 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPNext++: What's Next for Tracking Any Point (TAP)?
Apr 12, 2026Tracking-Any-Point (TAP) models aim to track any point through a video which is a crucial task in AR/XR and robotics applications. The recently introduced TAPNext approach proposes an end-to-end, recurrent transformer architecture to track points frame-by-frame in a purely online fashion -- demonstrating competitive performance at minimal latency. However, we show that TAPNext struggles with longer video sequences and also frequently fails to re-detect query points that reappear after being occluded or leaving the frame. In this work, we present TAPNext++, a model that tracks points in sequences that are orders of magnitude longer while preserving the low memory and compute footprint of the architecture. We train the recurrent video transformer using several data-driven solutions, including training on long 1024-frame sequences enabled by sequence parallelism techniques. We highlight that re-detection performance is a blind spot in the current literature and introduce a new metric, Re-Detection Average Jaccard ($AJ_{RD}$), to explicitly evaluate tracking on re-appearing points. To improve re-detection of points, we introduce tailored geometric augmentations, such as periodic roll that simulates point re-entries, and supervising occluded points. We demonstrate that recurrent transformers can be substantially improved for point tracking and set a new state-of-the-art on multiple benchmarks. Model and code can be found at https://tap-next-plus-plus.github.io.
SPIRIT: Perceptive Shared Autonomy for Robust Robotic Manipulation under Deep Learning Uncertainty
Mar 05, 2026Deep learning (DL) has enabled impressive advances in robotic perception, yet its limited robustness and lack of interpretability hinder reliable deployment in safety critical applications. We propose a concept termed perceptive shared autonomy, in which uncertainty estimates from DL based perception are used to regulate the level of autonomy. Specifically, when the robot's perception is confident, semi-autonomous manipulation is enabled to improve performance; when uncertainty increases, control transitions to haptic teleoperation for maintaining robustness. In this way, high-performing but uninterpretable DL methods can be integrated safely into robotic systems. A key technical enabler is an uncertainty aware DL based point cloud registration approach based on the so called Neural Tangent Kernels (NTK). We evaluate perceptive shared autonomy on challenging aerial manipulation tasks through a user study of 15 participants and realization of mock-up industrial scenarios, demonstrating reliable robotic manipulation despite failures in DL based perception. The resulting system, named SPIRIT, improves both manipulation performance and system reliability. SPIRIT was selected as a finalist of a major industrial innovation award.
Tracing Back Error Sources to Explain and Mitigate Pose Estimation Failures
Mar 03, 2026Robust estimation of object poses in robotic manipulation is often addressed using foundational general estimators, that aim to handle diverse error sources naively within a single model. Still, they struggle due to environmental uncertainties, while requiring long inference times and heavy computation. In contrast, we propose a modular, uncertainty-aware framework that attributes pose estimation errors to specific error sources and applies targeted mitigation strategies only when necessary. Instantiated with Iterative Closest Point (ICP) as a simple and lightweight pose estimator, we leverage our framework for real-world robotic grasping tasks. By decomposing pose estimation into failure detection, error attribution, and targeted recovery, we significantly improve the robustness of ICP and achieve competitive performance compared to foundation models, while relying on a substantially simpler and faster pose estimator.
Markerless Robot Detection and 6D Pose Estimation for Multi-Agent SLAM
Feb 18, 2026The capability of multi-robot SLAM approaches to merge localization history and maps from different observers is often challenged by the difficulty in establishing data association. Loop closure detection between perceptual inputs of different robotic agents is easily compromised in the context of perceptual aliasing, or when perspectives differ significantly. For this reason, direct mutual observation among robots is a powerful way to connect partial SLAM graphs, but often relies on the presence of calibrated arrays of fiducial markers (e.g., AprilTag arrays), which severely limits the range of observations and frequently fails under sharp lighting conditions, e.g., reflections or overexposure. In this work, we propose a novel solution to this problem leveraging recent advances in Deep-Learning-based 6D pose estimation. We feature markerless pose estimation as part of a decentralized multi-robot SLAM system and demonstrate the benefit to the relative localization accuracy among the robotic team. The solution is validated experimentally on data recorded in a test field campaign on a planetary analogous environment.
Finding NeMO: A Geometry-Aware Representation of Template Views for Few-Shot Perception
Feb 04, 2026We present Neural Memory Object (NeMO), a novel object-centric representation that can be used to detect, segment and estimate the 6DoF pose of objects unseen during training using RGB images. Our method consists of an encoder that requires only a few RGB template views depicting an object to generate a sparse object-like point cloud using a learned UDF containing semantic and geometric information. Next, a decoder takes the object encoding together with a query image to generate a variety of dense predictions. Through extensive experiments, we show that our method can be used for few-shot object perception without requiring any camera-specific parameters or retraining on target data. Our proposed concept of outsourcing object information in a NeMO and using a single network for multiple perception tasks enhances interaction with novel objects, improving scalability and efficiency by enabling quick object onboarding without retraining or extensive pre-processing. We report competitive and state-of-the-art results on various datasets and perception tasks of the BOP benchmark, demonstrating the versatility of our approach. https://github.com/DLR-RM/nemo
The S3LI Vulcano Dataset: A Dataset for Multi-Modal SLAM in Unstructured Planetary Environments
Jan 27, 2026We release the S3LI Vulcano dataset, a multi-modal dataset towards development and benchmarking of Simultaneous Localization and Mapping (SLAM) and place recognition algorithms that rely on visual and LiDAR modalities. Several sequences are recorded on the volcanic island of Vulcano, from the Aeolian Islands in Sicily, Italy. The sequences provide users with data from a variety of environments, textures and terrains, including basaltic or iron-rich rocks, geological formations from old lava channels, as well as dry vegetation and water. The data (rmc.dlr.de/s3li_dataset) is accompanied by an open source toolkit (github.com/DLR-RM/s3li-toolkit) providing tools for generating ground truth poses as well as preparation of labelled samples for place recognition tasks.
Evaluating Latent Generative Paradigms for High-Fidelity 3D Shape Completion from a Single Depth Image
Nov 14, 2025While generative models have seen significant adoption across a wide range of data modalities, including 3D data, a consensus on which model is best suited for which task has yet to be reached. Further, conditional information such as text and images to steer the generation process are frequently employed, whereas others, like partial 3D data, have not been thoroughly evaluated. In this work, we compare two of the most promising generative models--Denoising Diffusion Probabilistic Models and Autoregressive Causal Transformers--which we adapt for the tasks of generative shape modeling and completion. We conduct a thorough quantitative evaluation and comparison of both tasks, including a baseline discriminative model and an extensive ablation study. Our results show that (1) the diffusion model with continuous latents outperforms both the discriminative model and the autoregressive approach and delivers state-of-the-art performance on multi-modal shape completion from a single, noisy depth image under realistic conditions and (2) when compared on the same discrete latent space, the autoregressive model can match or exceed diffusion performance on these tasks.
Multi-modal Loop Closure Detection with Foundation Models in Severely Unstructured Environments
Nov 07, 2025
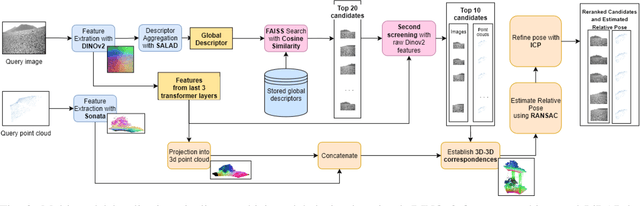

Robust loop closure detection is a critical component of Simultaneous Localization and Mapping (SLAM) algorithms in GNSS-denied environments, such as in the context of planetary exploration. In these settings, visual place recognition often fails due to aliasing and weak textures, while LiDAR-based methods suffer from sparsity and ambiguity. This paper presents MPRF, a multimodal pipeline that leverages transformer-based foundation models for both vision and LiDAR modalities to achieve robust loop closure in severely unstructured environments. Unlike prior work limited to retrieval, MPRF integrates a two-stage visual retrieval strategy with explicit 6-DoF pose estimation, combining DINOv2 features with SALAD aggregation for efficient candidate screening and SONATA-based LiDAR descriptors for geometric verification. Experiments on the S3LI dataset and S3LI Vulcano dataset show that MPRF outperforms state-of-the-art retrieval methods in precision while enhancing pose estimation robustness in low-texture regions. By providing interpretable correspondences suitable for SLAM back-ends, MPRF achieves a favorable trade-off between accuracy, efficiency, and reliability, demonstrating the potential of foundation models to unify place recognition and pose estimation. Code and models will be released at github.com/DLR-RM/MPRF.
Conditional Latent Diffusion Models for Zero-Shot Instance Segmentation
Aug 06, 2025This paper presents OC-DiT, a novel class of diffusion models designed for object-centric prediction, and applies it to zero-shot instance segmentation. We propose a conditional latent diffusion framework that generates instance masks by conditioning the generative process on object templates and image features within the diffusion model's latent space. This allows our model to effectively disentangle object instances through the diffusion process, which is guided by visual object descriptors and localized image cues. Specifically, we introduce two model variants: a coarse model for generating initial object instance proposals, and a refinement model that refines all proposals in parallel. We train these models on a newly created, large-scale synthetic dataset comprising thousands of high-quality object meshes. Remarkably, our model achieves state-of-the-art performance on multiple challenging real-world benchmarks, without requiring any retraining on target data. Through comprehensive ablation studies, we demonstrate the potential of diffusion models for instance segmentation tasks.
Towards Explaining Uncertainty Estimates in Point Cloud Registration
Dec 29, 2024Iterative Closest Point (ICP) is a commonly used algorithm to estimate transformation between two point clouds. The key idea of this work is to leverage recent advances in explainable AI for probabilistic ICP methods that provide uncertainty estimates. Concretely, we propose a method that can explain why a probabilistic ICP method produced a particular output. Our method is based on kernel SHAP (SHapley Additive exPlanations). With this, we assign an importance value to common sources of uncertainty in ICP such as sensor noise, occlusion, and ambiguous environments. The results of the experiment show that this explanation method can reasonably explain the uncertainty sources, providing a step towards robots that know when and why they failed in a human interpretable manner