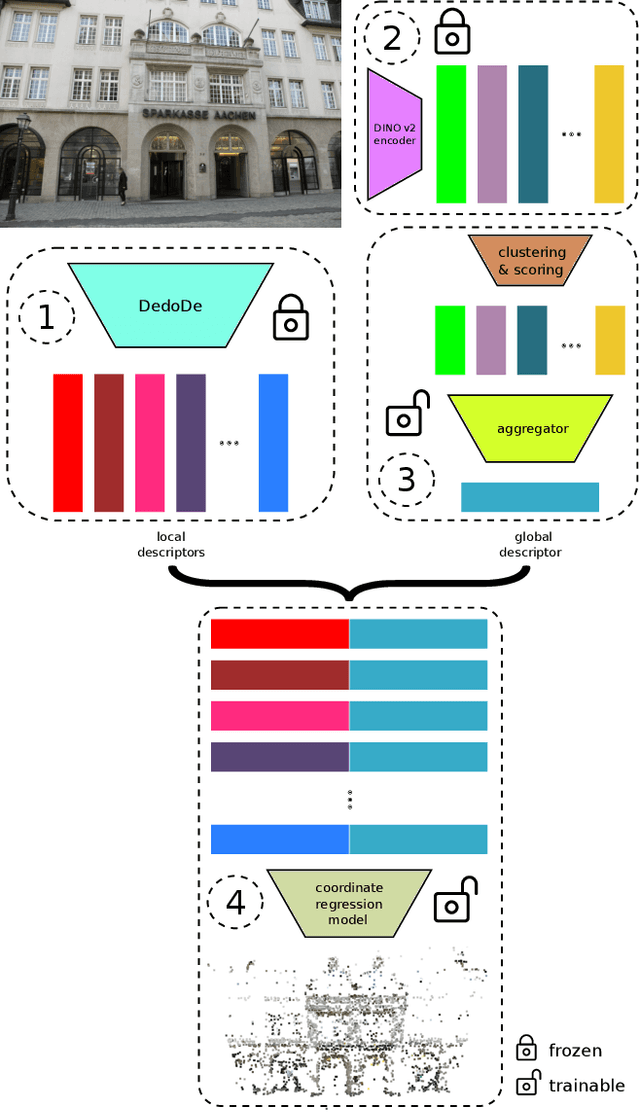
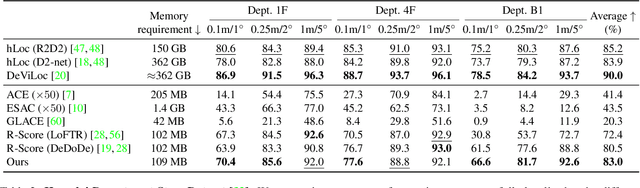
Recent learning-based visual localization methods use global descriptors to disambiguate visually similar places, but existing approaches often derive these descriptors from geometric cues alone (e.g., covisibility graphs), limiting their discriminative power and reducing robustness in the presence of noisy geometric constraints. We propose an aggregator module that learns global descriptors consistent with both geometrical structure and visual similarity, ensuring that images are close in descriptor space only when they are visually similar and spatially connected. This corrects erroneous associations caused by unreliable overlap scores. Using a batch-mining strategy based solely on the overlap scores and a modified contrastive loss, our method trains without manual place labels and generalizes across diverse environments. Experiments on challenging benchmarks show substantial localization gains in large-scale environments while preserving computational and memory efficiency. Code is available at \href{https://github.com/sontung/robust\_scr}{github.com/sontung/robust\_scr}.
Pixi: Unified Software Development and Distribution for Robotics and AI
Nov 06, 2025The reproducibility crisis in scientific computing constrains robotics research. Existing studies reveal that up to 70% of robotics algorithms cannot be reproduced by independent teams, while many others fail to reach deployment because creating shareable software environments remains prohibitively complex. These challenges stem from fragmented, multi-language, and hardware-software toolchains that lead to dependency hell. We present Pixi, a unified package-management framework that addresses these issues by capturing exact dependency states in project-level lockfiles, ensuring bit-for-bit reproducibility across platforms. Its high-performance SAT solver achieves up to 10x faster dependency resolution than comparable tools, while integration of the conda-forge and PyPI ecosystems removes the need for multiple managers. Adopted in over 5,300 projects since 2023, Pixi reduces setup times from hours to minutes and lowers technical barriers for researchers worldwide. By enabling scalable, reproducible, collaborative research infrastructure, Pixi accelerates progress in robotics and AI.
Event-LAB: Towards Standardized Evaluation of Neuromorphic Localization Methods
Sep 18, 2025Event-based localization research and datasets are a rapidly growing area of interest, with a tenfold increase in the cumulative total number of published papers on this topic over the past 10 years. Whilst the rapid expansion in the field is exciting, it brings with it an associated challenge: a growth in the variety of required code and package dependencies as well as data formats, making comparisons difficult and cumbersome for researchers to implement reliably. To address this challenge, we present Event-LAB: a new and unified framework for running several event-based localization methodologies across multiple datasets. Event-LAB is implemented using the Pixi package and dependency manager, that enables a single command-line installation and invocation for combinations of localization methods and datasets. To demonstrate the capabilities of the framework, we implement two common event-based localization pipelines: Visual Place Recognition (VPR) and Simultaneous Localization and Mapping (SLAM). We demonstrate the ability of the framework to systematically visualize and analyze the results of multiple methods and datasets, revealing key insights such as the association of parameters that control event collection counts and window sizes for frame generation to large variations in performance. The results and analysis demonstrate the importance of fairly comparing methodologies with consistent event image generation parameters. Our Event-LAB framework provides this ability for the research community, by contributing a streamlined workflow for easily setting up multiple conditions.
VSLAM-LAB: A Comprehensive Framework for Visual SLAM Methods and Datasets
Apr 06, 2025



Visual Simultaneous Localization and Mapping (VSLAM) research faces significant challenges due to fragmented toolchains, complex system configurations, and inconsistent evaluation methodologies. To address these issues, we present VSLAM-LAB, a unified framework designed to streamline the development, evaluation, and deployment of VSLAM systems. VSLAM-LAB simplifies the entire workflow by enabling seamless compilation and configuration of VSLAM algorithms, automated dataset downloading and preprocessing, and standardized experiment design, execution, and evaluation--all accessible through a single command-line interface. The framework supports a wide range of VSLAM systems and datasets, offering broad compatibility and extendability while promoting reproducibility through consistent evaluation metrics and analysis tools. By reducing implementation complexity and minimizing configuration overhead, VSLAM-LAB empowers researchers to focus on advancing VSLAM methodologies and accelerates progress toward scalable, real-world solutions. We demonstrate the ease with which user-relevant benchmarks can be created: here, we introduce difficulty-level-based categories, but one could envision environment-specific or condition-specific categories.
Image-Based Relocalization and Alignment for Long-Term Monitoring of Dynamic Underwater Environments
Mar 06, 2025



Effective monitoring of underwater ecosystems is crucial for tracking environmental changes, guiding conservation efforts, and ensuring long-term ecosystem health. However, automating underwater ecosystem management with robotic platforms remains challenging due to the complexities of underwater imagery, which pose significant difficulties for traditional visual localization methods. We propose an integrated pipeline that combines Visual Place Recognition (VPR), feature matching, and image segmentation on video-derived images. This method enables robust identification of revisited areas, estimation of rigid transformations, and downstream analysis of ecosystem changes. Furthermore, we introduce the SQUIDLE+ VPR Benchmark-the first large-scale underwater VPR benchmark designed to leverage an extensive collection of unstructured data from multiple robotic platforms, spanning time intervals from days to years. The dataset encompasses diverse trajectories, arbitrary overlap and diverse seafloor types captured under varying environmental conditions, including differences in depth, lighting, and turbidity. Our code is available at: https://github.com/bev-gorry/underloc
Look Ma, No Ground Truth! Ground-Truth-Free Tuning of Structure from Motion and Visual SLAM
Dec 02, 2024Evaluation is critical to both developing and tuning Structure from Motion (SfM) and Visual SLAM (VSLAM) systems, but is universally reliant on high-quality geometric ground truth -- a resource that is not only costly and time-intensive but, in many cases, entirely unobtainable. This dependency on ground truth restricts SfM and SLAM applications across diverse environments and limits scalability to real-world scenarios. In this work, we propose a novel ground-truth-free (GTF) evaluation methodology that eliminates the need for geometric ground truth, instead using sensitivity estimation via sampling from both original and noisy versions of input images. Our approach shows strong correlation with traditional ground-truth-based benchmarks and supports GTF hyperparameter tuning. Removing the need for ground truth opens up new opportunities to leverage a much larger number of dataset sources, and for self-supervised and online tuning, with the potential for a data-driven breakthrough analogous to what has occurred in generative AI.
FUSELOC: Fusing Global and Local Descriptors to Disambiguate 2D-3D Matching in Visual Localization
Aug 21, 2024Hierarchical methods represent state-of-the-art visual localization, optimizing search efficiency by using global descriptors to focus on relevant map regions. However, this state-of-the-art performance comes at the cost of substantial memory requirements, as all database images must be stored for feature matching. In contrast, direct 2D-3D matching algorithms require significantly less memory but suffer from lower accuracy due to the larger and more ambiguous search space. We address this ambiguity by fusing local and global descriptors using a weighted average operator within a 2D-3D search framework. This fusion rearranges the local descriptor space such that geographically nearby local descriptors are closer in the feature space according to the global descriptors. Therefore, the number of irrelevant competing descriptors decreases, specifically if they are geographically distant, thereby increasing the likelihood of correctly matching a query descriptor. We consistently improve the accuracy over local-only systems and achieve performance close to hierarchical methods while halving memory requirements. Extensive experiments using various state-of-the-art local and global descriptors across four different datasets demonstrate the effectiveness of our approach. For the first time, our approach enables direct matching algorithms to benefit from global descriptors while maintaining memory efficiency. The code for this paper will be published at \href{https://github.com/sontung/descriptor-disambiguation}{github.com/sontung/descriptor-disambiguation}.
FocusTune: Tuning Visual Localization through Focus-Guided Sampling
Nov 06, 2023We propose FocusTune, a focus-guided sampling technique to improve the performance of visual localization algorithms. FocusTune directs a scene coordinate regression model towards regions critical for 3D point triangulation by exploiting key geometric constraints. Specifically, rather than uniformly sampling points across the image for training the scene coordinate regression model, we instead re-project 3D scene coordinates onto the 2D image plane and sample within a local neighborhood of the re-projected points. While our proposed sampling strategy is generally applicable, we showcase FocusTune by integrating it with the recently introduced Accelerated Coordinate Encoding (ACE) model. Our results demonstrate that FocusTune both improves or matches state-of-the-art performance whilst keeping ACE's appealing low storage and compute requirements, for example reducing translation error from 25 to 19 and 17 to 15 cm for single and ensemble models, respectively, on the Cambridge Landmarks dataset. This combination of high performance and low compute and storage requirements is particularly promising for applications in areas like mobile robotics and augmented reality. We made our code available at \url{https://github.com/sontung/focus-tune}.
Motion-Bias-Free Feature-Based SLAM
Sep 13, 2023For SLAM to be safely deployed in unstructured real world environments, it must possess several key properties that are not encompassed by conventional benchmarks. In this paper we show that SLAM commutativity, that is, consistency in trajectory estimates on forward and reverse traverses of the same route, is a significant issue for the state of the art. Current pipelines show a significant bias between forward and reverse directions of travel, that is in addition inconsistent regarding which direction of travel exhibits better performance. In this paper we propose several contributions to feature-based SLAM pipelines that remedies the motion bias problem. In a comprehensive evaluation across four datasets, we show that our contributions implemented in ORB-SLAM2 substantially reduce the bias between forward and backward motion and additionally improve the aggregated trajectory error. Removing the SLAM motion bias has significant relevance for the wide range of robotics and computer vision applications where performance consistency is important.