 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLensDFF: Language-enhanced Sparse Feature Distillation for Efficient Few-Shot Dexterous Manipulation
Mar 05, 2025Learning dexterous manipulation from few-shot demonstrations is a significant yet challenging problem for advanced, human-like robotic systems. Dense distilled feature fields have addressed this challenge by distilling rich semantic features from 2D visual foundation models into the 3D domain. However, their reliance on neural rendering models such as Neural Radiance Fields (NeRF) or Gaussian Splatting results in high computational costs. In contrast, previous approaches based on sparse feature fields either suffer from inefficiencies due to multi-view dependencies and extensive training or lack sufficient grasp dexterity. To overcome these limitations, we propose Language-ENhanced Sparse Distilled Feature Field (LensDFF), which efficiently distills view-consistent 2D features onto 3D points using our novel language-enhanced feature fusion strategy, thereby enabling single-view few-shot generalization. Based on LensDFF, we further introduce a few-shot dexterous manipulation framework that integrates grasp primitives into the demonstrations to generate stable and highly dexterous grasps. Moreover, we present a real2sim grasp evaluation pipeline for efficient grasp assessment and hyperparameter tuning. Through extensive simulation experiments based on the real2sim pipeline and real-world experiments, our approach achieves competitive grasping performance, outperforming state-of-the-art approaches.
DexGANGrasp: Dexterous Generative Adversarial Grasping Synthesis for Task-Oriented Manipulation
Jul 24, 2024We introduce DexGanGrasp, a dexterous grasping synthesis method that generates and evaluates grasps with single view in real time. DexGanGrasp comprises a Conditional Generative Adversarial Networks (cGANs)-based DexGenerator to generate dexterous grasps and a discriminator-like DexEvalautor to assess the stability of these grasps. Extensive simulation and real-world expriments showcases the effectiveness of our proposed method, outperforming the baseline FFHNet with an 18.57% higher success rate in real-world evaluation. We further extend DexGanGrasp to DexAfford-Prompt, an open-vocabulary affordance grounding pipeline for dexterous grasping leveraging Multimodal Large Language Models (MLLMs) and Vision Language Models (VLMs), to achieve task-oriented grasping with successful real-world deployments.
FFHFlow: A Flow-based Variational Approach for Multi-fingered Grasp Synthesis in Real Time
Jul 21, 2024Synthesizing diverse and accurate grasps with multi-fingered hands is an important yet challenging task in robotics. Previous efforts focusing on generative modeling have fallen short of precisely capturing the multi-modal, high-dimensional grasp distribution. To address this, we propose exploiting a special kind of Deep Generative Model (DGM) based on Normalizing Flows (NFs), an expressive model for learning complex probability distributions. Specifically, we first observed an encouraging improvement in diversity by directly applying a single conditional NFs (cNFs), dubbed FFHFlow-cnf, to learn a grasp distribution conditioned on the incomplete point cloud. However, we also recognized limited performance gains due to restricted expressivity in the latent space. This motivated us to develop a novel flow-based d Deep Latent Variable Model (DLVM), namely FFHFlow-lvm, which facilitates more reasonable latent features, leading to both diverse and accurate grasp synthesis for unseen objects. Unlike Variational Autoencoders (VAEs), the proposed DLVM counteracts typical pitfalls such as mode collapse and mis-specified priors by leveraging two cNFs for the prior and likelihood distributions, which are usually restricted to being isotropic Gaussian. Comprehensive experiments in simulation and real-robot scenarios demonstrate that our method generates more accurate and diverse grasps than the VAE baselines. Additionally, a run-time comparison is conducted to reveal its high potential for real-time applications.
Language-Guided Object-Centric Diffusion Policy for Collision-Aware Robotic Manipulation
Jun 29, 2024Learning from demonstrations faces challenges in generalizing beyond the training data and is fragile even to slight visual variations. To tackle this problem, we introduce Lan-o3dp, a language guided object centric diffusion policy that takes 3d representation of task relevant objects as conditional input and can be guided by cost function for safety constraints at inference time. Lan-o3dp enables strong generalization in various aspects, such as background changes, visual ambiguity and can avoid novel obstacles that are unseen during the demonstration process. Specifically, We first train a diffusion policy conditioned on point clouds of target objects and then harness a large language model to decompose the user instruction into task related units consisting of target objects and obstacles, which can be used as visual observation for the policy network or converted to a cost function, guiding the generation of trajectory towards collision free region at test time. Our proposed method shows training efficiency and higher success rates compared with the baselines in simulation experiments. In real world experiments, our method exhibits strong generalization performance towards unseen instances, cluttered scenes, scenes of multiple similar objects and demonstrates training free capability of obstacle avoidance.
Evaluating Uncertainty-based Failure Detection for Closed-Loop LLM Planners
Jun 01, 2024Recently, Large Language Models (LLMs) have witnessed remarkable performance as zero-shot task planners for robotic manipulation tasks. However, the open-loop nature of previous works makes LLM-based planning error-prone and fragile. On the other hand, failure detection approaches for closed-loop planning are often limited by task-specific heuristics or following an unrealistic assumption that the prediction is trustworthy all the time. As a general-purpose reasoning machine, LLMs or Multimodal Large Language Models (MLLMs) are promising for detecting failures. However, However, the appropriateness of the aforementioned assumption diminishes due to the notorious hullucination problem. In this work, we attempt to mitigate these issues by introducing a framework for closed-loop LLM-based planning called KnowLoop, backed by an uncertainty-based MLLMs failure detector, which is agnostic to any used MLLMs or LLMs. Specifically, we evaluate three different ways for quantifying the uncertainty of MLLMs, namely token probability, entropy, and self-explained confidence as primary metrics based on three carefully designed representative prompting strategies. With a self-collected dataset including various manipulation tasks and an LLM-based robot system, our experiments demonstrate that token probability and entropy are more reflective compared to self-explained confidence. By setting an appropriate threshold to filter out uncertain predictions and seek human help actively, the accuracy of failure detection can be significantly enhanced. This improvement boosts the effectiveness of closed-loop planning and the overall success rate of tasks.
Topology-Matching Normalizing Flows for Out-of-Distribution Detection in Robot Learning
Nov 11, 2023



To facilitate reliable deployments of autonomous robots in the real world, Out-of-Distribution (OOD) detection capabilities are often required. A powerful approach for OOD detection is based on density estimation with Normalizing Flows (NFs). However, we find that prior work with NFs attempts to match the complex target distribution topologically with naive base distributions leading to adverse implications. In this work, we circumvent this topological mismatch using an expressive class-conditional base distribution trained with an information-theoretic objective to match the required topology. The proposed method enjoys the merits of wide compatibility with existing learned models without any performance degradation and minimum computation overhead while enhancing OOD detection capabilities. We demonstrate superior results in density estimation and 2D object detection benchmarks in comparison with extensive baselines. Moreover, we showcase the applicability of the method with a real-robot deployment.
Density-based Feasibility Learning with Normalizing Flows for Introspective Robotic Assembly
Jul 06, 2023Machine Learning (ML) models in Robotic Assembly Sequence Planning (RASP) need to be introspective on the predicted solutions, i.e. whether they are feasible or not, to circumvent potential efficiency degradation. Previous works need both feasible and infeasible examples during training. However, the infeasible ones are hard to collect sufficiently when re-training is required for swift adaptation to new product variants. In this work, we propose a density-based feasibility learning method that requires only feasible examples. Concretely, we formulate the feasibility learning problem as Out-of-Distribution (OOD) detection with Normalizing Flows (NF), which are powerful generative models for estimating complex probability distributions. Empirically, the proposed method is demonstrated on robotic assembly use cases and outperforms other single-class baselines in detecting infeasible assemblies. We further investigate the internal working mechanism of our method and show that a large memory saving can be obtained based on an advanced variant of NF.
Efficient and Feasible Robotic Assembly Sequence Planning via Graph Representation Learning
Mar 21, 2023



Automatic Robotic Assembly Sequence Planning (RASP) can significantly improve productivity and resilience in modern manufacturing along with the growing need for greater product customization. One of the main challenges in realizing such automation resides in efficiently finding solutions from a growing number of potential sequences for increasingly complex assemblies. Besides, costly feasibility checks are always required for the robotic system. To address this, we propose a holistic graphical approach including a graph representation called Assembly Graph for product assemblies and a policy architecture, Graph Assembly Processing Network, dubbed GRACE for assembly sequence generation. Secondly, we use GRACE to extract meaningful information from the graph input and predict assembly sequences in a step-by-step manner. In experiments, we show that our approach can predict feasible assembly sequences across product variants of aluminum profiles based on data collected in simulation of a dual-armed robotic system. We further demonstrate that our method is capable of detecting infeasible assemblies, substantially alleviating the undesirable impacts from false predictions, and hence facilitating real-world deployment soon. Code and training data will be open-sourced.
Virtual Reality via Object Poses and Active Learning: Realizing Telepresence Robots with Aerial Manipulation Capabilities
Oct 18, 2022

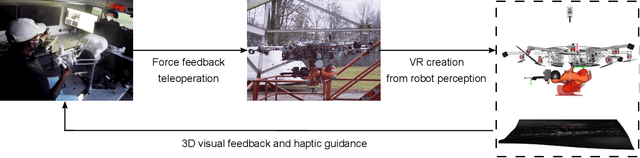
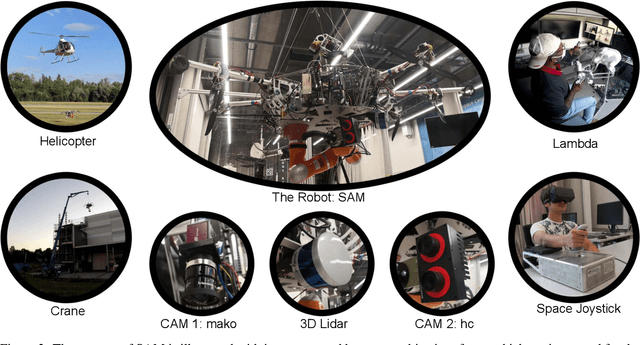
This article presents a novel telepresence system for advancing aerial manipulation in dynamic and unstructured environments. The proposed system not only features a haptic device, but also a virtual reality (VR) interface that provides real-time 3D displays of the robot's workspace as well as a haptic guidance to its remotely located operator. To realize this, multiple sensors namely a LiDAR, cameras and IMUs are utilized. For processing of the acquired sensory data, pose estimation pipelines are devised for industrial objects of both known and unknown geometries. We further propose an active learning pipeline in order to increase the sample efficiency of a pipeline component that relies on Deep Neural Networks (DNNs) based object detection. All these algorithms jointly address various challenges encountered during the execution of perception tasks in industrial scenarios. In the experiments, exhaustive ablation studies are provided to validate the proposed pipelines. Methodologically, these results commonly suggest how an awareness of the algorithms' own failures and uncertainty ("introspection") can be used tackle the encountered problems. Moreover, outdoor experiments are conducted to evaluate the effectiveness of the overall system in enhancing aerial manipulation capabilities. In particular, with flight campaigns over days and nights, from spring to winter, and with different users and locations, we demonstrate over 70 robust executions of pick-and-place, force application and peg-in-hole tasks with the DLR cable-Suspended Aerial Manipulator (SAM). As a result, we show the viability of the proposed system in future industrial applications.
Bridging the Last Mile in Sim-to-Real Robot Perception via Bayesian Active Learning
Sep 29, 2021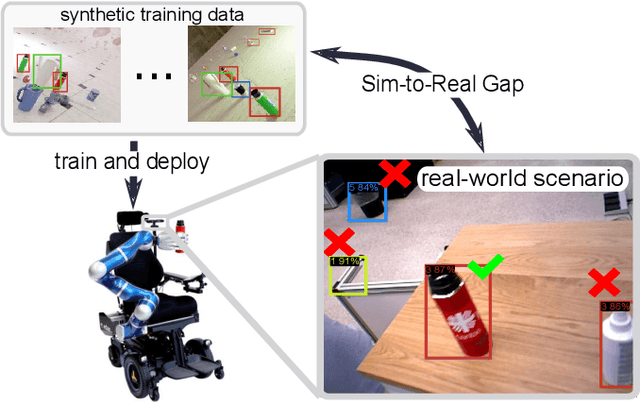

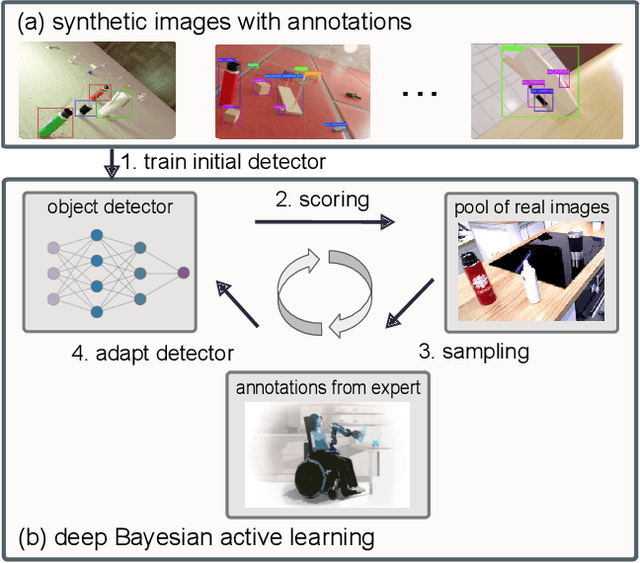
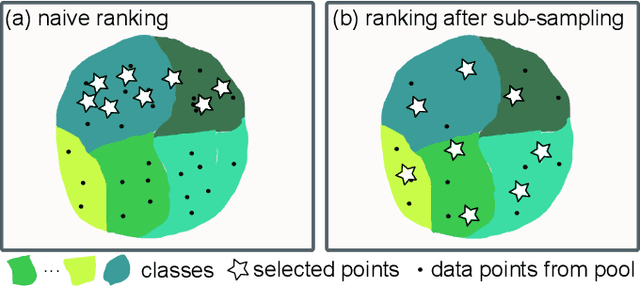
Learning from synthetic data is popular in a variety of robotic vision tasks such as object detection, because a large amount of data can be generated without annotations by humans. However, when relying only on synthetic data,we encounter the well-known problem of the simulation-to-reality (Sim-to-Real) gap, which is hard to resolve completely in practice. For such cases, real human-annotated data is necessary to bridge this gap, and in our work we focus on howto acquire this data efficiently. Therefore, we propose a Sim-to-Real pipeline that relies on deep Bayesian active learning and aims to minimize the manual annotation efforts. We devise a learning paradigm that autonomously selects the data that is considered useful for the human expert to annotate. To achieve this, a Bayesian Neural Network (BNN) object detector providing reliable uncertain estimates is adapted to infer the informativeness of the unlabeled data, in order to perform active learning. In our experiments on two object detection data sets, we show that the labeling effort required to bridge the reality gap can be reduced to a small amount. Furthermore, we demonstrate the practical effectiveness of this idea in a grasping task on an assistive robot.