 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation of Mental Foramen in Orthopantomographs: A Deep Learning Approach
Aug 08, 2024Precise identification and detection of the Mental Foramen are crucial in dentistry, impacting procedures such as impacted tooth removal, cyst surgeries, and implants. Accurately identifying this anatomical feature facilitates post-surgery issues and improves patient outcomes. Moreover, this study aims to accelerate dental procedures, elevating patient care and healthcare efficiency in dentistry. This research used Deep Learning methods to accurately detect and segment the Mental Foramen from panoramic radiograph images. Two mask types, circular and square, were used during model training. Multiple segmentation models were employed to identify and segment the Mental Foramen, and their effectiveness was evaluated using diverse metrics. An in-house dataset comprising 1000 panoramic radiographs was created for this study. Our experiments demonstrated that the Classical UNet model performed exceptionally well on the test data, achieving a Dice Coefficient of 0.79 and an Intersection over Union (IoU) of 0.67. Moreover, ResUNet++ and UNet Attention models showed competitive performance, with Dice scores of 0.675 and 0.676, and IoU values of 0.683 and 0.671, respectively. We also investigated transfer learning models with varied backbone architectures, finding LinkNet to produce the best outcomes. In conclusion, our research highlights the efficacy of the classical Unet model in accurately identifying and outlining the Mental Foramen in panoramic radiographs. While vital, this task is comparatively simpler than segmenting complex medical datasets such as brain tumours or skin cancer, given their diverse sizes and shapes. This research also holds value in optimizing dental practice, benefiting practitioners and patients.
CONFLATOR: Incorporating Switching Point based Rotatory Positional Encodings for Code-Mixed Language Modeling
Sep 11, 2023



The mixing of two or more languages is called Code-Mixing (CM). CM is a social norm in multilingual societies. Neural Language Models (NLMs) like transformers have been very effective on many NLP tasks. However, NLM for CM is an under-explored area. Though transformers are capable and powerful, they cannot always encode positional/sequential information since they are non-recurrent. Therefore, to enrich word information and incorporate positional information, positional encoding is defined. We hypothesize that Switching Points (SPs), i.e., junctions in the text where the language switches (L1 -> L2 or L2-> L1), pose a challenge for CM Language Models (LMs), and hence give special emphasis to switching points in the modeling process. We experiment with several positional encoding mechanisms and show that rotatory positional encodings along with switching point information yield the best results. We introduce CONFLATOR: a neural language modeling approach for code-mixed languages. CONFLATOR tries to learn to emphasize switching points using smarter positional encoding, both at unigram and bigram levels. CONFLATOR outperforms the state-of-the-art on two tasks based on code-mixed Hindi and English (Hinglish): (i) sentiment analysis and (ii) machine translation.
PESTO: Switching Point based Dynamic and Relative Positional Encoding for Code-Mixed Languages
Nov 12, 2021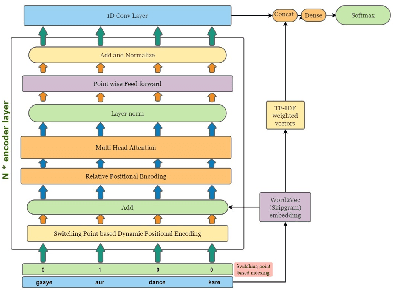
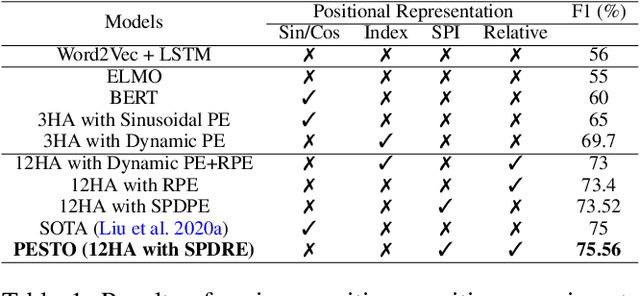
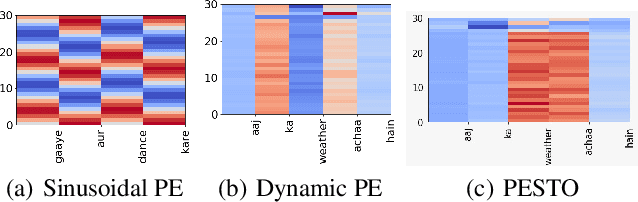
NLP applications for code-mixed (CM) or mix-lingual text have gained a significant momentum recently, the main reason being the prevalence of language mixing in social media communications in multi-lingual societies like India, Mexico, Europe, parts of USA etc. Word embeddings are basic build-ing blocks of any NLP system today, yet, word embedding for CM languages is an unexplored territory. The major bottleneck for CM word embeddings is switching points, where the language switches. These locations lack in contextually and statistical systems fail to model this phenomena due to high variance in the seen examples. In this paper we present our initial observations on applying switching point based positional encoding techniques for CM language, specifically Hinglish (Hindi - English). Results are only marginally better than SOTA, but it is evident that positional encoding could bean effective way to train position sensitive language models for CM text.
A Survey of Uncertainty in Deep Neural Networks
Jul 07, 2021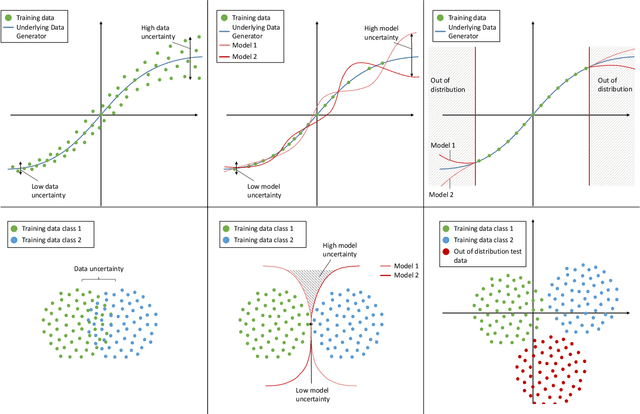
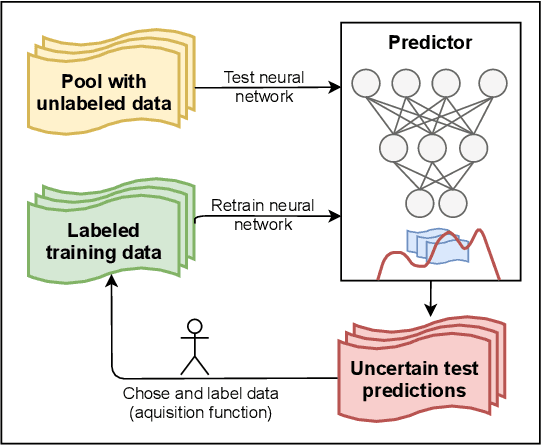
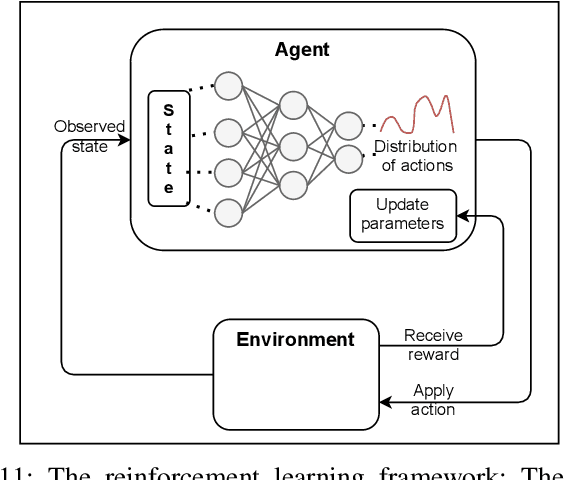
Due to their increasing spread, confidence in neural network predictions became more and more important. However, basic neural networks do not deliver certainty estimates or suffer from over or under confidence. Many researchers have been working on understanding and quantifying uncertainty in a neural network's prediction. As a result, different types and sources of uncertainty have been identified and a variety of approaches to measure and quantify uncertainty in neural networks have been proposed. This work gives a comprehensive overview of uncertainty estimation in neural networks, reviews recent advances in the field, highlights current challenges, and identifies potential research opportunities. It is intended to give anyone interested in uncertainty estimation in neural networks a broad overview and introduction, without presupposing prior knowledge in this field. A comprehensive introduction to the most crucial sources of uncertainty is given and their separation into reducible model uncertainty and not reducible data uncertainty is presented. The modeling of these uncertainties based on deterministic neural networks, Bayesian neural networks, ensemble of neural networks, and test-time data augmentation approaches is introduced and different branches of these fields as well as the latest developments are discussed. For a practical application, we discuss different measures of uncertainty, approaches for the calibration of neural networks and give an overview of existing baselines and implementations. Different examples from the wide spectrum of challenges in different fields give an idea of the needs and challenges regarding uncertainties in practical applications. Additionally, the practical limitations of current methods for mission- and safety-critical real world applications are discussed and an outlook on the next steps towards a broader usage of such methods is given.
Generative Adversarial Networks for Synthesizing InSAR Patches
Aug 03, 2020
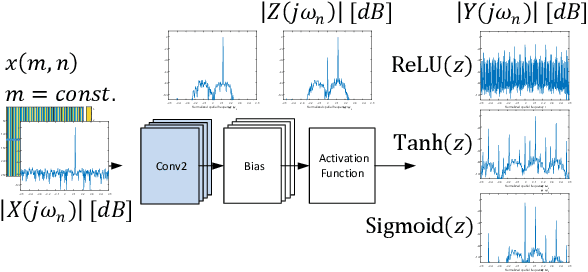
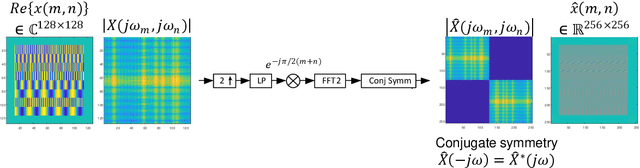
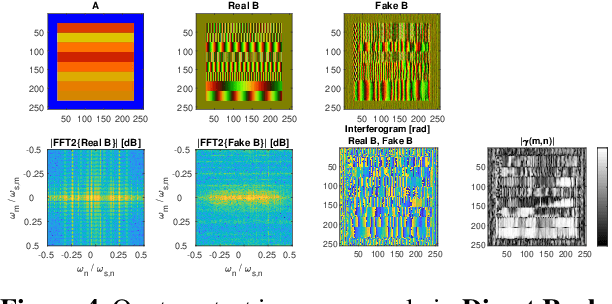
Generative Adversarial Networks (GANs) have been employed with certain success for image translation tasks between optical and real-valued SAR intensity imagery. Applications include aiding interpretability of SAR scenes with their optical counterparts by artificial patch generation and automatic SAR-optical scene matching. The synthesis of artificial complex-valued InSAR image stacks asks for, besides good perceptual quality, more stringent quality metrics like phase noise and phase coherence. This paper provides a signal processing model of generative CNN structures, describes effects influencing those quality metrics and presents a mapping scheme of complex-valued data to given CNN structures based on popular Deep Learning frameworks.
Deep Learning Meets SAR
Jun 17, 2020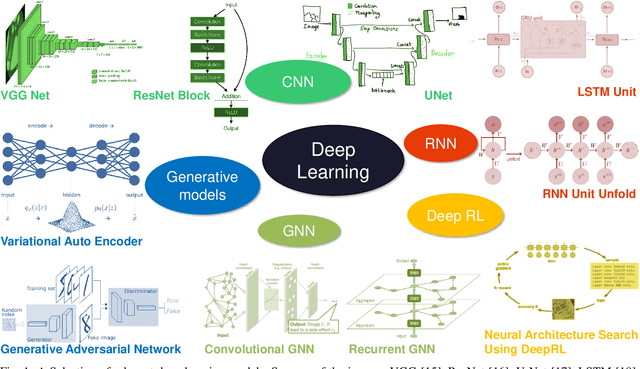

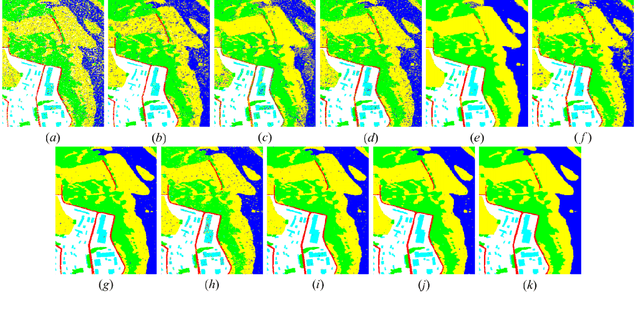
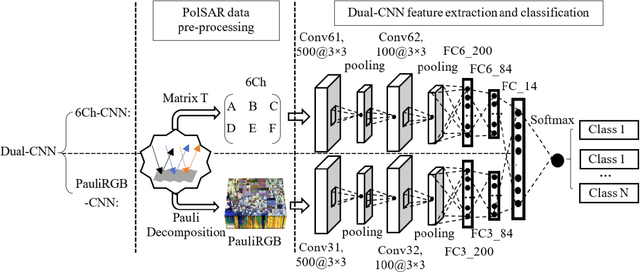
Deep learning in remote sensing has become an international hype, but it is mostly limited to the evaluation of optical data. Although deep learning has been introduced in SAR data processing, despite successful first attempts, its huge potential remains locked. For example, to the best knowledge of the authors, there is no single example of deep learning in SAR that has been developed up to operational processing of big data or integrated into the production chain of any satellite mission. In this paper, we provide an introduction to the most relevant deep learning models and concepts, point out possible pitfalls by analyzing special characteristics of SAR data, review the state-of-the-art of deep learning applied to SAR in depth, summarize available benchmarks, and recommend some important future research directions. With this effort, we hope to stimulate more research in this interesting yet under-exploited research field.