 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Latent Generative Paradigms for High-Fidelity 3D Shape Completion from a Single Depth Image
Nov 14, 2025While generative models have seen significant adoption across a wide range of data modalities, including 3D data, a consensus on which model is best suited for which task has yet to be reached. Further, conditional information such as text and images to steer the generation process are frequently employed, whereas others, like partial 3D data, have not been thoroughly evaluated. In this work, we compare two of the most promising generative models--Denoising Diffusion Probabilistic Models and Autoregressive Causal Transformers--which we adapt for the tasks of generative shape modeling and completion. We conduct a thorough quantitative evaluation and comparison of both tasks, including a baseline discriminative model and an extensive ablation study. Our results show that (1) the diffusion model with continuous latents outperforms both the discriminative model and the autoregressive approach and delivers state-of-the-art performance on multi-modal shape completion from a single, noisy depth image under realistic conditions and (2) when compared on the same discrete latent space, the autoregressive model can match or exceed diffusion performance on these tasks.
Combining Shape Completion and Grasp Prediction for Fast and Versatile Grasping with a Multi-Fingered Hand
Oct 31, 2023
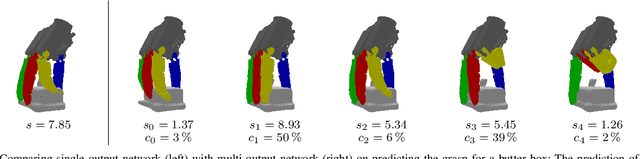
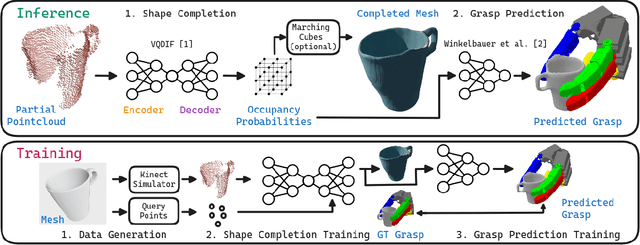

Grasping objects with limited or no prior knowledge about them is a highly relevant skill in assistive robotics. Still, in this general setting, it has remained an open problem, especially when it comes to only partial observability and versatile grasping with multi-fingered hands. We present a novel, fast, and high fidelity deep learning pipeline consisting of a shape completion module that is based on a single depth image, and followed by a grasp predictor that is based on the predicted object shape. The shape completion network is based on VQDIF and predicts spatial occupancy values at arbitrary query points. As grasp predictor, we use our two-stage architecture that first generates hand poses using an autoregressive model and then regresses finger joint configurations per pose. Critical factors turn out to be sufficient data realism and augmentation, as well as special attention to difficult cases during training. Experiments on a physical robot platform demonstrate successful grasping of a wide range of household objects based on a depth image from a single viewpoint. The whole pipeline is fast, taking only about 1 s for completing the object's shape (0.7 s) and generating 1000 grasps (0.3 s).
Shape Completion with Prediction of Uncertain Regions
Aug 01, 2023



Shape completion, i.e., predicting the complete geometry of an object from a partial observation, is highly relevant for several downstream tasks, most notably robotic manipulation. When basing planning or prediction of real grasps on object shape reconstruction, an indication of severe geometric uncertainty is indispensable. In particular, there can be an irreducible uncertainty in extended regions about the presence of entire object parts when given ambiguous object views. To treat this important case, we propose two novel methods for predicting such uncertain regions as straightforward extensions of any method for predicting local spatial occupancy, one through postprocessing occupancy scores, the other through direct prediction of an uncertainty indicator. We compare these methods together with two known approaches to probabilistic shape completion. Moreover, we generate a dataset, derived from ShapeNet, of realistically rendered depth images of object views with ground-truth annotations for the uncertain regions. We train on this dataset and test each method in shape completion and prediction of uncertain regions for known and novel object instances and on synthetic and real data. While direct uncertainty prediction is by far the most accurate in the segmentation of uncertain regions, both novel methods outperform the two baselines in shape completion and uncertain region prediction, and avoiding the predicted uncertain regions increases the quality of grasps for all tested methods. Web: https://github.com/DLR-RM/shape-completion
Probabilistic Search for Object Segmentation and Recognition
Aug 05, 2002
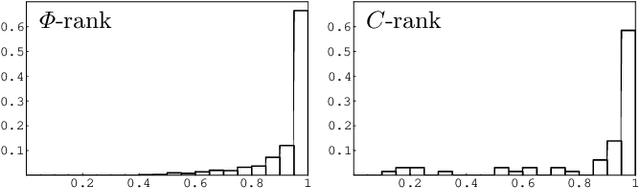
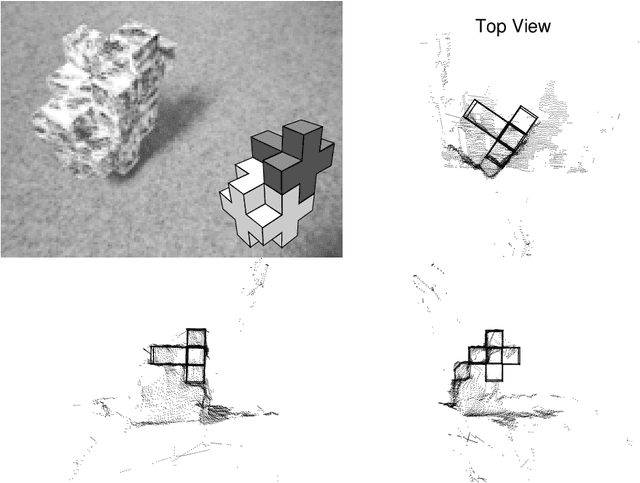
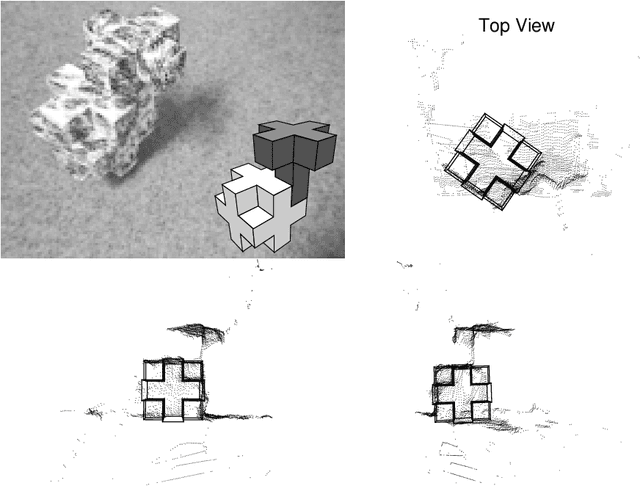
The problem of searching for a model-based scene interpretation is analyzed within a probabilistic framework. Object models are formulated as generative models for range data of the scene. A new statistical criterion, the truncated object probability, is introduced to infer an optimal sequence of object hypotheses to be evaluated for their match to the data. The truncated probability is partly determined by prior knowledge of the objects and partly learned from data. Some experiments on sequence quality and object segmentation and recognition from stereo data are presented. The article recovers classic concepts from object recognition (grouping, geometric hashing, alignment) from the probabilistic perspective and adds insight into the optimal ordering of object hypotheses for evaluation. Moreover, it introduces point-relation densities, a key component of the truncated probability, as statistical models of local surface shape.
* 18 pages, 5 figures