 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Authoring for Rules and Actions
May 12, 2023Knowledge representation and reasoning (KRR) systems describe and reason with complex concepts and relations in the form of facts and rules. Unfortunately, wide deployment of KRR systems runs into the problem that domain experts have great difficulty constructing correct logical representations of their domain knowledge. Knowledge engineers can help with this construction process, but there is a deficit of such specialists. The earlier Knowledge Authoring Logic Machine (KALM) based on Controlled Natural Language (CNL) was shown to have very high accuracy for authoring facts and questions. More recently, KALMFL, a successor of KALM, replaced CNL with factual English, which is much less restrictive and requires very little training from users. However, KALMFL has limitations in representing certain types of knowledge, such as authoring rules for multi-step reasoning or understanding actions with timestamps. To address these limitations, we propose KALMRA to enable authoring of rules and actions. Our evaluation using the UTI guidelines benchmark shows that KALMRA achieves a high level of correctness (100%) on rule authoring. When used for authoring and reasoning with actions, KALMRA achieves more than 99.3% correctness on the bAbI benchmark, demonstrating its effectiveness in more sophisticated KRR jobs. Finally, we illustrate the logical reasoning capabilities of KALMRA by drawing attention to the problems faced by the recently made famous AI, ChatGPT.
Knowledge Authoring with Factual English
Aug 05, 2022
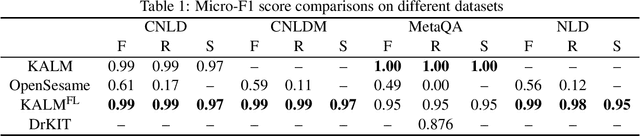

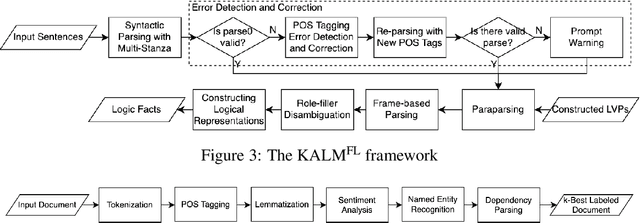
Knowledge representation and reasoning (KRR) systems represent knowledge as collections of facts and rules. Like databases, KRR systems contain information about domains of human activities like industrial enterprises, science, and business. KRRs can represent complex concepts and relations, and they can query and manipulate information in sophisticated ways. Unfortunately, the KRR technology has been hindered by the fact that specifying the requisite knowledge requires skills that most domain experts do not have, and professional knowledge engineers are hard to find. One solution could be to extract knowledge from English text, and a number of works have attempted to do so (OpenSesame, Google's Sling, etc.). Unfortunately, at present, extraction of logical facts from unrestricted natural language is still too inaccurate to be used for reasoning, while restricting the grammar of the language (so-called controlled natural language, or CNL) is hard for the users to learn and use. Nevertheless, some recent CNL-based approaches, such as the Knowledge Authoring Logic Machine (KALM), have shown to have very high accuracy compared to others, and a natural question is to what extent the CNL restrictions can be lifted. In this paper, we address this issue by transplanting the KALM framework to a neural natural language parser, mStanza. Here we limit our attention to authoring facts and queries and therefore our focus is what we call factual English statements. Authoring other types of knowledge, such as rules, will be considered in our followup work. As it turns out, neural network based parsers have problems of their own and the mistakes they make range from part-of-speech tagging to lemmatization to dependency errors. We present a number of techniques for combating these problems and test the new system, KALMFL (i.e., KALM for factual language), on a number of benchmarks, which show KALMFL achieves correctness in excess of 95%.
* In Proceedings ICLP 2022, arXiv:2208.02685
Querying Knowledge via Multi-Hop English Questions
Jul 18, 2019
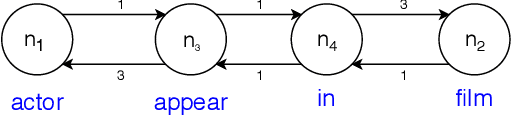
The inherent difficulty of knowledge specification and the lack of trained specialists are some of the key obstacles on the way to making intelligent systems based on the knowledge representation and reasoning (KRR) paradigm commonplace. Knowledge and query authoring using natural language, especially controlled natural language (CNL), is one of the promising approaches that could enable domain experts, who are not trained logicians, to both create formal knowledge and query it. In previous work, we introduced the KALM system (Knowledge Authoring Logic Machine) that supports knowledge authoring (and simple querying) with very high accuracy that at present is unachievable via machine learning approaches. The present paper expands on the question answering aspect of KALM and introduces KALM-QA (KALM for Question Answering) that is capable of answering much more complex English questions. We show that KALM-QA achieves 100% accuracy on an extensive suite of movie-related questions, called MetaQA, which contains almost 29,000 test questions and over 260,000 training questions. We contrast this with a published machine learning approach, which falls far short of this high mark.
Paraconsistency and Word Puzzles
Aug 05, 2016Word puzzles and the problem of their representations in logic languages have received considerable attention in the last decade (Ponnuru et al. 2004; Shapiro 2011; Baral and Dzifcak 2012; Schwitter 2013). Of special interest is the problem of generating such representations directly from natural language (NL) or controlled natural language (CNL). An interesting variation of this problem, and to the best of our knowledge, scarcely explored variation in this context, is when the input information is inconsistent. In such situations, the existing encodings of word puzzles produce inconsistent representations and break down. In this paper, we bring the well-known type of paraconsistent logics, called Annotated Predicate Calculus (APC) (Kifer and Lozinskii 1992), to bear on the problem. We introduce a new kind of non-monotonic semantics for APC, called consistency preferred stable models and argue that it makes APC into a suitable platform for dealing with inconsistency in word puzzles and, more generally, in NL sentences. We also devise a number of general principles to help the user choose among the different representations of NL sentences, which might seem equivalent but, in fact, behave differently when inconsistent information is taken into account. These principles can be incorporated into existing CNL translators, such as Attempto Controlled English (ACE) (Fuchs et al. 2008) and PENG Light (White and Schwitter 2009). Finally, we show that APC with the consistency preferred stable model semantics can be equivalently embedded in ASP with preferences over stable models, and we use this embedding to implement this version of APC in Clingo (Gebser et al. 2011) and its Asprin add-on (Brewka et al. 2015).