 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposing Dextrous Grasping and In-hand Manipulation via Scoring with a Reinforcement Learning Critic
May 19, 2025In-hand manipulation and grasping are fundamental yet often separately addressed tasks in robotics. For deriving in-hand manipulation policies, reinforcement learning has recently shown great success. However, the derived controllers are not yet useful in real-world scenarios because they often require a human operator to place the objects in suitable initial (grasping) states. Finding stable grasps that also promote the desired in-hand manipulation goal is an open problem. In this work, we propose a method for bridging this gap by leveraging the critic network of a reinforcement learning agent trained for in-hand manipulation to score and select initial grasps. Our experiments show that this method significantly increases the success rate of in-hand manipulation without requiring additional training. We also present an implementation of a full grasp manipulation pipeline on a real-world system, enabling autonomous grasping and reorientation even of unwieldy objects.
Learning Time-Optimal and Speed-Adjustable Tactile In-Hand Manipulation
Nov 20, 2024



In-hand manipulation with multi-fingered hands is a challenging problem that recently became feasible with the advent of deep reinforcement learning methods. While most contributions to the task brought improvements in robustness and generalization, this paper addresses the critical performance measure of the speed at which an in-hand manipulation can be performed. We present reinforcement learning policies that can perform in-hand reorientation significantly faster than previous approaches for the complex setting of goal-conditioned reorientation in SO(3) with permanent force closure and tactile feedback only (i.e., using the hand's torque and position sensors). Moreover, we show how policies can be trained to be speed-adjustable, allowing for setting the average orientation speed of the manipulated object during deployment. To this end, we present suitable and minimalistic reinforcement learning objectives for time-optimal and speed-adjustable in-hand manipulation, as well as an analysis based on extensive experiments in simulation. We also demonstrate the zero-shot transfer of the learned policies to the real DLR-Hand II with a wide range of target speeds and the fastest dextrous in-hand manipulation without visual inputs.
Learning a Shape-Conditioned Agent for Purely Tactile In-Hand Manipulation of Various Objects
Jul 26, 2024Reorienting diverse objects with a multi-fingered hand is a challenging task. Current methods in robotic in-hand manipulation are either object-specific or require permanent supervision of the object state from visual sensors. This is far from human capabilities and from what is needed in real-world applications. In this work, we address this gap by training shape-conditioned agents to reorient diverse objects in hand, relying purely on tactile feedback (via torque and position measurements of the fingers' joints). To achieve this, we propose a learning framework that exploits shape information in a reinforcement learning policy and a learned state estimator. We find that representing 3D shapes by vectors from a fixed set of basis points to the shape's surface, transformed by its predicted 3D pose, is especially helpful for learning dexterous in-hand manipulation. In simulation and real-world experiments, we show the reorientation of many objects with high success rates, on par with state-of-the-art results obtained with specialized single-object agents. Moreover, we show generalization to novel objects, achieving success rates of $\sim$90% even for non-convex shapes.
Calibration of an Elastic Humanoid Upper Body and Efficient Compensation for Motion Planning
Nov 14, 2023



High absolute accuracy is an essential prerequisite for a humanoid robot to autonomously and robustly perform manipulation tasks while avoiding obstacles. We present for the first time a kinematic model for a humanoid upper body incorporating joint and transversal elasticities. These elasticities lead to significant deformations due to the robot's own weight, and the resulting model is implicitly defined via a torque equilibrium. We successfully calibrate this model for DLR's humanoid Agile Justin, including all Denavit-Hartenberg parameters and elasticities. The calibration is formulated as a combined least-squares problem with priors and based on measurements of the end effector positions of both arms via an external tracking system. The absolute position error is massively reduced from 21mm to 3.1mm on average in the whole workspace. Using this complex and implicit kinematic model in motion planning is challenging. We show that for optimization-based path planning, integrating the iterative solution of the implicit model into the optimization loop leads to an elegant and highly efficient solution. For mildly elastic robots like Agile Justin, there is no performance impact, and even for a simulated highly flexible robot with 20 times higher elasticities, the runtime increases by only 30%.
Self-Contained Calibration of an Elastic Humanoid Upper Body Using Only a Head-Mounted RGB Camera
Nov 14, 2023



When a humanoid robot performs a manipulation task, it first makes a model of the world using its visual sensors and then plans the motion of its body in this model. For this, precise calibration of the camera parameters and the kinematic tree is needed. Besides the accuracy of the calibrated model, the calibration process should be fast and self-contained, i.e., no external measurement equipment should be used. Therefore, we extend our prior work on calibrating the elastic upper body of DLR's Agile Justin by now using only its internal head-mounted RGB camera. We use simple visual markers at the ends of the kinematic chain and one in front of the robot, mounted on a pole, to get measurements for the whole kinematic tree. To ensure that the task-relevant cartesian error at the end-effectors is minimized, we introduce virtual noise to fit our imperfect robot model so that the pixel error has a higher weight if the marker is further away from the camera. This correction reduces the cartesian error by more than 20%, resulting in a final accuracy of 3.9mm on average and 9.1mm in the worst case. This way, we achieve the same precision as in our previous work, where an external cartesian tracking system was used.
Speeding Up Optimization-based Motion Planning through Deep Learning
Nov 14, 2023



Planning collision-free motions for robots with many degrees of freedom is challenging in environments with complex obstacle geometries. Recent work introduced the idea of speeding up the planning by encoding prior experience of successful motion plans in a neural network. However, this "neural motion planning" did not scale to complex robots in unseen 3D environments as needed for real-world applications. Here, we introduce "basis point set", well-known in computer vision, to neural motion planning as a modern compact environment encoding enabling efficient supervised training networks that generalize well over diverse 3D worlds. Combined with a new elaborate training scheme, we reach a planning success rate of 100%. We use the network to predict an educated initial guess for an optimization-based planner (OMP), which quickly converges to a feasible solution, massively outperforming random multi-starts when tested on previously unseen environments. For the DLR humanoid Agile Justin with 19DoF and in challenging obstacle environments, optimal paths can be generated in 200ms using only a single CPU core. We also show a first successful real-world experiment based on a high-resolution world model from an integrated 3D sensor.
Efficient Learning of Fast Inverse Kinematics with Collision Avoidance
Nov 10, 2023Fast inverse kinematics (IK) is a central component in robotic motion planning. For complex robots, IK methods are often based on root search and non-linear optimization algorithms. These algorithms can be massively sped up using a neural network to predict a good initial guess, which can then be refined in a few numerical iterations. Besides previous work on learning-based IK, we present a learning approach for the fundamentally more complex problem of IK with collision avoidance. We do this in diverse and previously unseen environments. From a detailed analysis of the IK learning problem, we derive a network and unsupervised learning architecture that removes the need for a sample data generation step. Using the trained network's prediction as an initial guess for a two-stage Jacobian-based solver allows for fast and accurate computation of the collision-free IK. For the humanoid robot, Agile Justin (19 DoF), the collision-free IK is solved in less than 10 milliseconds (on a single CPU core) and with an accuracy of 10^-4 m and 10^-3 rad based on a high-resolution world model generated from the robot's integrated 3D sensor. Our method massively outperforms a random multi-start baseline in a benchmark with the 19 DoF humanoid and challenging 3D environments. It requires ten times less training time than a supervised training method while achieving comparable results.
Self-Contained and Automatic Calibration of a Multi-Fingered Hand Using Only Pairwise Contact Measurements
Nov 07, 2023A self-contained calibration procedure that can be performed automatically without additional external sensors or tools is a significant advantage, especially for complex robotic systems. Here, we show that the kinematics of a multi-fingered robotic hand can be precisely calibrated only by moving the tips of the fingers pairwise into contact. The only prerequisite for this is sensitive contact detection, e.g., by torque-sensing in the joints (as in our DLR-Hand II) or tactile skin. The measurement function for a given joint configuration is the distance between the modeled fingertip geometries, but the actual measurement is always zero. In an in-depth analysis, we prove that this contact-based calibration determines all quantities needed for manipulating objects with the hand, i.e., the difference vectors of the fingertips, and that it is as sensitive as a calibration using an external visual tracking system and markers. We describe the complete calibration scheme, including the selection of optimal sample joint configurations and search motions for the contacts despite the initial kinematic uncertainties. In a real-world calibration experiment for the torque-controlled four-fingered DLR-Hand II, the maximal error of 17.7mm can be reduced to only 3.7mm.
Estimator-Coupled Reinforcement Learning for Robust Purely Tactile In-Hand Manipulation
Nov 07, 2023



This paper identifies and addresses the problems with naively combining (reinforcement) learning-based controllers and state estimators for robotic in-hand manipulation. Specifically, we tackle the challenging task of purely tactile, goal-conditioned, dextrous in-hand reorientation with the hand pointing downwards. Due to the limited sensing available, many control strategies that are feasible in simulation when having full knowledge of the object's state do not allow for accurate state estimation. Hence, separately training the controller and the estimator and combining the two at test time leads to poor performance. We solve this problem by coupling the control policy to the state estimator already during training in simulation. This approach leads to more robust state estimation and overall higher performance on the task while maintaining an interpretability advantage over end-to-end policy learning. With our GPU-accelerated implementation, learning from scratch takes a median training time of only 6.5 hours on a single, low-cost GPU. In simulation experiments with the DLR-Hand II and for four significantly different object shapes, we provide an in-depth analysis of the performance of our approach. We demonstrate the successful sim2real transfer by rotating the four objects to all 24 orientations in the $\pi/2$ discretization of SO(3), which has never been achieved for such a diverse set of shapes. Finally, our method can reorient a cube consecutively to nine goals (median), which was beyond the reach of previous methods in this challenging setting.
Combining Shape Completion and Grasp Prediction for Fast and Versatile Grasping with a Multi-Fingered Hand
Oct 31, 2023
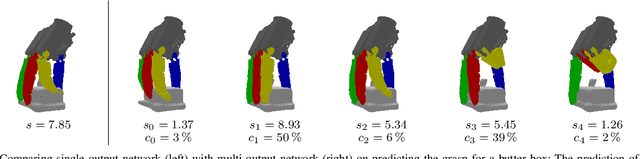
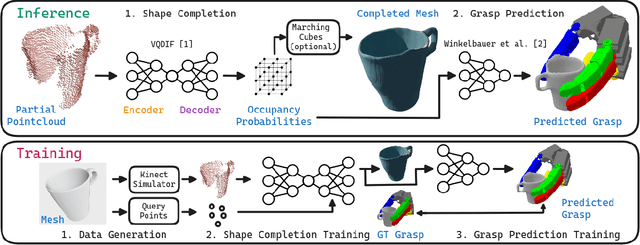

Grasping objects with limited or no prior knowledge about them is a highly relevant skill in assistive robotics. Still, in this general setting, it has remained an open problem, especially when it comes to only partial observability and versatile grasping with multi-fingered hands. We present a novel, fast, and high fidelity deep learning pipeline consisting of a shape completion module that is based on a single depth image, and followed by a grasp predictor that is based on the predicted object shape. The shape completion network is based on VQDIF and predicts spatial occupancy values at arbitrary query points. As grasp predictor, we use our two-stage architecture that first generates hand poses using an autoregressive model and then regresses finger joint configurations per pose. Critical factors turn out to be sufficient data realism and augmentation, as well as special attention to difficult cases during training. Experiments on a physical robot platform demonstrate successful grasping of a wide range of household objects based on a depth image from a single viewpoint. The whole pipeline is fast, taking only about 1 s for completing the object's shape (0.7 s) and generating 1000 grasps (0.3 s).