 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRRSIS: Referring Remote Sensing Image Segmentation
Jun 14, 2023
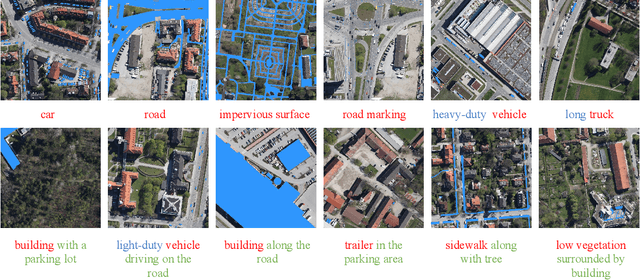

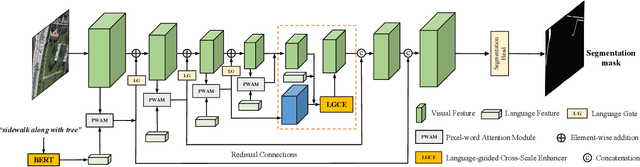
Localizing desired objects from remote sensing images is of great use in practical applications. Referring image segmentation, which aims at segmenting out the objects to which a given expression refers, has been extensively studied in natural images. However, almost no research attention is given to this task of remote sensing imagery. Considering its potential for real-world applications, in this paper, we introduce referring remote sensing image segmentation (RRSIS) to fill in this gap and make some insightful explorations. Specifically, we create a new dataset, called RefSegRS, for this task, enabling us to evaluate different methods. Afterward, we benchmark referring image segmentation methods of natural images on the RefSegRS dataset and find that these models show limited efficacy in detecting small and scattered objects. To alleviate this issue, we propose a language-guided cross-scale enhancement (LGCE) module that utilizes linguistic features to adaptively enhance multi-scale visual features by integrating both deep and shallow features. The proposed dataset, benchmarking results, and the designed LGCE module provide insights into the design of a better RRSIS model. We will make our dataset and code publicly available.
FuTH-Net: Fusing Temporal Relations and Holistic Features for Aerial Video Classification
Sep 22, 2022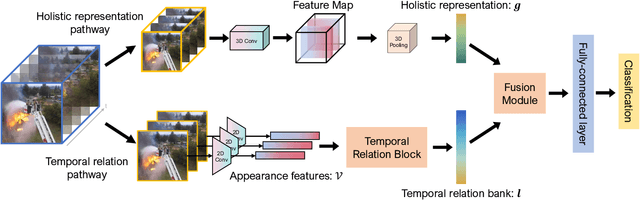

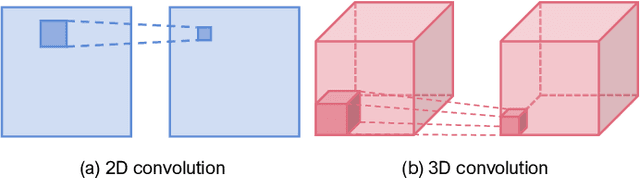
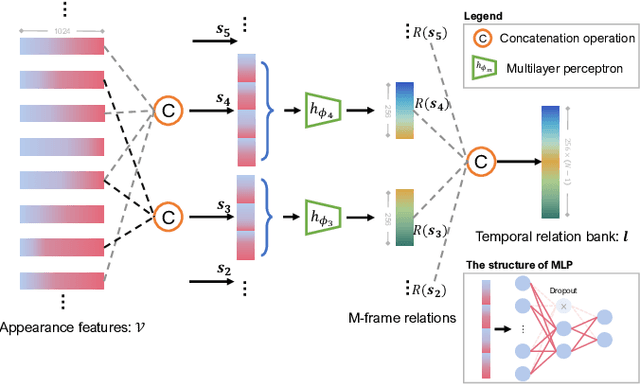
Unmanned aerial vehicles (UAVs) are now widely applied to data acquisition due to its low cost and fast mobility. With the increasing volume of aerial videos, the demand for automatically parsing these videos is surging. To achieve this, current researches mainly focus on extracting a holistic feature with convolutions along both spatial and temporal dimensions. However, these methods are limited by small temporal receptive fields and cannot adequately capture long-term temporal dependencies which are important for describing complicated dynamics. In this paper, we propose a novel deep neural network, termed FuTH-Net, to model not only holistic features, but also temporal relations for aerial video classification. Furthermore, the holistic features are refined by the multi-scale temporal relations in a novel fusion module for yielding more discriminative video representations. More specially, FuTH-Net employs a two-pathway architecture: (1) a holistic representation pathway to learn a general feature of both frame appearances and shortterm temporal variations and (2) a temporal relation pathway to capture multi-scale temporal relations across arbitrary frames, providing long-term temporal dependencies. Afterwards, a novel fusion module is proposed to spatiotemporal integrate the two features learned from the two pathways. Our model is evaluated on two aerial video classification datasets, ERA and Drone-Action, and achieves the state-of-the-art results. This demonstrates its effectiveness and good generalization capacity across different recognition tasks (event classification and human action recognition). To facilitate further research, we release the code at https://gitlab.lrz.de/ai4eo/reasoning/futh-net.
SCIDA: Self-Correction Integrated Domain Adaptation from Single- to Multi-label Aerial Images
Aug 15, 2021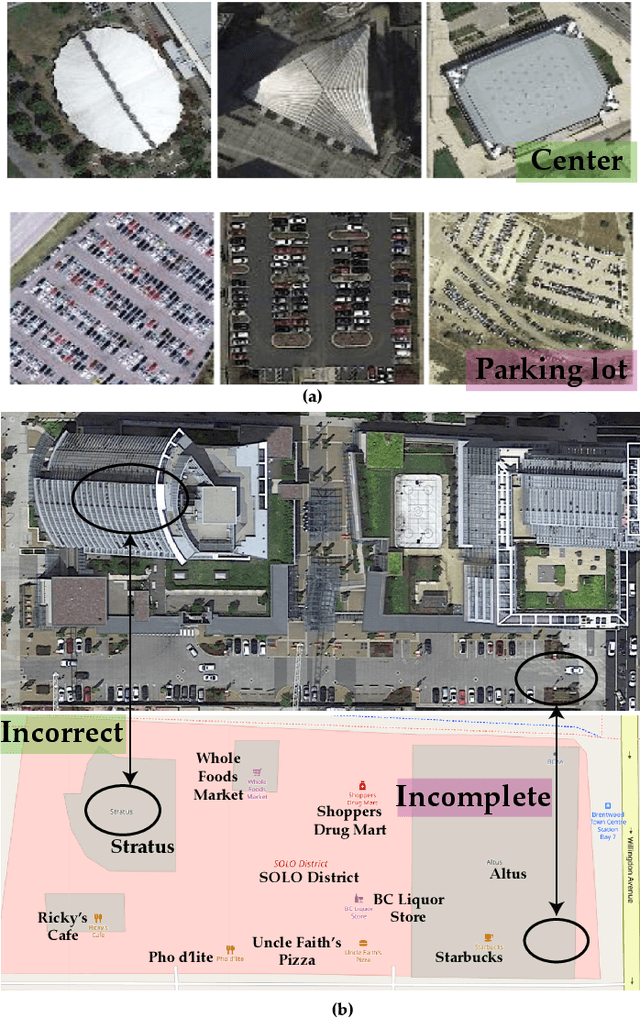
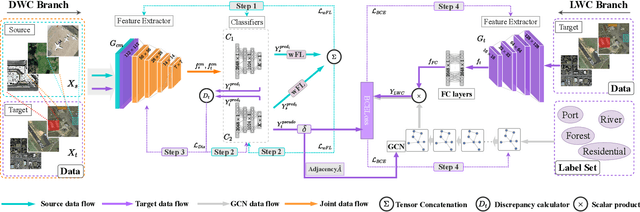
Most publicly available datasets for image classification are with single labels, while images are inherently multi-labeled in our daily life. Such an annotation gap makes many pre-trained single-label classification models fail in practical scenarios. This annotation issue is more concerned for aerial images: Aerial data collected from sensors naturally cover a relatively large land area with multiple labels, while annotated aerial datasets, which are publicly available (e.g., UCM, AID), are single-labeled. As manually annotating multi-label aerial images would be time/labor-consuming, we propose a novel self-correction integrated domain adaptation (SCIDA) method for automatic multi-label learning. SCIDA is weakly supervised, i.e., automatically learning the multi-label image classification model from using massive, publicly available single-label images. To achieve this goal, we propose a novel Label-Wise self-Correction (LWC) module to better explore underlying label correlations. This module also makes the unsupervised domain adaptation (UDA) from single- to multi-label data possible. For model training, the proposed model only uses single-label information yet requires no prior knowledge of multi-labeled data; and it predicts labels for multi-label aerial images. In our experiments, trained with single-labeled MAI-AID-s and MAI-UCM-s datasets, the proposed model is tested directly on our collected Multi-scene Aerial Image (MAI) dataset.
Aerial Scene Understanding in The Wild: Multi-Scene Recognition via Prototype-based Memory Networks
Apr 22, 2021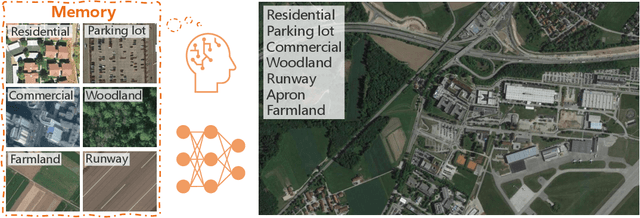
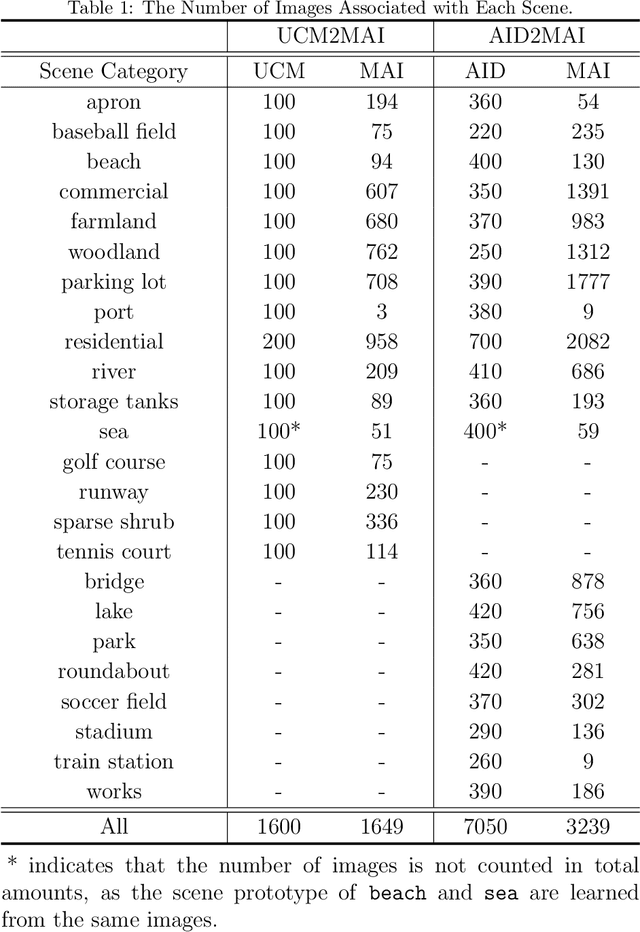

Aerial scene recognition is a fundamental visual task and has attracted an increasing research interest in the last few years. Most of current researches mainly deploy efforts to categorize an aerial image into one scene-level label, while in real-world scenarios, there often exist multiple scenes in a single image. Therefore, in this paper, we propose to take a step forward to a more practical and challenging task, namely multi-scene recognition in single images. Moreover, we note that manually yielding annotations for such a task is extraordinarily time- and labor-consuming. To address this, we propose a prototype-based memory network to recognize multiple scenes in a single image by leveraging massive well-annotated single-scene images. The proposed network consists of three key components: 1) a prototype learning module, 2) a prototype-inhabiting external memory, and 3) a multi-head attention-based memory retrieval module. To be more specific, we first learn the prototype representation of each aerial scene from single-scene aerial image datasets and store it in an external memory. Afterwards, a multi-head attention-based memory retrieval module is devised to retrieve scene prototypes relevant to query multi-scene images for final predictions. Notably, only a limited number of annotated multi-scene images are needed in the training phase. To facilitate the progress of aerial scene recognition, we produce a new multi-scene aerial image (MAI) dataset. Experimental results on variant dataset configurations demonstrate the effectiveness of our network. Our dataset and codes are publicly available.
MultiScene: A Large-scale Dataset and Benchmark for Multi-scene Recognition in Single Aerial Images
Apr 07, 2021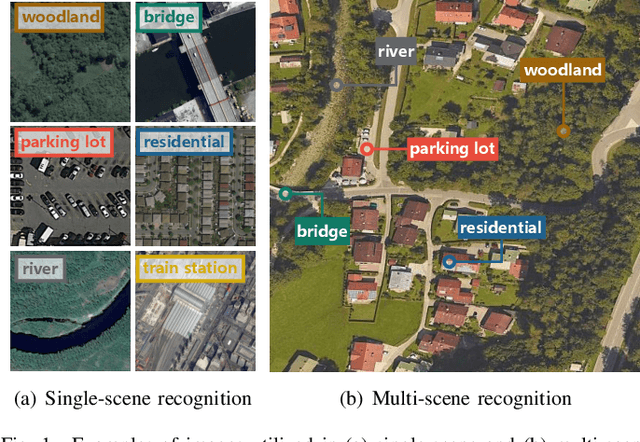
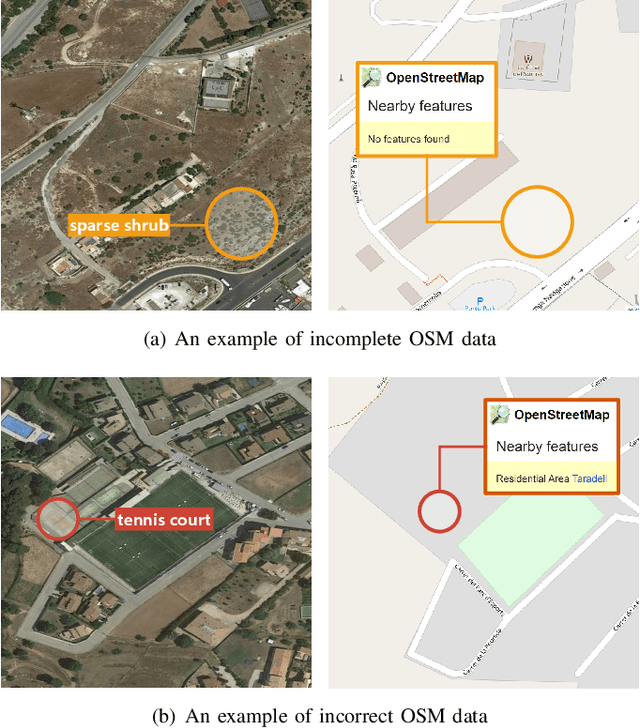
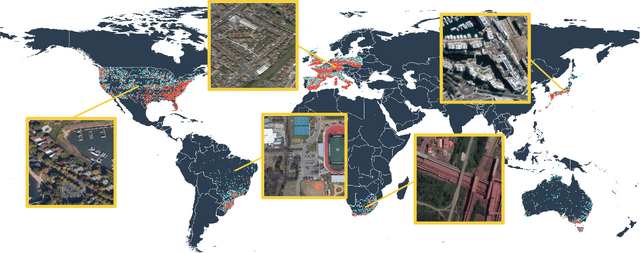
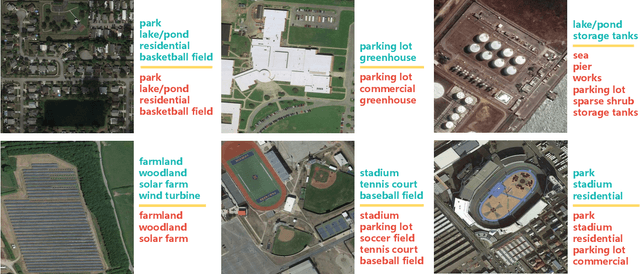
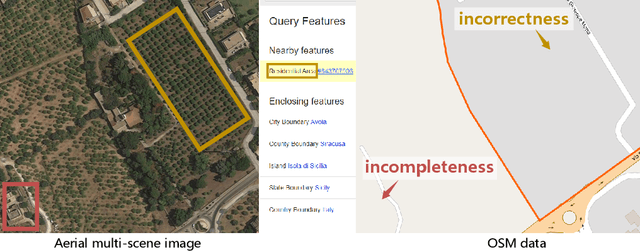
Aerial scene recognition is a fundamental research problem in interpreting high-resolution aerial imagery. Over the past few years, most studies focus on classifying an image into one scene category, while in real-world scenarios, it is more often that a single image contains multiple scenes. Therefore, in this paper, we investigate a more practical yet underexplored task -- multi-scene recognition in single images. To this end, we create a large-scale dataset, called MultiScene, composed of 100,000 unconstrained high-resolution aerial images. Considering that manually labeling such images is extremely arduous, we resort to low-cost annotations from crowdsourcing platforms, e.g., OpenStreetMap (OSM). However, OSM data might suffer from incompleteness and incorrectness, which introduce noise into image labels. To address this issue, we visually inspect 14,000 images and correct their scene labels, yielding a subset of cleanly-annotated images, named MultiScene-Clean. With it, we can develop and evaluate deep networks for multi-scene recognition using clean data. Moreover, we provide crowdsourced annotations of all images for the purpose of studying network learning with noisy labels. We conduct experiments with extensive baseline models on both MultiScene-Clean and MultiScene to offer benchmarks for multi-scene recognition in single images and learning from noisy labels for this task, respectively. To facilitate progress, we will make our dataset and pre-trained models available.
Deep Reinforcement Learning for Band Selection in Hyperspectral Image Classification
Mar 15, 2021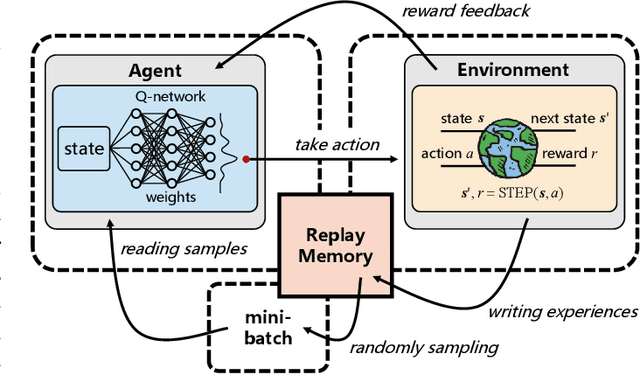
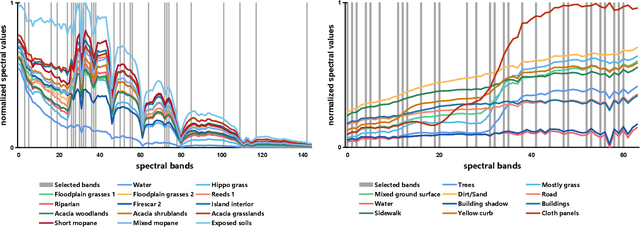
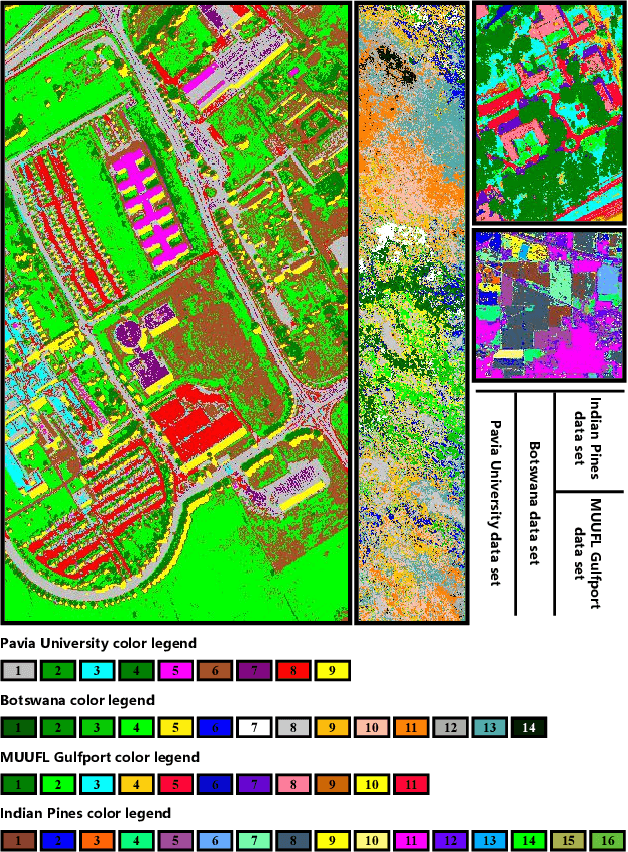
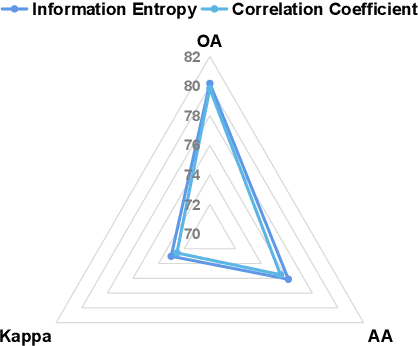
Band selection refers to the process of choosing the most relevant bands in a hyperspectral image. By selecting a limited number of optimal bands, we aim at speeding up model training, improving accuracy, or both. It reduces redundancy among spectral bands while trying to preserve the original information of the image. By now many efforts have been made to develop unsupervised band selection approaches, of which the majority are heuristic algorithms devised by trial and error. In this paper, we are interested in training an intelligent agent that, given a hyperspectral image, is capable of automatically learning policy to select an optimal band subset without any hand-engineered reasoning. To this end, we frame the problem of unsupervised band selection as a Markov decision process, propose an effective method to parameterize it, and finally solve the problem by deep reinforcement learning. Once the agent is trained, it learns a band-selection policy that guides the agent to sequentially select bands by fully exploiting the hyperspectral image and previously picked bands. Furthermore, we propose two different reward schemes for the environment simulation of deep reinforcement learning and compare them in experiments. This, to the best of our knowledge, is the first study that explores a deep reinforcement learning model for hyperspectral image analysis, thus opening a new door for future research and showcasing the great potential of deep reinforcement learning in remote sensing applications. Extensive experiments are carried out on four hyperspectral data sets, and experimental results demonstrate the effectiveness of the proposed method.
Semantic Segmentation of Remote Sensing Images with Sparse Annotations
Jan 10, 2021
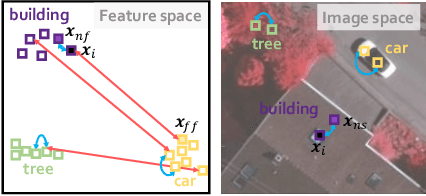

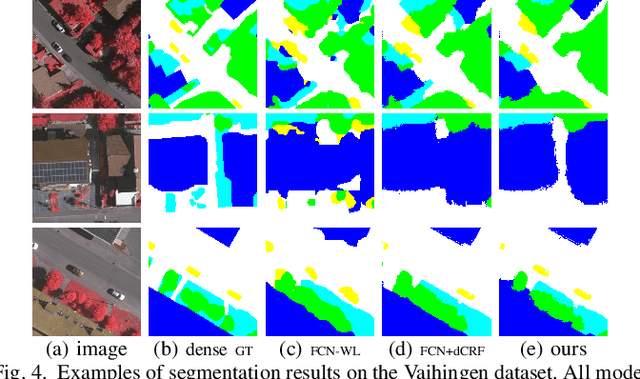
Training Convolutional Neural Networks (CNNs) for very high resolution images requires a large quantity of high-quality pixel-level annotations, which is extremely labor- and time-consuming to produce. Moreover, professional photo interpreters might have to be involved for guaranteeing the correctness of annotations. To alleviate such a burden, we propose a framework for semantic segmentation of aerial images based on incomplete annotations, where annotators are asked to label a few pixels with easy-to-draw scribbles. To exploit these sparse scribbled annotations, we propose the FEature and Spatial relaTional regulArization (FESTA) method to complement the supervised task with an unsupervised learning signal that accounts for neighbourhood structures both in spatial and feature terms.
CG-Net: Conditional GIS-aware Network for Individual Building Segmentation in VHR SAR Images
Nov 17, 2020
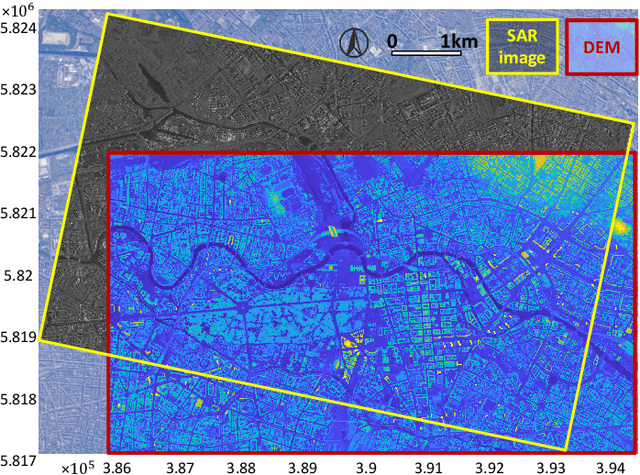
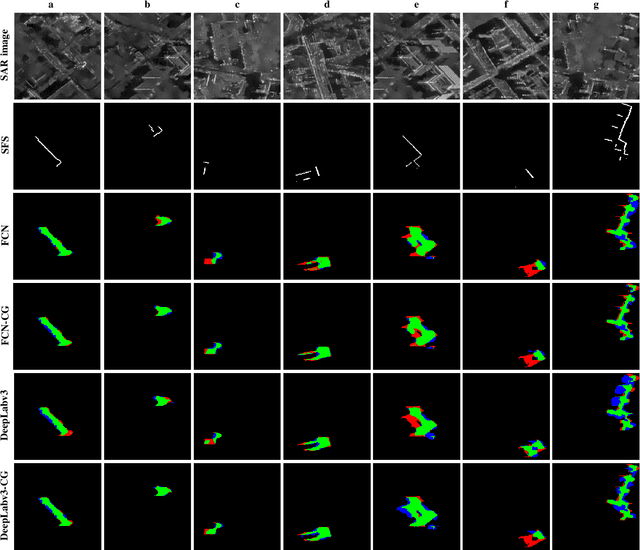
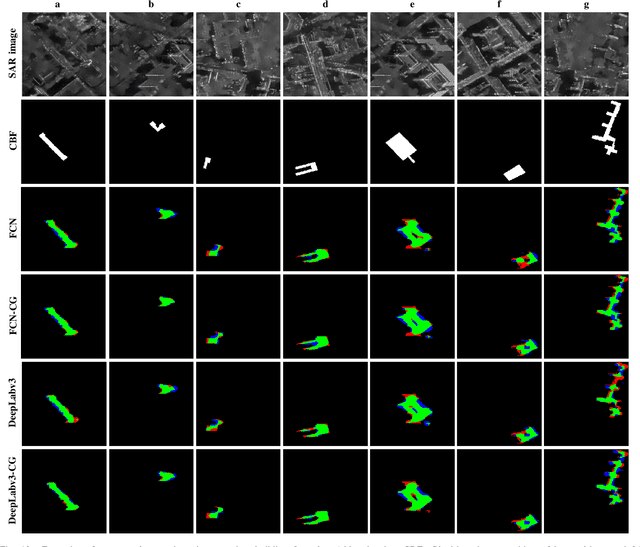
Object retrieval and reconstruction from very high resolution (VHR) synthetic aperture radar (SAR) images are of great importance for urban SAR applications, yet highly challenging owing to the complexity of SAR data. This paper addresses the issue of individual building segmentation from a single VHR SAR image in large-scale urban areas. To achieve this, we introduce building footprints from GIS data as complementary information and propose a novel conditional GIS-aware network (CG-Net). The proposed model learns multi-level visual features and employs building footprints to normalize the features for predicting building masks in the SAR image. We validate our method using a high resolution spotlight TerraSAR-X image collected over Berlin. Experimental results show that the proposed CG-Net effectively brings improvements with variant backbones. We further compare two representations of building footprints, namely complete building footprints and sensor-visible footprint segments, for our task, and conclude that the use of the former leads to better segmentation results. Moreover, we investigate the impact of inaccurate GIS data on our CG-Net, and this study shows that CG-Net is robust against positioning errors in GIS data. In addition, we propose an approach of ground truth generation of buildings from an accurate digital elevation model (DEM), which can be used to generate large-scale SAR image datasets. The segmentation results can be applied to reconstruct 3D building models at level-of-detail (LoD) 1, which is demonstrated in our experiments.
Deep Learning Meets SAR
Jun 17, 2020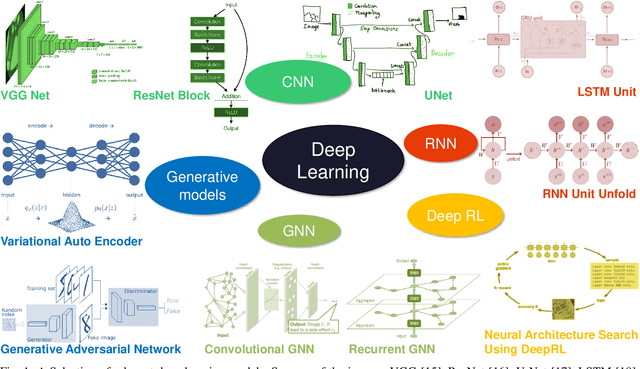

Deep learning in remote sensing has become an international hype, but it is mostly limited to the evaluation of optical data. Although deep learning has been introduced in SAR data processing, despite successful first attempts, its huge potential remains locked. For example, to the best knowledge of the authors, there is no single example of deep learning in SAR that has been developed up to operational processing of big data or integrated into the production chain of any satellite mission. In this paper, we provide an introduction to the most relevant deep learning models and concepts, point out possible pitfalls by analyzing special characteristics of SAR data, review the state-of-the-art of deep learning applied to SAR in depth, summarize available benchmarks, and recommend some important future research directions. With this effort, we hope to stimulate more research in this interesting yet under-exploited research field.
Instance segmentation of buildings using keypoints
Jun 06, 2020
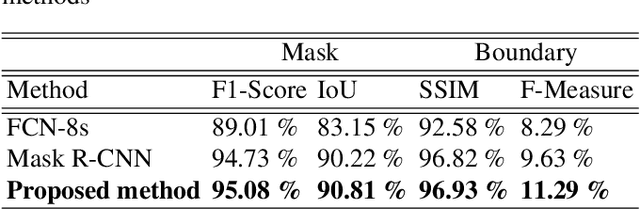
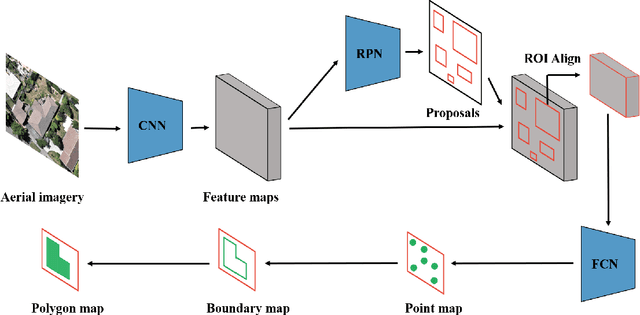
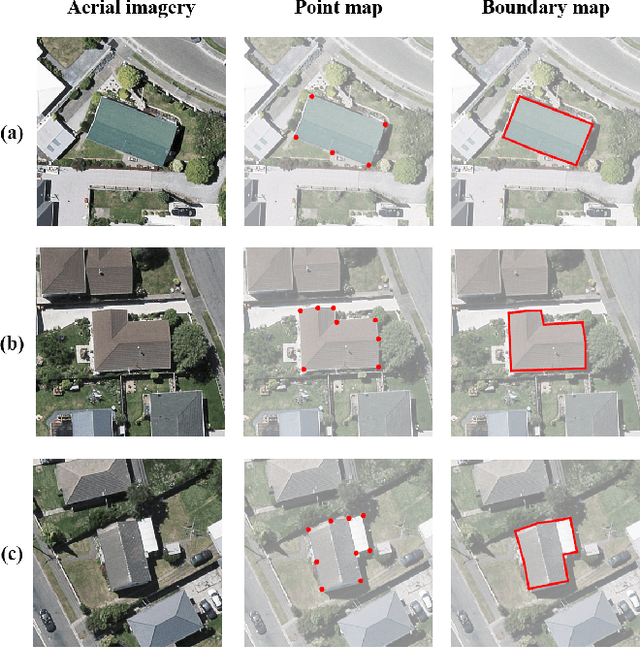
Building segmentation is of great importance in the task of remote sensing imagery interpretation. However, the existing semantic segmentation and instance segmentation methods often lead to segmentation masks with blurred boundaries. In this paper, we propose a novel instance segmentation network for building segmentation in high-resolution remote sensing images. More specifically, we consider segmenting an individual building as detecting several keypoints. The detected keypoints are subsequently reformulated as a closed polygon, which is the semantic boundary of the building. By doing so, the sharp boundary of the building could be preserved. Experiments are conducted on selected Aerial Imagery for Roof Segmentation (AIRS) dataset, and our method achieves better performance in both quantitative and qualitative results with comparison to the state-of-the-art methods. Our network is a bottom-up instance segmentation method that could well preserve geometric details.