 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposed Vision-Language Retrieval for Skin Cancer Case Search via Joint Alignment of Global and Local Representations
Mar 10, 2026Medical image retrieval aims to identify clinically relevant lesion cases to support diagnostic decision making, education, and quality control. In practice, retrieval queries often combine a reference lesion image with textual descriptors such as dermoscopic features. We study composed vision-language retrieval for skin cancer, where each query consists of an image to text pair and the database contains biopsy-confirmed, multi-class disease cases. We propose a transformer based framework that learns hierarchical composed query representations and performs joint global-local alignment between queries and candidate images. Local alignment aggregates discriminative regions via multiple spatial attention masks, while global alignment provides holistic semantic supervision. The final similarity is computed through a convex, domain-informed weighting that emphasizes clinically salient local evidence while preserving global consistency. Experiments on the public Derm7pt dataset demonstrate consistent improvements over state-of-the-art methods. The proposed framework enables efficient access to relevant medical records and supports practical clinical deployment.
Towards a Science of Collective AI: LLM-based Multi-Agent Systems Need a Transition from Blind Trial-and-Error to Rigorous Science
Feb 05, 2026Recent advancements in Large Language Models (LLMs) have greatly extended the capabilities of Multi-Agent Systems (MAS), demonstrating significant effectiveness across a wide range of complex and open-ended domains. However, despite this rapid progress, the field still relies heavily on empirical trial-and-error. It lacks a unified and principled scientific framework necessary for systematic optimization and improvement. This bottleneck stems from the ambiguity of attribution: first, the absence of a structured taxonomy of factors leaves researchers restricted to unguided adjustments; second, the lack of a unified metric fails to distinguish genuine collaboration gain from mere resource accumulation. In this paper, we advocate for a transition to design science through an integrated framework. We advocate to establish the collaboration gain metric ($Γ$) as the scientific standard to isolate intrinsic gains from increased budgets. Leveraging $Γ$, we propose a factor attribution paradigm to systematically identify collaboration-driving factors. To support this, we construct a systematic MAS factor library, structuring the design space into control-level presets and information-level dynamics. Ultimately, this framework facilitates the transition from blind experimentation to rigorous science, paving the way towards a true science of Collective AI.
AgentXRay: White-Boxing Agentic Systems via Workflow Reconstruction
Feb 05, 2026Large Language Models have shown strong capabilities in complex problem solving, yet many agentic systems remain difficult to interpret and control due to opaque internal workflows. While some frameworks offer explicit architectures for collaboration, many deployed agentic systems operate as black boxes to users. We address this by introducing Agentic Workflow Reconstruction (AWR), a new task aiming to synthesize an explicit, interpretable stand-in workflow that approximates a black-box system using only input--output access. We propose AgentXRay, a search-based framework that formulates AWR as a combinatorial optimization problem over discrete agent roles and tool invocations in a chain-structured workflow space. Unlike model distillation, AgentXRay produces editable white-box workflows that match target outputs under an observable, output-based proxy metric, without accessing model parameters. To navigate the vast search space, AgentXRay employs Monte Carlo Tree Search enhanced by a scoring-based Red-Black Pruning mechanism, which dynamically integrates proxy quality with search depth. Experiments across diverse domains demonstrate that AgentXRay achieves higher proxy similarity and reduces token consumption compared to unpruned search, enabling deeper workflow exploration under fixed iteration budgets.
Coupled Flow Matching
Oct 27, 2025We introduce Coupled Flow Matching (CPFM), a framework that integrates controllable dimensionality reduction and high-fidelity reconstruction. CPFM learns coupled continuous flows for both the high-dimensional data x and the low-dimensional embedding y, which enables sampling p(y|x) via a latent-space flow and p(x|y) via a data-space flow. Unlike classical dimension-reduction methods, where information discarded during compression is often difficult to recover, CPFM preserves the knowledge of residual information within the weights of a flow network. This design provides bespoke controllability: users may decide which semantic factors to retain explicitly in the latent space, while the complementary information remains recoverable through the flow network. Coupled flow matching builds on two components: (i) an extended Gromov-Wasserstein optimal transport objective that establishes a probabilistic correspondence between data and embeddings, and (ii) a dual-conditional flow-matching network that extrapolates the correspondence to the underlying space. Experiments on multiple benchmarks show that CPFM yields semantically rich embeddings and reconstructs data with higher fidelity than existing baselines.
MemeCMD: An Automatically Generated Chinese Multi-turn Dialogue Dataset with Contextually Retrieved Memes
Jul 01, 2025Memes are widely used in online social interactions, providing vivid, intuitive, and often humorous means to express intentions and emotions. Existing dialogue datasets are predominantly limited to either manually annotated or pure-text conversations, lacking the expressiveness and contextual nuance that multimodal interactions provide.To address these challenges, we introduce MemeCMD, an automatically generated Chinese Multi-turn Dialogue dataset with contextually retrieved memes. Our dataset combines a large-scale, MLLM-annotated meme library with dialogues auto-generated by dual agents across diverse scenarios. We introduce a retrieval framework and adaptive threshold to ensure contextually relevant, naturally spaced meme usage. Experiments demonstrate the effectiveness of our approach in generating contextually appropriate and diverse meme-incorporated dialogues, offering a scalable and privacy-preserving resource for advancing multimodal conversational AI.
MAC-Gaze: Motion-Aware Continual Calibration for Mobile Gaze Tracking
May 28, 2025Mobile gaze tracking faces a fundamental challenge: maintaining accuracy as users naturally change their postures and device orientations. Traditional calibration approaches, like one-off, fail to adapt to these dynamic conditions, leading to degraded performance over time. We present MAC-Gaze, a Motion-Aware continual Calibration approach that leverages smartphone Inertial measurement unit (IMU) sensors and continual learning techniques to automatically detect changes in user motion states and update the gaze tracking model accordingly. Our system integrates a pre-trained visual gaze estimator and an IMU-based activity recognition model with a clustering-based hybrid decision-making mechanism that triggers recalibration when motion patterns deviate significantly from previously encountered states. To enable accumulative learning of new motion conditions while mitigating catastrophic forgetting, we employ replay-based continual learning, allowing the model to maintain performance across previously encountered motion conditions. We evaluate our system through extensive experiments on the publicly available RGBDGaze dataset and our own 10-hour multimodal MotionGaze dataset (481K+ images, 800K+ IMU readings), encompassing a wide range of postures under various motion conditions including sitting, standing, lying, and walking. Results demonstrate that our method reduces gaze estimation error by 19.9% on RGBDGaze (from 1.73 cm to 1.41 cm) and by 31.7% on MotionGaze (from 2.81 cm to 1.92 cm) compared to traditional calibration approaches. Our framework provides a robust solution for maintaining gaze estimation accuracy in mobile scenarios.
Approximate Maximum Likelihood Inference for Acoustic Spatial Capture-Recapture with Unknown Identities, Using Monte Carlo Expectation Maximization
Oct 06, 2024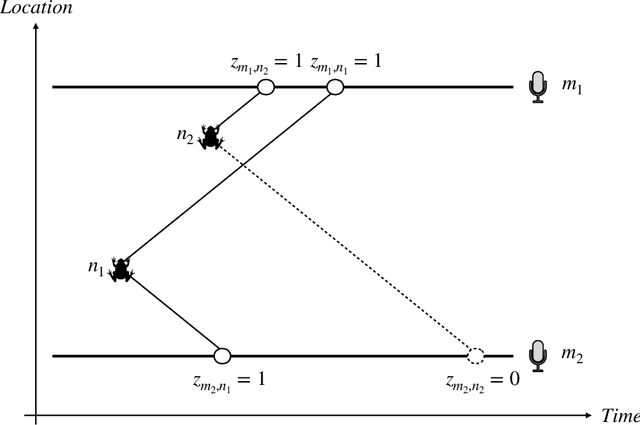
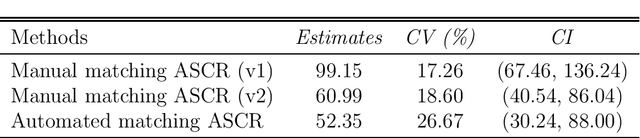
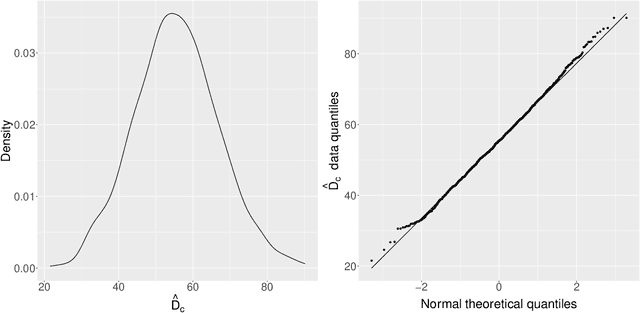

Acoustic spatial capture-recapture (ASCR) surveys with an array of synchronized acoustic detectors can be an effective way of estimating animal density or call density. However, constructing the capture histories required for ASCR analysis is challenging, as recognizing which detections at different detectors are of which calls is not a trivial task. Because calls from different distances take different times to arrive at detectors, the order in which calls are detected is not necessarily the same as the order in which they are made, and without knowing which detections are of the same call, we do not know how many different calls are detected. We propose a Monte Carlo expectation-maximization (MCEM) estimation method to resolve this unknown call identity problem. To implement the MCEM method in this context, we sample the latent variables from a complete-data likelihood model in the expectation step and use a semi-complete-data likelihood or conditional likelihood in the maximization step. We use a parametric bootstrap to obtain confidence intervals. When we apply our method to a survey of moss frogs, it gives an estimate within 15% of the estimate obtained using data with call capture histories constructed by experts, and unlike this latter estimate, our confidence interval incorporates the uncertainty about call identities. Simulations show it to have a low bias (6%) and coverage probabilities close to the nominal 95% value.
AI-Enhanced 7-Point Checklist for Melanoma Detection Using Clinical Knowledge Graphs and Data-Driven Quantification
Jul 23, 2024



The 7-point checklist (7PCL) is widely used in dermoscopy to identify malignant melanoma lesions needing urgent medical attention. It assigns point values to seven attributes: major attributes are worth two points each, and minor ones are worth one point each. A total score of three or higher prompts further evaluation, often including a biopsy. However, a significant limitation of current methods is the uniform weighting of attributes, which leads to imprecision and neglects their interconnections. Previous deep learning studies have treated the prediction of each attribute with the same importance as predicting melanoma, which fails to recognize the clinical significance of the attributes for melanoma. To address these limitations, we introduce a novel diagnostic method that integrates two innovative elements: a Clinical Knowledge-Based Topological Graph (CKTG) and a Gradient Diagnostic Strategy with Data-Driven Weighting Standards (GD-DDW). The CKTG integrates 7PCL attributes with diagnostic information, revealing both internal and external associations. By employing adaptive receptive domains and weighted edges, we establish connections among melanoma's relevant features. Concurrently, GD-DDW emulates dermatologists' diagnostic processes, who first observe the visual characteristics associated with melanoma and then make predictions. Our model uses two imaging modalities for the same lesion, ensuring comprehensive feature acquisition. Our method shows outstanding performance in predicting malignant melanoma and its features, achieving an average AUC value of 85%. This was validated on the EDRA dataset, the largest publicly available dataset for the 7-point checklist algorithm. Specifically, the integrated weighting system can provide clinicians with valuable data-driven benchmarks for their evaluations.
Towards Automated Animal Density Estimation with Acoustic Spatial Capture-Recapture
Aug 24, 2023



Passive acoustic monitoring can be an effective way of monitoring wildlife populations that are acoustically active but difficult to survey visually. Digital recorders allow surveyors to gather large volumes of data at low cost, but identifying target species vocalisations in these data is non-trivial. Machine learning (ML) methods are often used to do the identification. They can process large volumes of data quickly, but they do not detect all vocalisations and they do generate some false positives (vocalisations that are not from the target species). Existing wildlife abundance survey methods have been designed specifically to deal with the first of these mistakes, but current methods of dealing with false positives are not well-developed. They do not take account of features of individual vocalisations, some of which are more likely to be false positives than others. We propose three methods for acoustic spatial capture-recapture inference that integrate individual-level measures of confidence from ML vocalisation identification into the likelihood and hence integrate ML uncertainty into inference. The methods include a mixture model in which species identity is a latent variable. We test the methods by simulation and find that in a scenario based on acoustic data from Hainan gibbons, in which ignoring false positives results in 17% positive bias, our methods give negligible bias and coverage probabilities that are close to the nominal 95% level.
Knowledge Authoring for Rules and Actions
May 12, 2023Knowledge representation and reasoning (KRR) systems describe and reason with complex concepts and relations in the form of facts and rules. Unfortunately, wide deployment of KRR systems runs into the problem that domain experts have great difficulty constructing correct logical representations of their domain knowledge. Knowledge engineers can help with this construction process, but there is a deficit of such specialists. The earlier Knowledge Authoring Logic Machine (KALM) based on Controlled Natural Language (CNL) was shown to have very high accuracy for authoring facts and questions. More recently, KALMFL, a successor of KALM, replaced CNL with factual English, which is much less restrictive and requires very little training from users. However, KALMFL has limitations in representing certain types of knowledge, such as authoring rules for multi-step reasoning or understanding actions with timestamps. To address these limitations, we propose KALMRA to enable authoring of rules and actions. Our evaluation using the UTI guidelines benchmark shows that KALMRA achieves a high level of correctness (100%) on rule authoring. When used for authoring and reasoning with actions, KALMRA achieves more than 99.3% correctness on the bAbI benchmark, demonstrating its effectiveness in more sophisticated KRR jobs. Finally, we illustrate the logical reasoning capabilities of KALMRA by drawing attention to the problems faced by the recently made famous AI, ChatGPT.