 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinZero: Launching Multi-modal Financial Time Series Forecast with Large Reasoning Model
Sep 10, 2025Financial time series forecasting is both highly significant and challenging. Previous approaches typically standardized time series data before feeding it into forecasting models, but this encoding process inherently leads to a loss of important information. Moreover, past time series models generally require fixed numbers of variables or lookback window lengths, which further limits the scalability of time series forecasting. Besides, the interpretability and the uncertainty in forecasting remain areas requiring further research, as these factors directly impact the reliability and practical value of predictions. To address these issues, we first construct a diverse financial image-text dataset (FVLDB) and develop the Uncertainty-adjusted Group Relative Policy Optimization (UARPO) method to enable the model not only output predictions but also analyze the uncertainty of those predictions. We then proposed FinZero, a multimodal pre-trained model finetuned by UARPO to perform reasoning, prediction, and analytical understanding on the FVLDB financial time series. Extensive experiments validate that FinZero exhibits strong adaptability and scalability. After fine-tuning with UARPO, FinZero achieves an approximate 13.48\% improvement in prediction accuracy over GPT-4o in the high-confidence group, demonstrating the effectiveness of reinforcement learning fine-tuning in multimodal large model, including in financial time series forecasting tasks.
FinTSBridge: A New Evaluation Suite for Real-world Financial Prediction with Advanced Time Series Models
Mar 10, 2025Despite the growing attention to time series forecasting in recent years, many studies have proposed various solutions to address the challenges encountered in time series prediction, aiming to improve forecasting performance. However, effectively applying these time series forecasting models to the field of financial asset pricing remains a challenging issue. There is still a need for a bridge to connect cutting-edge time series forecasting models with financial asset pricing. To bridge this gap, we have undertaken the following efforts: 1) We constructed three datasets from the financial domain; 2) We selected over ten time series forecasting models from recent studies and validated their performance in financial time series; 3) We developed new metrics, msIC and msIR, in addition to MSE and MAE, to showcase the time series correlation captured by the models; 4) We designed financial-specific tasks for these three datasets and assessed the practical performance and application potential of these forecasting models in important financial problems. We hope the developed new evaluation suite, FinTSBridge, can provide valuable insights into the effectiveness and robustness of advanced forecasting models in finanical domains.
MLRegTest: A Benchmark for the Machine Learning of Regular Languages
Apr 16, 2023
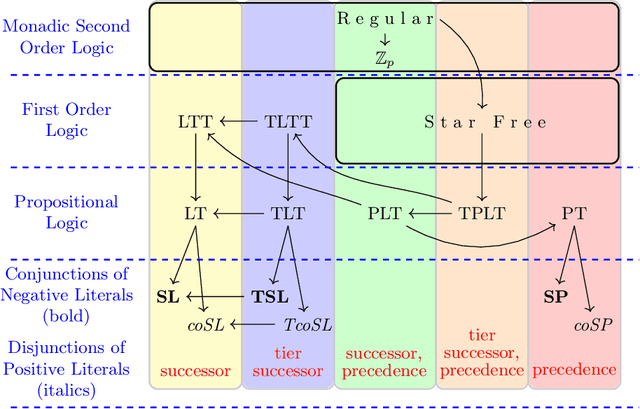
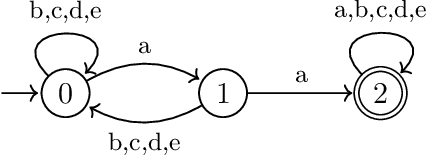
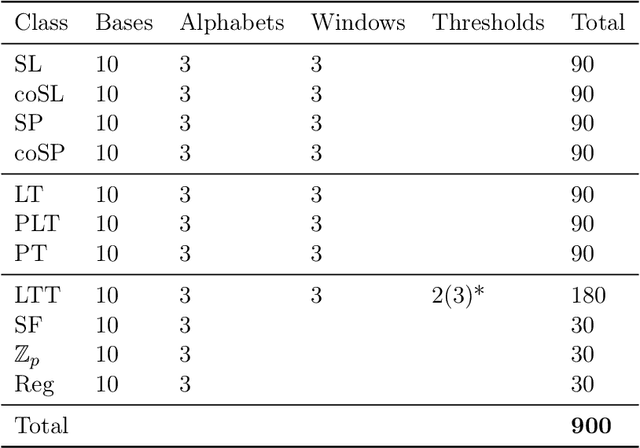
Evaluating machine learning (ML) systems on their ability to learn known classifiers allows fine-grained examination of the patterns they can learn, which builds confidence when they are applied to the learning of unknown classifiers. This article presents a new benchmark for ML systems on sequence classification called MLRegTest, which contains training, development, and test sets from 1,800 regular languages. Different kinds of formal languages represent different kinds of long-distance dependencies, and correctly identifying long-distance dependencies in sequences is a known challenge for ML systems to generalize successfully. MLRegTest organizes its languages according to their logical complexity (monadic second order, first order, propositional, or monomial expressions) and the kind of logical literals (string, tier-string, subsequence, or combinations thereof). The logical complexity and choice of literal provides a systematic way to understand different kinds of long-distance dependencies in regular languages, and therefore to understand the capacities of different ML systems to learn such long-distance dependencies. Finally, the performance of different neural networks (simple RNN, LSTM, GRU, transformer) on MLRegTest is examined. The main conclusion is that their performance depends significantly on the kind of test set, the class of language, and the neural network architecture.
Querying Knowledge via Multi-Hop English Questions
Jul 18, 2019
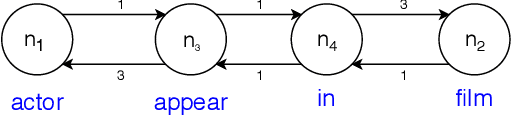
The inherent difficulty of knowledge specification and the lack of trained specialists are some of the key obstacles on the way to making intelligent systems based on the knowledge representation and reasoning (KRR) paradigm commonplace. Knowledge and query authoring using natural language, especially controlled natural language (CNL), is one of the promising approaches that could enable domain experts, who are not trained logicians, to both create formal knowledge and query it. In previous work, we introduced the KALM system (Knowledge Authoring Logic Machine) that supports knowledge authoring (and simple querying) with very high accuracy that at present is unachievable via machine learning approaches. The present paper expands on the question answering aspect of KALM and introduces KALM-QA (KALM for Question Answering) that is capable of answering much more complex English questions. We show that KALM-QA achieves 100% accuracy on an extensive suite of movie-related questions, called MetaQA, which contains almost 29,000 test questions and over 260,000 training questions. We contrast this with a published machine learning approach, which falls far short of this high mark.
Controlled Natural Languages and Default Reasoning
May 11, 2019



Controlled natural languages (CNLs) are effective languages for knowledge representation and reasoning. They are designed based on certain natural languages with restricted lexicon and grammar. CNLs are unambiguous and simple as opposed to their base languages. They preserve the expressiveness and coherence of natural languages. In this report, we focus on a class of CNLs, called machine-oriented CNLs, which have well-defined semantics that can be deterministically translated into formal languages, such as Prolog, to do logical reasoning. Over the past 20 years, a number of machine-oriented CNLs emerged and have been used in many application domains for problem solving and question answering. However, few of them support non-monotonic inference. In our work, we propose non-monotonic extensions of CNL to support defeasible reasoning. In the first part of this report, we survey CNLs and compare three influential systems: Attempto Controlled English (ACE), Processable English (PENG), and Computer-processable English (CPL). We compare their language design, semantic interpretations, and reasoning services. In the second part of this report, we first identify typical non-monotonicity in natural languages, such as defaults, exceptions and conversational implicatures. Then, we propose their representation in CNL and the corresponding formalizations in a form of defeasible reasoning known as Logic Programming with Defaults and Argumentation Theory (LPDA).
KALM: A Rule-based Approach for Knowledge Authoring and Question Answering
May 02, 2019

Knowledge representation and reasoning (KRR) is one of the key areas in artificial intelligence (AI) field. It is intended to represent the world knowledge in formal languages (e.g., Prolog, SPARQL) and then enhance the expert systems to perform querying and inference tasks. Currently, constructing large scale knowledge bases (KBs) with high quality is prohibited by the fact that the construction process requires many qualified knowledge engineers who not only understand the domain-specific knowledge but also have sufficient skills in knowledge representation. Unfortunately, qualified knowledge engineers are in short supply. Therefore, it would be very useful to build a tool that allows the user to construct and query the KB simply via text. Although there is a number of systems developed for knowledge extraction and question answering, they mainly fail in that these system don't achieve high enough accuracy whereas KRR is highly sensitive to erroneous data. In this thesis proposal, I will present Knowledge Authoring Logic Machine (KALM), a rule-based system which allows the user to author knowledge and query the KB in text. The experimental results show that KALM achieved superior accuracy in knowledge authoring and question answering as compared to the state-of-the-art systems.
Paraconsistency and Word Puzzles
Aug 05, 2016Word puzzles and the problem of their representations in logic languages have received considerable attention in the last decade (Ponnuru et al. 2004; Shapiro 2011; Baral and Dzifcak 2012; Schwitter 2013). Of special interest is the problem of generating such representations directly from natural language (NL) or controlled natural language (CNL). An interesting variation of this problem, and to the best of our knowledge, scarcely explored variation in this context, is when the input information is inconsistent. In such situations, the existing encodings of word puzzles produce inconsistent representations and break down. In this paper, we bring the well-known type of paraconsistent logics, called Annotated Predicate Calculus (APC) (Kifer and Lozinskii 1992), to bear on the problem. We introduce a new kind of non-monotonic semantics for APC, called consistency preferred stable models and argue that it makes APC into a suitable platform for dealing with inconsistency in word puzzles and, more generally, in NL sentences. We also devise a number of general principles to help the user choose among the different representations of NL sentences, which might seem equivalent but, in fact, behave differently when inconsistent information is taken into account. These principles can be incorporated into existing CNL translators, such as Attempto Controlled English (ACE) (Fuchs et al. 2008) and PENG Light (White and Schwitter 2009). Finally, we show that APC with the consistency preferred stable model semantics can be equivalently embedded in ASP with preferences over stable models, and we use this embedding to implement this version of APC in Clingo (Gebser et al. 2011) and its Asprin add-on (Brewka et al. 2015).