 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADSEL: Adaptive dual self-expression learning for EEG feature selection via incomplete multi-dimensional emotional tagging
Aug 07, 2025EEG based multi-dimension emotion recognition has attracted substantial research interest in human computer interfaces. However, the high dimensionality of EEG features, coupled with limited sample sizes, frequently leads to classifier overfitting and high computational complexity. Feature selection constitutes a critical strategy for mitigating these challenges. Most existing EEG feature selection methods assume complete multi-dimensional emotion labels. In practice, open acquisition environment, and the inherent subjectivity of emotion perception often result in incomplete label data, which can compromise model generalization. Additionally, existing feature selection methods for handling incomplete multi-dimensional labels primarily focus on correlations among various dimensions during label recovery, neglecting the correlation between samples in the label space and their interaction with various dimensions. To address these issues, we propose a novel incomplete multi-dimensional feature selection algorithm for EEG-based emotion recognition. The proposed method integrates an adaptive dual self-expression learning (ADSEL) with least squares regression. ADSEL establishes a bidirectional pathway between sample-level and dimension-level self-expression learning processes within the label space. It could facilitate the cross-sharing of learned information between these processes, enabling the simultaneous exploitation of effective information across both samples and dimensions for label reconstruction. Consequently, ADSEL could enhances label recovery accuracy and effectively identifies the optimal EEG feature subset for multi-dimensional emotion recognition.
FDC-Net: Rethinking the association between EEG artifact removal and multi-dimensional affective computing
Aug 07, 2025
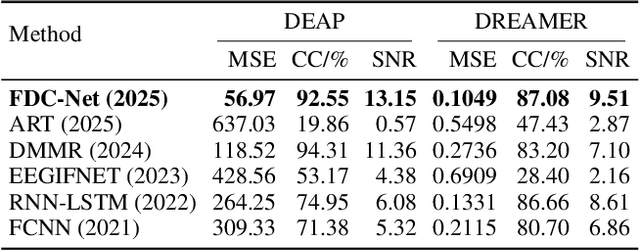


Electroencephalogram (EEG)-based emotion recognition holds significant value in affective computing and brain-computer interfaces. However, in practical applications, EEG recordings are susceptible to the effects of various physiological artifacts. Current approaches typically treat denoising and emotion recognition as independent tasks using cascaded architectures, which not only leads to error accumulation, but also fails to exploit potential synergies between these tasks. Moreover, conventional EEG-based emotion recognition models often rely on the idealized assumption of "perfectly denoised data", lacking a systematic design for noise robustness. To address these challenges, a novel framework that deeply couples denoising and emotion recognition tasks is proposed for end-to-end noise-robust emotion recognition, termed as Feedback-Driven Collaborative Network for Denoising-Classification Nexus (FDC-Net). Our primary innovation lies in establishing a dynamic collaborative mechanism between artifact removal and emotion recognition through: (1) bidirectional gradient propagation with joint optimization strategies; (2) a gated attention mechanism integrated with frequency-adaptive Transformer using learnable band-position encoding. Two most popular EEG-based emotion datasets (DEAP and DREAMER) with multi-dimensional emotional labels were employed to compare the artifact removal and emotion recognition performance between ASLSL and nine state-of-the-art methods. In terms of the denoising task, FDC-Net obtains a maximum correlation coefficient (CC) value of 96.30% on DEAP and a maximum CC value of 90.31% on DREAMER. In terms of the emotion recognition task under physiological artifact interference, FDC-Net achieves emotion recognition accuracies of 82.3+7.1% on DEAP and 88.1+0.8% on DREAMER.
AI-Enhanced 7-Point Checklist for Melanoma Detection Using Clinical Knowledge Graphs and Data-Driven Quantification
Jul 23, 2024



The 7-point checklist (7PCL) is widely used in dermoscopy to identify malignant melanoma lesions needing urgent medical attention. It assigns point values to seven attributes: major attributes are worth two points each, and minor ones are worth one point each. A total score of three or higher prompts further evaluation, often including a biopsy. However, a significant limitation of current methods is the uniform weighting of attributes, which leads to imprecision and neglects their interconnections. Previous deep learning studies have treated the prediction of each attribute with the same importance as predicting melanoma, which fails to recognize the clinical significance of the attributes for melanoma. To address these limitations, we introduce a novel diagnostic method that integrates two innovative elements: a Clinical Knowledge-Based Topological Graph (CKTG) and a Gradient Diagnostic Strategy with Data-Driven Weighting Standards (GD-DDW). The CKTG integrates 7PCL attributes with diagnostic information, revealing both internal and external associations. By employing adaptive receptive domains and weighted edges, we establish connections among melanoma's relevant features. Concurrently, GD-DDW emulates dermatologists' diagnostic processes, who first observe the visual characteristics associated with melanoma and then make predictions. Our model uses two imaging modalities for the same lesion, ensuring comprehensive feature acquisition. Our method shows outstanding performance in predicting malignant melanoma and its features, achieving an average AUC value of 85%. This was validated on the EDRA dataset, the largest publicly available dataset for the 7-point checklist algorithm. Specifically, the integrated weighting system can provide clinicians with valuable data-driven benchmarks for their evaluations.
Rethinking Crowdsourcing Annotation: Partial Annotation with Salient Labels for Multi-Label Image Classification
Sep 06, 2021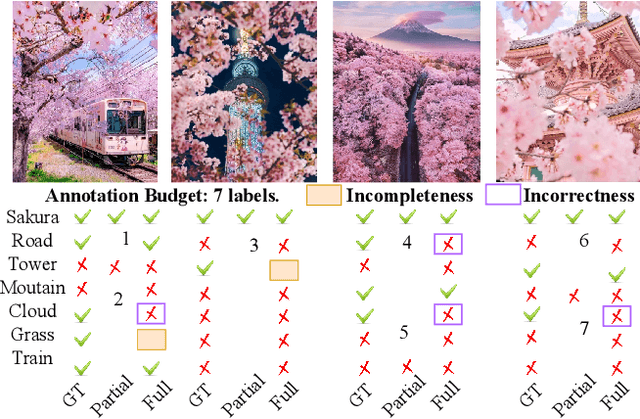
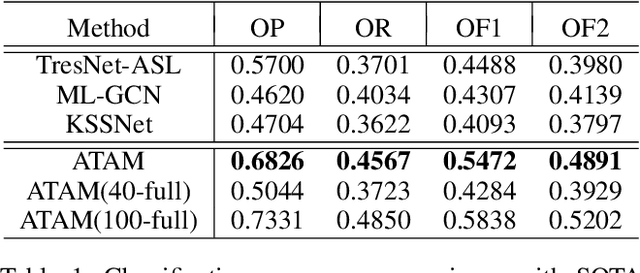
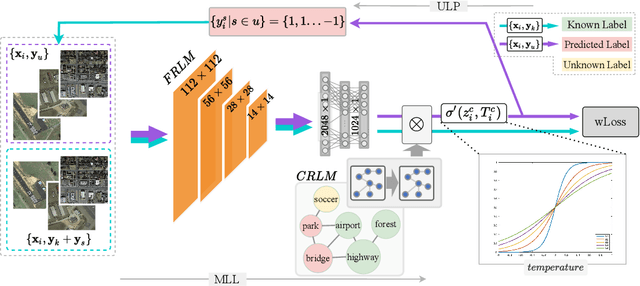
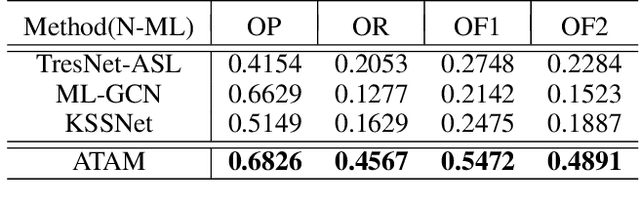
Annotated images are required for both supervised model training and evaluation in image classification. Manually annotating images is arduous and expensive, especially for multi-labeled images. A recent trend for conducting such laboursome annotation tasks is through crowdsourcing, where images are annotated by volunteers or paid workers online (e.g., workers of Amazon Mechanical Turk) from scratch. However, the quality of crowdsourcing image annotations cannot be guaranteed, and incompleteness and incorrectness are two major concerns for crowdsourcing annotations. To address such concerns, we have a rethinking of crowdsourcing annotations: Our simple hypothesis is that if the annotators only partially annotate multi-label images with salient labels they are confident in, there will be fewer annotation errors and annotators will spend less time on uncertain labels. As a pleasant surprise, with the same annotation budget, we show a multi-label image classifier supervised by images with salient annotations can outperform models supervised by fully annotated images. Our method contributions are 2-fold: An active learning way is proposed to acquire salient labels for multi-label images; and a novel Adaptive Temperature Associated Model (ATAM) specifically using partial annotations is proposed for multi-label image classification. We conduct experiments on practical crowdsourcing data, the Open Street Map (OSM) dataset and benchmark dataset COCO 2014. When compared with state-of-the-art classification methods trained on fully annotated images, the proposed ATAM can achieve higher accuracy. The proposed idea is promising for crowdsourcing data annotation. Our code will be publicly available.
SCIDA: Self-Correction Integrated Domain Adaptation from Single- to Multi-label Aerial Images
Aug 15, 2021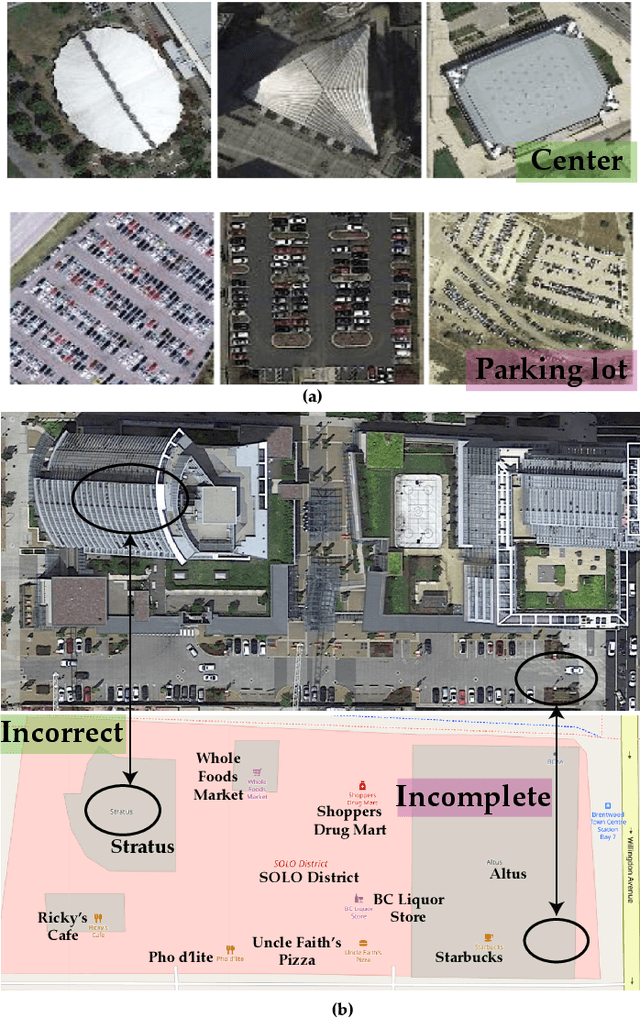
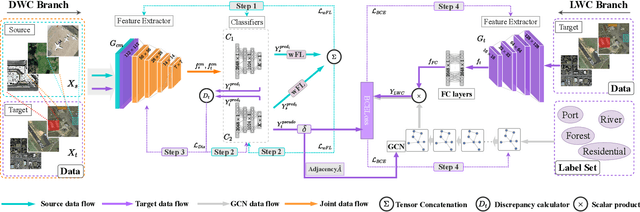
Most publicly available datasets for image classification are with single labels, while images are inherently multi-labeled in our daily life. Such an annotation gap makes many pre-trained single-label classification models fail in practical scenarios. This annotation issue is more concerned for aerial images: Aerial data collected from sensors naturally cover a relatively large land area with multiple labels, while annotated aerial datasets, which are publicly available (e.g., UCM, AID), are single-labeled. As manually annotating multi-label aerial images would be time/labor-consuming, we propose a novel self-correction integrated domain adaptation (SCIDA) method for automatic multi-label learning. SCIDA is weakly supervised, i.e., automatically learning the multi-label image classification model from using massive, publicly available single-label images. To achieve this goal, we propose a novel Label-Wise self-Correction (LWC) module to better explore underlying label correlations. This module also makes the unsupervised domain adaptation (UDA) from single- to multi-label data possible. For model training, the proposed model only uses single-label information yet requires no prior knowledge of multi-labeled data; and it predicts labels for multi-label aerial images. In our experiments, trained with single-labeled MAI-AID-s and MAI-UCM-s datasets, the proposed model is tested directly on our collected Multi-scene Aerial Image (MAI) dataset.