 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRECALL: Rehearsal-free Continual Learning for Object Classification
Sep 29, 2022
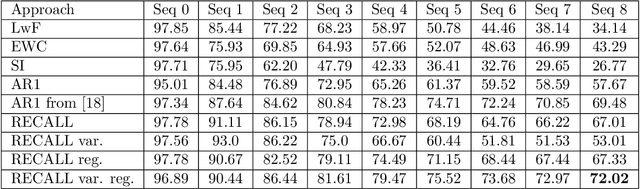
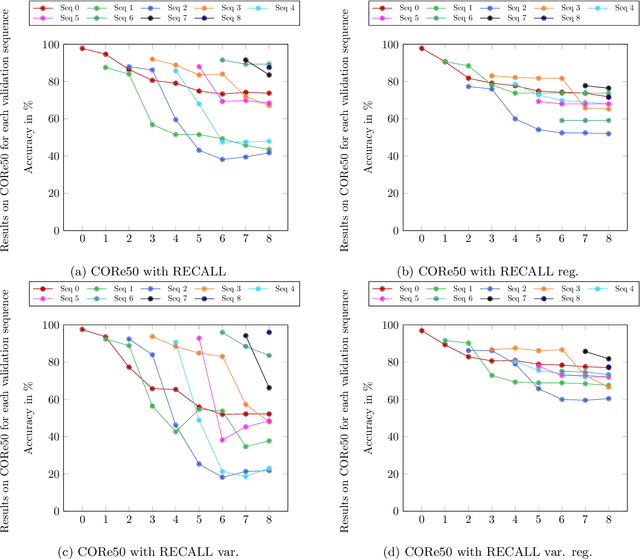
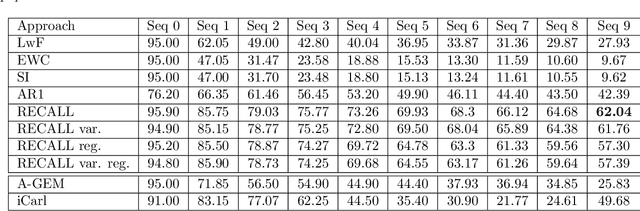
Convolutional neural networks show remarkable results in classification but struggle with learning new things on the fly. We present a novel rehearsal-free approach, where a deep neural network is continually learning new unseen object categories without saving any data of prior sequences. Our approach is called RECALL, as the network recalls categories by calculating logits for old categories before training new ones. These are then used during training to avoid changing the old categories. For each new sequence, a new head is added to accommodate the new categories. To mitigate forgetting, we present a regularization strategy where we replace the classification with a regression. Moreover, for the known categories, we propose a Mahalanobis loss that includes the variances to account for the changing densities between known and unknown categories. Finally, we present a novel dataset for continual learning, especially suited for object recognition on a mobile robot (HOWS-CL-25), including 150,795 synthetic images of 25 household object categories. Our approach RECALL outperforms the current state of the art on CORe50 and iCIFAR-100 and reaches the best performance on HOWS-CL-25.
Learning to Localize in New Environments from Synthetic Training Data
Nov 09, 2020Most existing approaches for visual localization either need a detailed 3D model of the environment or, in the case of learning-based methods, must be retrained for each new scene. This can either be very expensive or simply impossible for large, unknown environments, for example in search-and-rescue scenarios. Although there are learning-based approaches that operate scene-agnostically, the generalization capability of these methods is still outperformed by classical approaches. In this paper, we present an approach that can generalize to new scenes by applying specific changes to the model architecture, including an extended regression part, the use of hierarchical correlation layers, and the exploitation of scale and uncertainty information. Our approach outperforms the 5-point algorithm using SIFT features on equally big images and additionally surpasses all previous learning-based approaches that were trained on different data. It is also superior to most of the approaches that were specifically trained on the respective scenes. We also evaluate our approach in a scenario where only very few reference images are available, showing that under such more realistic conditions our learning-based approach considerably exceeds both existing learning-based and classical methods.
BlenderProc
Oct 25, 2019



BlenderProc is a modular procedural pipeline, which helps in generating real looking images for the training of convolutional neural networks. These can be used in a variety of use cases including segmentation, depth, normal and pose estimation and many others. A key feature of our extension of blender is the simple to use modular pipeline, which was designed to be easily extendable. By offering standard modules, which cover a variety of scenarios, we provide a starting point on which new modules can be created.