 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Scene Coordinate Regression via Geometrically-Consistent Global Descriptors
Dec 19, 2025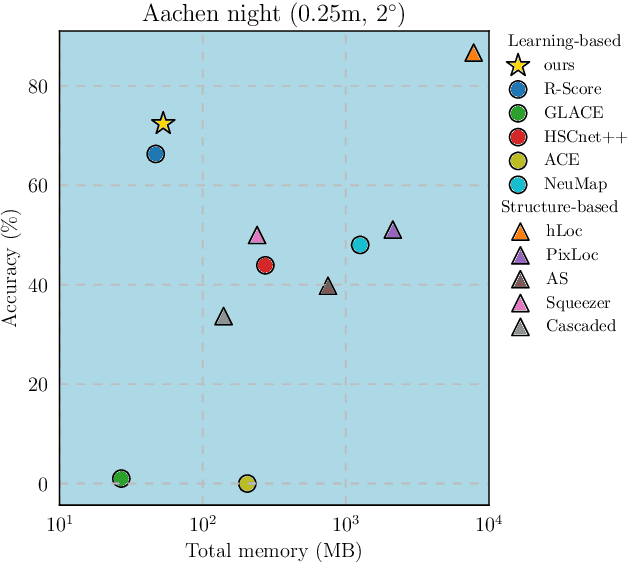
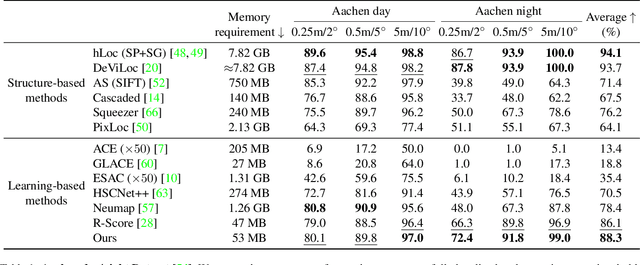
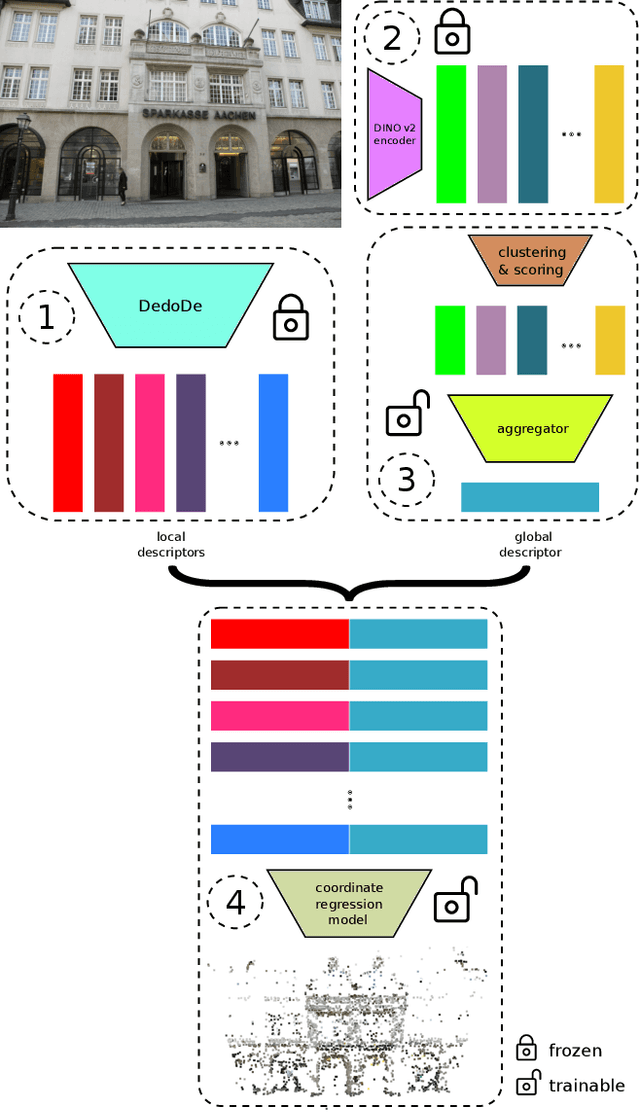
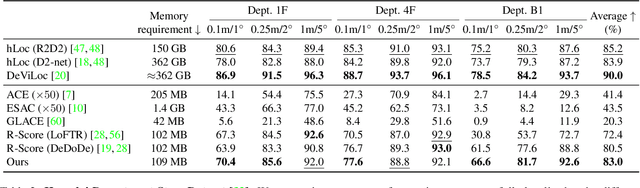
Recent learning-based visual localization methods use global descriptors to disambiguate visually similar places, but existing approaches often derive these descriptors from geometric cues alone (e.g., covisibility graphs), limiting their discriminative power and reducing robustness in the presence of noisy geometric constraints. We propose an aggregator module that learns global descriptors consistent with both geometrical structure and visual similarity, ensuring that images are close in descriptor space only when they are visually similar and spatially connected. This corrects erroneous associations caused by unreliable overlap scores. Using a batch-mining strategy based solely on the overlap scores and a modified contrastive loss, our method trains without manual place labels and generalizes across diverse environments. Experiments on challenging benchmarks show substantial localization gains in large-scale environments while preserving computational and memory efficiency. Code is available at \href{https://github.com/sontung/robust\_scr}{github.com/sontung/robust\_scr}.
FUSELOC: Fusing Global and Local Descriptors to Disambiguate 2D-3D Matching in Visual Localization
Aug 21, 2024Hierarchical methods represent state-of-the-art visual localization, optimizing search efficiency by using global descriptors to focus on relevant map regions. However, this state-of-the-art performance comes at the cost of substantial memory requirements, as all database images must be stored for feature matching. In contrast, direct 2D-3D matching algorithms require significantly less memory but suffer from lower accuracy due to the larger and more ambiguous search space. We address this ambiguity by fusing local and global descriptors using a weighted average operator within a 2D-3D search framework. This fusion rearranges the local descriptor space such that geographically nearby local descriptors are closer in the feature space according to the global descriptors. Therefore, the number of irrelevant competing descriptors decreases, specifically if they are geographically distant, thereby increasing the likelihood of correctly matching a query descriptor. We consistently improve the accuracy over local-only systems and achieve performance close to hierarchical methods while halving memory requirements. Extensive experiments using various state-of-the-art local and global descriptors across four different datasets demonstrate the effectiveness of our approach. For the first time, our approach enables direct matching algorithms to benefit from global descriptors while maintaining memory efficiency. The code for this paper will be published at \href{https://github.com/sontung/descriptor-disambiguation}{github.com/sontung/descriptor-disambiguation}.
FocusTune: Tuning Visual Localization through Focus-Guided Sampling
Nov 06, 2023We propose FocusTune, a focus-guided sampling technique to improve the performance of visual localization algorithms. FocusTune directs a scene coordinate regression model towards regions critical for 3D point triangulation by exploiting key geometric constraints. Specifically, rather than uniformly sampling points across the image for training the scene coordinate regression model, we instead re-project 3D scene coordinates onto the 2D image plane and sample within a local neighborhood of the re-projected points. While our proposed sampling strategy is generally applicable, we showcase FocusTune by integrating it with the recently introduced Accelerated Coordinate Encoding (ACE) model. Our results demonstrate that FocusTune both improves or matches state-of-the-art performance whilst keeping ACE's appealing low storage and compute requirements, for example reducing translation error from 25 to 19 and 17 to 15 cm for single and ensemble models, respectively, on the Cambridge Landmarks dataset. This combination of high performance and low compute and storage requirements is particularly promising for applications in areas like mobile robotics and augmented reality. We made our code available at \url{https://github.com/sontung/focus-tune}.