 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Latent Generative Paradigms for High-Fidelity 3D Shape Completion from a Single Depth Image
Nov 14, 2025While generative models have seen significant adoption across a wide range of data modalities, including 3D data, a consensus on which model is best suited for which task has yet to be reached. Further, conditional information such as text and images to steer the generation process are frequently employed, whereas others, like partial 3D data, have not been thoroughly evaluated. In this work, we compare two of the most promising generative models--Denoising Diffusion Probabilistic Models and Autoregressive Causal Transformers--which we adapt for the tasks of generative shape modeling and completion. We conduct a thorough quantitative evaluation and comparison of both tasks, including a baseline discriminative model and an extensive ablation study. Our results show that (1) the diffusion model with continuous latents outperforms both the discriminative model and the autoregressive approach and delivers state-of-the-art performance on multi-modal shape completion from a single, noisy depth image under realistic conditions and (2) when compared on the same discrete latent space, the autoregressive model can match or exceed diffusion performance on these tasks.
Unknown Object Grasping for Assistive Robotics
Apr 23, 2024
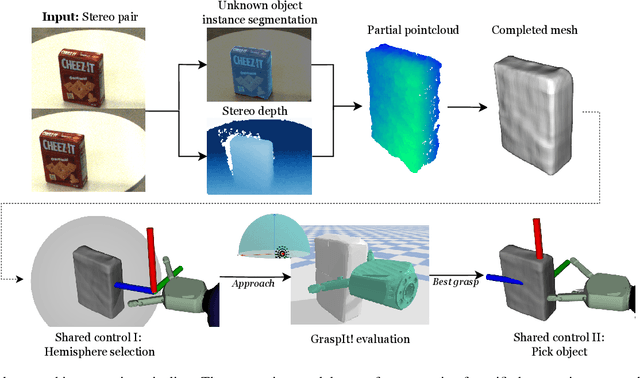
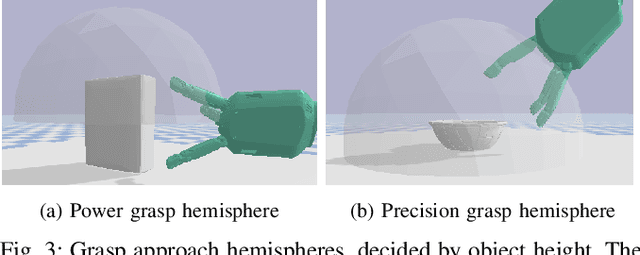
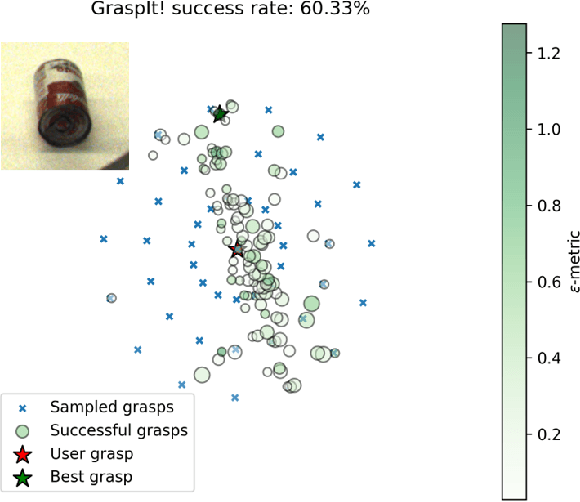
We propose a novel pipeline for unknown object grasping in shared robotic autonomy scenarios. State-of-the-art methods for fully autonomous scenarios are typically learning-based approaches optimised for a specific end-effector, that generate grasp poses directly from sensor input. In the domain of assistive robotics, we seek instead to utilise the user's cognitive abilities for enhanced satisfaction, grasping performance, and alignment with their high level task-specific goals. Given a pair of stereo images, we perform unknown object instance segmentation and generate a 3D reconstruction of the object of interest. In shared control, the user then guides the robot end-effector across a virtual hemisphere centered around the object to their desired approach direction. A physics-based grasp planner finds the most stable local grasp on the reconstruction, and finally the user is guided by shared control to this grasp. In experiments on the DLR EDAN platform, we report a grasp success rate of 87% for 10 unknown objects, and demonstrate the method's capability to grasp objects in structured clutter and from shelves.
Combining Shape Completion and Grasp Prediction for Fast and Versatile Grasping with a Multi-Fingered Hand
Oct 31, 2023
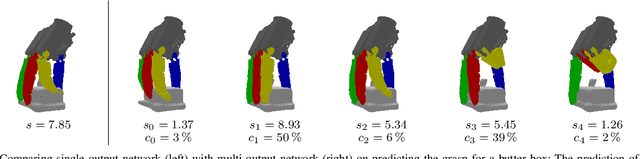
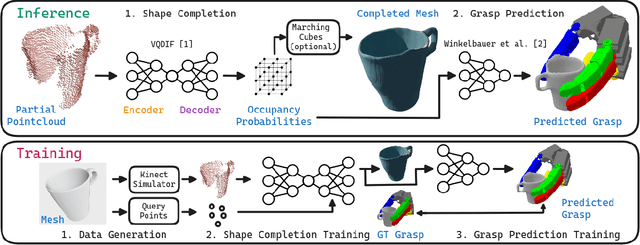

Grasping objects with limited or no prior knowledge about them is a highly relevant skill in assistive robotics. Still, in this general setting, it has remained an open problem, especially when it comes to only partial observability and versatile grasping with multi-fingered hands. We present a novel, fast, and high fidelity deep learning pipeline consisting of a shape completion module that is based on a single depth image, and followed by a grasp predictor that is based on the predicted object shape. The shape completion network is based on VQDIF and predicts spatial occupancy values at arbitrary query points. As grasp predictor, we use our two-stage architecture that first generates hand poses using an autoregressive model and then regresses finger joint configurations per pose. Critical factors turn out to be sufficient data realism and augmentation, as well as special attention to difficult cases during training. Experiments on a physical robot platform demonstrate successful grasping of a wide range of household objects based on a depth image from a single viewpoint. The whole pipeline is fast, taking only about 1 s for completing the object's shape (0.7 s) and generating 1000 grasps (0.3 s).
Shape Completion with Prediction of Uncertain Regions
Aug 01, 2023



Shape completion, i.e., predicting the complete geometry of an object from a partial observation, is highly relevant for several downstream tasks, most notably robotic manipulation. When basing planning or prediction of real grasps on object shape reconstruction, an indication of severe geometric uncertainty is indispensable. In particular, there can be an irreducible uncertainty in extended regions about the presence of entire object parts when given ambiguous object views. To treat this important case, we propose two novel methods for predicting such uncertain regions as straightforward extensions of any method for predicting local spatial occupancy, one through postprocessing occupancy scores, the other through direct prediction of an uncertainty indicator. We compare these methods together with two known approaches to probabilistic shape completion. Moreover, we generate a dataset, derived from ShapeNet, of realistically rendered depth images of object views with ground-truth annotations for the uncertain regions. We train on this dataset and test each method in shape completion and prediction of uncertain regions for known and novel object instances and on synthetic and real data. While direct uncertainty prediction is by far the most accurate in the segmentation of uncertain regions, both novel methods outperform the two baselines in shape completion and uncertain region prediction, and avoiding the predicted uncertain regions increases the quality of grasps for all tested methods. Web: https://github.com/DLR-RM/shape-completion
Virtual Reality via Object Poses and Active Learning: Realizing Telepresence Robots with Aerial Manipulation Capabilities
Oct 18, 2022

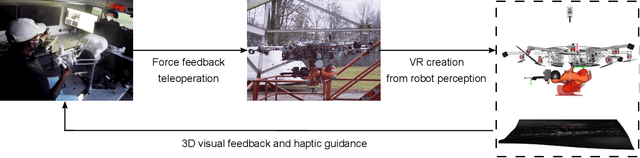
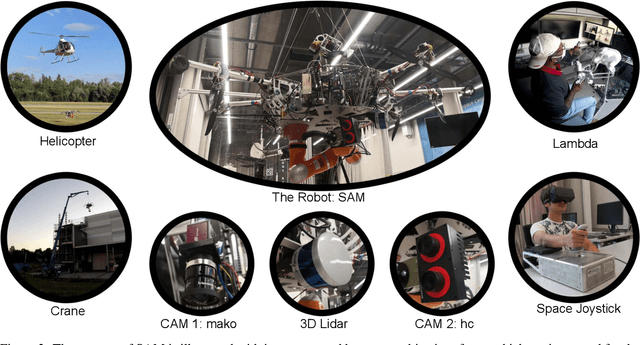
This article presents a novel telepresence system for advancing aerial manipulation in dynamic and unstructured environments. The proposed system not only features a haptic device, but also a virtual reality (VR) interface that provides real-time 3D displays of the robot's workspace as well as a haptic guidance to its remotely located operator. To realize this, multiple sensors namely a LiDAR, cameras and IMUs are utilized. For processing of the acquired sensory data, pose estimation pipelines are devised for industrial objects of both known and unknown geometries. We further propose an active learning pipeline in order to increase the sample efficiency of a pipeline component that relies on Deep Neural Networks (DNNs) based object detection. All these algorithms jointly address various challenges encountered during the execution of perception tasks in industrial scenarios. In the experiments, exhaustive ablation studies are provided to validate the proposed pipelines. Methodologically, these results commonly suggest how an awareness of the algorithms' own failures and uncertainty ("introspection") can be used tackle the encountered problems. Moreover, outdoor experiments are conducted to evaluate the effectiveness of the overall system in enhancing aerial manipulation capabilities. In particular, with flight campaigns over days and nights, from spring to winter, and with different users and locations, we demonstrate over 70 robust executions of pick-and-place, force application and peg-in-hole tasks with the DLR cable-Suspended Aerial Manipulator (SAM). As a result, we show the viability of the proposed system in future industrial applications.
Trust Your Robots! Predictive Uncertainty Estimation of Neural Networks with Sparse Gaussian Processes
Sep 21, 2021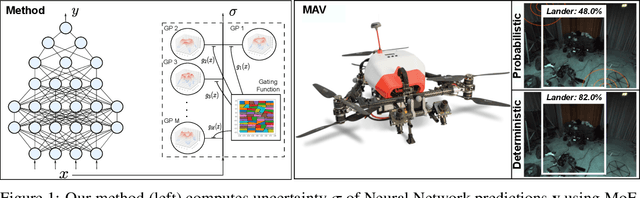
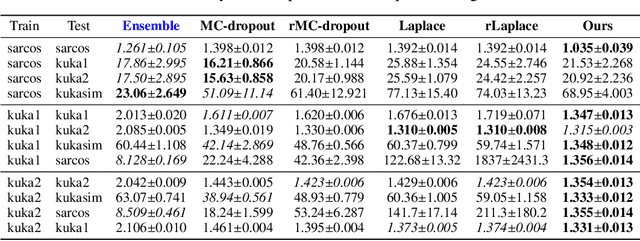
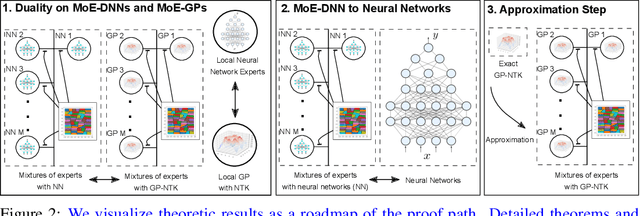
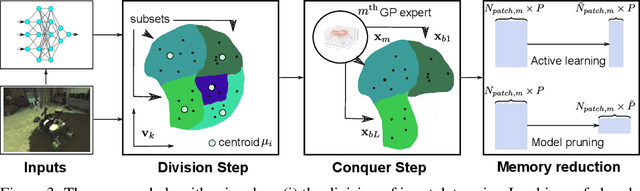
This paper presents a probabilistic framework to obtain both reliable and fast uncertainty estimates for predictions with Deep Neural Networks (DNNs). Our main contribution is a practical and principled combination of DNNs with sparse Gaussian Processes (GPs). We prove theoretically that DNNs can be seen as a special case of sparse GPs, namely mixtures of GP experts (MoE-GP), and we devise a learning algorithm that brings the derived theory into practice. In experiments from two different robotic tasks -- inverse dynamics of a manipulator and object detection on a micro-aerial vehicle (MAV) -- we show the effectiveness of our approach in terms of predictive uncertainty, improved scalability, and run-time efficiency on a Jetson TX2. We thus argue that our approach can pave the way towards reliable and fast robot learning systems with uncertainty awareness.
A Survey of Uncertainty in Deep Neural Networks
Jul 07, 2021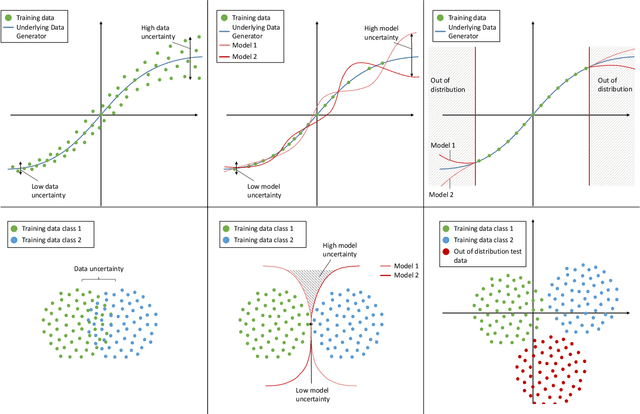
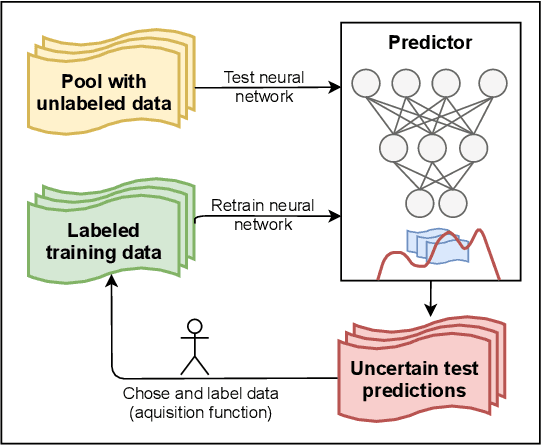
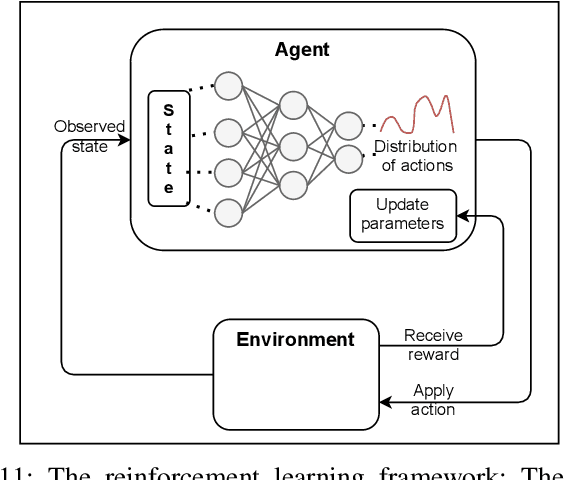
Due to their increasing spread, confidence in neural network predictions became more and more important. However, basic neural networks do not deliver certainty estimates or suffer from over or under confidence. Many researchers have been working on understanding and quantifying uncertainty in a neural network's prediction. As a result, different types and sources of uncertainty have been identified and a variety of approaches to measure and quantify uncertainty in neural networks have been proposed. This work gives a comprehensive overview of uncertainty estimation in neural networks, reviews recent advances in the field, highlights current challenges, and identifies potential research opportunities. It is intended to give anyone interested in uncertainty estimation in neural networks a broad overview and introduction, without presupposing prior knowledge in this field. A comprehensive introduction to the most crucial sources of uncertainty is given and their separation into reducible model uncertainty and not reducible data uncertainty is presented. The modeling of these uncertainties based on deterministic neural networks, Bayesian neural networks, ensemble of neural networks, and test-time data augmentation approaches is introduced and different branches of these fields as well as the latest developments are discussed. For a practical application, we discuss different measures of uncertainty, approaches for the calibration of neural networks and give an overview of existing baselines and implementations. Different examples from the wide spectrum of challenges in different fields give an idea of the needs and challenges regarding uncertainties in practical applications. Additionally, the practical limitations of current methods for mission- and safety-critical real world applications are discussed and an outlook on the next steps towards a broader usage of such methods is given.
Bayesian Optimization Meets Laplace Approximation for Robotic Introspection
Oct 30, 2020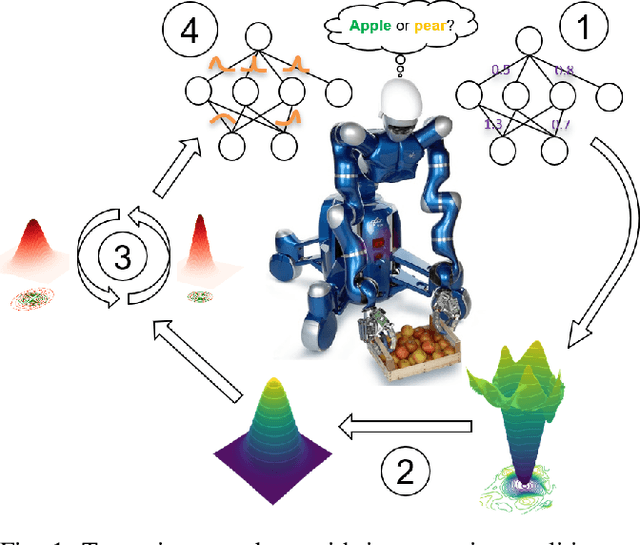
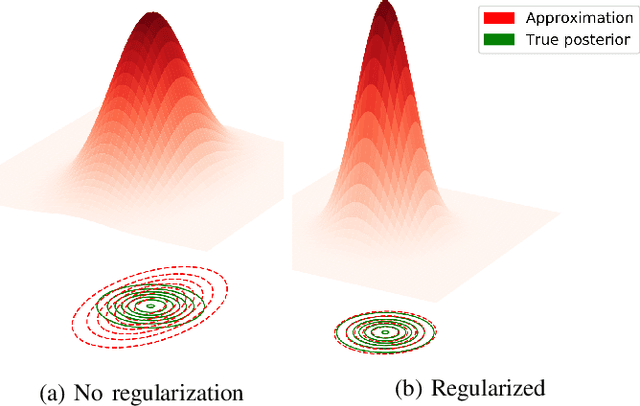
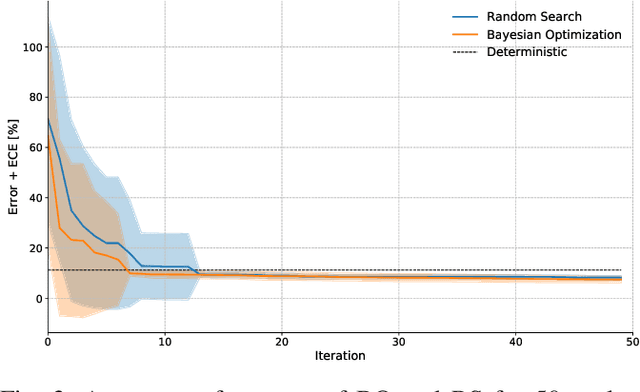
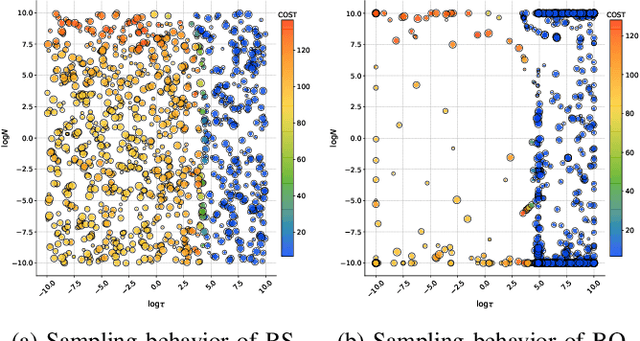
In robotics, deep learning (DL) methods are used more and more widely, but their general inability to provide reliable confidence estimates will ultimately lead to fragile and unreliable systems. This impedes the potential deployments of DL methods for long-term autonomy. Therefore, in this paper we introduce a scalable Laplace Approximation (LA) technique to make Deep Neural Networks (DNNs) more introspective, i.e. to enable them to provide accurate assessments of their failure probability for unseen test data. In particular, we propose a novel Bayesian Optimization (BO) algorithm to mitigate their tendency of under-fitting the true weight posterior, so that both the calibration and the accuracy of the predictions can be simultaneously optimized. We demonstrate empirically that the proposed BO approach requires fewer iterations for this when compared to random search, and we show that the proposed framework can be scaled up to large datasets and architectures.
Learning Multiplicative Interactions with Bayesian Neural Networks for Visual-Inertial Odometry
Jul 15, 2020
This paper presents an end-to-end multi-modal learning approach for monocular Visual-Inertial Odometry (VIO), which is specifically designed to exploit sensor complementarity in the light of sensor degradation scenarios. The proposed network makes use of a multi-head self-attention mechanism that learns multiplicative interactions between multiple streams of information. Another design feature of our approach is the incorporation of the model uncertainty using scalable Laplace Approximation. We evaluate the performance of the proposed approach by comparing it against the end-to-end state-of-the-art methods on the KITTI dataset and show that it achieves superior performance. Importantly, our work thereby provides an empirical evidence that learning multiplicative interactions can result in a powerful inductive bias for increased robustness to sensor failures.
Estimating Model Uncertainty of Neural Networks in Sparse Information Form
Jun 20, 2020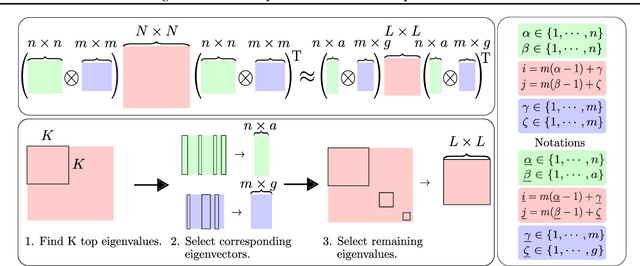
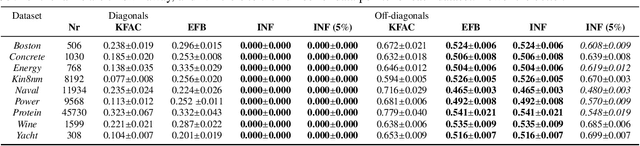
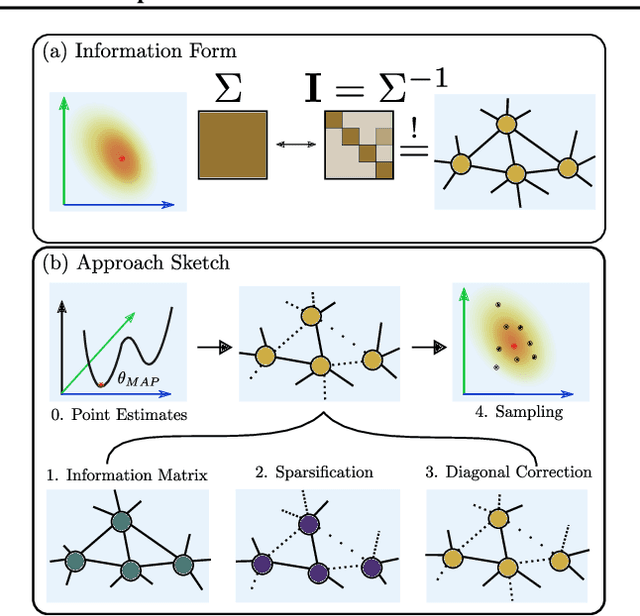

We present a sparse representation of model uncertainty for Deep Neural Networks (DNNs) where the parameter posterior is approximated with an inverse formulation of the Multivariate Normal Distribution (MND), also known as the information form. The key insight of our work is that the information matrix, i.e. the inverse of the covariance matrix tends to be sparse in its spectrum. Therefore, dimensionality reduction techniques such as low rank approximations (LRA) can be effectively exploited. To achieve this, we develop a novel sparsification algorithm and derive a cost-effective analytical sampler. As a result, we show that the information form can be scalably applied to represent model uncertainty in DNNs. Our exhaustive theoretical analysis and empirical evaluations on various benchmarks show the competitiveness of our approach over the current methods.