 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposing Dextrous Grasping and In-hand Manipulation via Scoring with a Reinforcement Learning Critic
May 19, 2025In-hand manipulation and grasping are fundamental yet often separately addressed tasks in robotics. For deriving in-hand manipulation policies, reinforcement learning has recently shown great success. However, the derived controllers are not yet useful in real-world scenarios because they often require a human operator to place the objects in suitable initial (grasping) states. Finding stable grasps that also promote the desired in-hand manipulation goal is an open problem. In this work, we propose a method for bridging this gap by leveraging the critic network of a reinforcement learning agent trained for in-hand manipulation to score and select initial grasps. Our experiments show that this method significantly increases the success rate of in-hand manipulation without requiring additional training. We also present an implementation of a full grasp manipulation pipeline on a real-world system, enabling autonomous grasping and reorientation even of unwieldy objects.
Self-Contained Calibration of an Elastic Humanoid Upper Body Using Only a Head-Mounted RGB Camera
Nov 14, 2023



When a humanoid robot performs a manipulation task, it first makes a model of the world using its visual sensors and then plans the motion of its body in this model. For this, precise calibration of the camera parameters and the kinematic tree is needed. Besides the accuracy of the calibrated model, the calibration process should be fast and self-contained, i.e., no external measurement equipment should be used. Therefore, we extend our prior work on calibrating the elastic upper body of DLR's Agile Justin by now using only its internal head-mounted RGB camera. We use simple visual markers at the ends of the kinematic chain and one in front of the robot, mounted on a pole, to get measurements for the whole kinematic tree. To ensure that the task-relevant cartesian error at the end-effectors is minimized, we introduce virtual noise to fit our imperfect robot model so that the pixel error has a higher weight if the marker is further away from the camera. This correction reduces the cartesian error by more than 20%, resulting in a final accuracy of 3.9mm on average and 9.1mm in the worst case. This way, we achieve the same precision as in our previous work, where an external cartesian tracking system was used.
Combining Shape Completion and Grasp Prediction for Fast and Versatile Grasping with a Multi-Fingered Hand
Oct 31, 2023
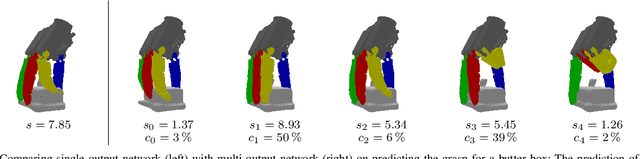
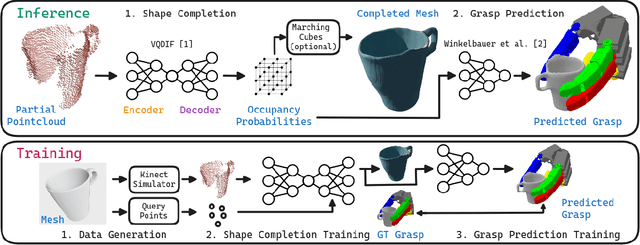

Grasping objects with limited or no prior knowledge about them is a highly relevant skill in assistive robotics. Still, in this general setting, it has remained an open problem, especially when it comes to only partial observability and versatile grasping with multi-fingered hands. We present a novel, fast, and high fidelity deep learning pipeline consisting of a shape completion module that is based on a single depth image, and followed by a grasp predictor that is based on the predicted object shape. The shape completion network is based on VQDIF and predicts spatial occupancy values at arbitrary query points. As grasp predictor, we use our two-stage architecture that first generates hand poses using an autoregressive model and then regresses finger joint configurations per pose. Critical factors turn out to be sufficient data realism and augmentation, as well as special attention to difficult cases during training. Experiments on a physical robot platform demonstrate successful grasping of a wide range of household objects based on a depth image from a single viewpoint. The whole pipeline is fast, taking only about 1 s for completing the object's shape (0.7 s) and generating 1000 grasps (0.3 s).
Shape Completion with Prediction of Uncertain Regions
Aug 01, 2023



Shape completion, i.e., predicting the complete geometry of an object from a partial observation, is highly relevant for several downstream tasks, most notably robotic manipulation. When basing planning or prediction of real grasps on object shape reconstruction, an indication of severe geometric uncertainty is indispensable. In particular, there can be an irreducible uncertainty in extended regions about the presence of entire object parts when given ambiguous object views. To treat this important case, we propose two novel methods for predicting such uncertain regions as straightforward extensions of any method for predicting local spatial occupancy, one through postprocessing occupancy scores, the other through direct prediction of an uncertainty indicator. We compare these methods together with two known approaches to probabilistic shape completion. Moreover, we generate a dataset, derived from ShapeNet, of realistically rendered depth images of object views with ground-truth annotations for the uncertain regions. We train on this dataset and test each method in shape completion and prediction of uncertain regions for known and novel object instances and on synthetic and real data. While direct uncertainty prediction is by far the most accurate in the segmentation of uncertain regions, both novel methods outperform the two baselines in shape completion and uncertain region prediction, and avoiding the predicted uncertain regions increases the quality of grasps for all tested methods. Web: https://github.com/DLR-RM/shape-completion
Learning to Localize in New Environments from Synthetic Training Data
Nov 09, 2020Most existing approaches for visual localization either need a detailed 3D model of the environment or, in the case of learning-based methods, must be retrained for each new scene. This can either be very expensive or simply impossible for large, unknown environments, for example in search-and-rescue scenarios. Although there are learning-based approaches that operate scene-agnostically, the generalization capability of these methods is still outperformed by classical approaches. In this paper, we present an approach that can generalize to new scenes by applying specific changes to the model architecture, including an extended regression part, the use of hierarchical correlation layers, and the exploitation of scale and uncertainty information. Our approach outperforms the 5-point algorithm using SIFT features on equally big images and additionally surpasses all previous learning-based approaches that were trained on different data. It is also superior to most of the approaches that were specifically trained on the respective scenes. We also evaluate our approach in a scenario where only very few reference images are available, showing that under such more realistic conditions our learning-based approach considerably exceeds both existing learning-based and classical methods.
BlenderProc
Oct 25, 2019



BlenderProc is a modular procedural pipeline, which helps in generating real looking images for the training of convolutional neural networks. These can be used in a variety of use cases including segmentation, depth, normal and pose estimation and many others. A key feature of our extension of blender is the simple to use modular pipeline, which was designed to be easily extendable. By offering standard modules, which cover a variety of scenarios, we provide a starting point on which new modules can be created.