 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAC-Gaze: Motion-Aware Continual Calibration for Mobile Gaze Tracking
May 28, 2025Mobile gaze tracking faces a fundamental challenge: maintaining accuracy as users naturally change their postures and device orientations. Traditional calibration approaches, like one-off, fail to adapt to these dynamic conditions, leading to degraded performance over time. We present MAC-Gaze, a Motion-Aware continual Calibration approach that leverages smartphone Inertial measurement unit (IMU) sensors and continual learning techniques to automatically detect changes in user motion states and update the gaze tracking model accordingly. Our system integrates a pre-trained visual gaze estimator and an IMU-based activity recognition model with a clustering-based hybrid decision-making mechanism that triggers recalibration when motion patterns deviate significantly from previously encountered states. To enable accumulative learning of new motion conditions while mitigating catastrophic forgetting, we employ replay-based continual learning, allowing the model to maintain performance across previously encountered motion conditions. We evaluate our system through extensive experiments on the publicly available RGBDGaze dataset and our own 10-hour multimodal MotionGaze dataset (481K+ images, 800K+ IMU readings), encompassing a wide range of postures under various motion conditions including sitting, standing, lying, and walking. Results demonstrate that our method reduces gaze estimation error by 19.9% on RGBDGaze (from 1.73 cm to 1.41 cm) and by 31.7% on MotionGaze (from 2.81 cm to 1.92 cm) compared to traditional calibration approaches. Our framework provides a robust solution for maintaining gaze estimation accuracy in mobile scenarios.
Do We Need Responsible XR? Drawing on Responsible AI to Inform Ethical Research and Practice into XRAI / the Metaverse
Apr 06, 2025This position paper for the CHI 2025 workshop "Everyday AR through AI-in-the-Loop" reflects on whether as a field HCI needs to define Responsible XR as a parallel to, and in conjunction with, Responsible AI, addressing the unique vulnerabilities posed by mass adoption of wearable AI-enabled AR glasses and XR devices that could enact AI-driven human perceptual augmentation.
IFTT-PIN: A Self-Calibrating PIN-Entry Method
Jul 02, 2024



Personalising an interface to the needs and preferences of a user often incurs additional interaction steps. In this paper, we demonstrate a novel method that enables the personalising of an interface without the need for explicit calibration procedures, via a process we call self-calibration. A second-order effect of self-calibration is that an outside observer cannot easily infer what a user is trying to achieve because they cannot interpret the user's actions. To explore this security angle, we developed IFTT-PIN (If This Then PIN) as the first self-calibrating PIN-entry method. When using IFTT-PIN, users are free to choose any button for any meaning without ever explicitly communicating their choice to the machine. IFTT-PIN infers both the user's PIN and their preferred button mapping at the same time. This paper presents the concept, implementation, and interactive demonstrations of IFTT-PIN, as well as an evaluation against shoulder surfing attacks. Our study (N=24) shows that by adding self-calibration to an existing PIN entry method, IFTT-PIN statistically significantly decreased PIN attack decoding rate by ca. 8.5 times (p=1.1e-9), while only decreasing the PIN entry encoding rate by ca. 1.4 times (p=0.02), leading to a positive security-usability trade-off. IFTT-PIN's entry rate significantly improved 21 days after first exposure (p=3.6e-6) to the method, suggesting self-calibrating interfaces are memorable despite using an initially undefined user interface. Self-calibration methods might lead to novel opportunities for interaction that are more inclusive and versatile, a potentially interesting challenge for the community. A short introductory video is available at https://youtu.be/pP5sfniNRns.
An End-to-End Review of Gaze Estimation and its Interactive Applications on Handheld Mobile Devices
Jun 30, 2023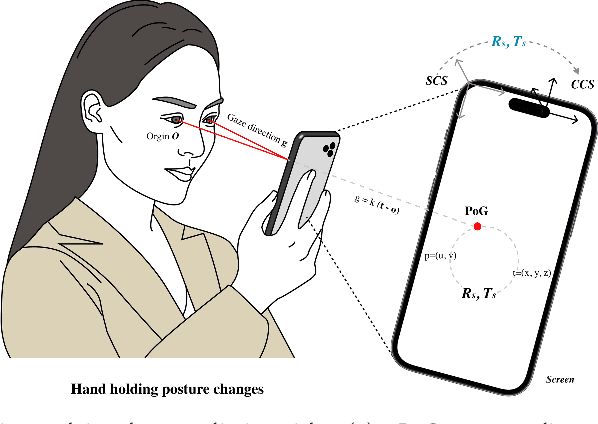
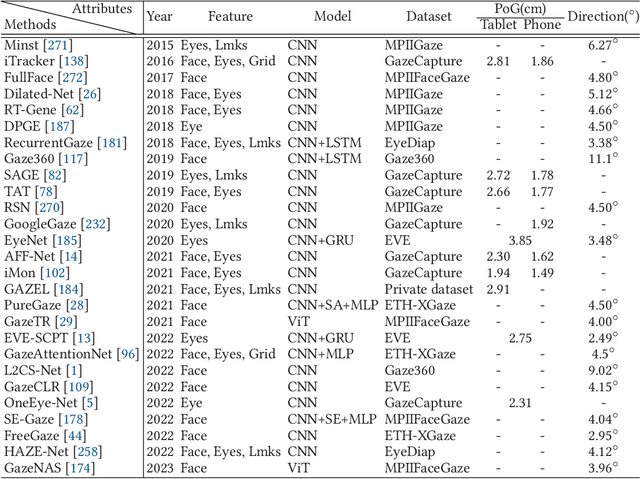


In recent years we have witnessed an increasing number of interactive systems on handheld mobile devices which utilise gaze as a single or complementary interaction modality. This trend is driven by the enhanced computational power of these devices, higher resolution and capacity of their cameras, and improved gaze estimation accuracy obtained from advanced machine learning techniques, especially in deep learning. As the literature is fast progressing, there is a pressing need to review the state of the art, delineate the boundary, and identify the key research challenges and opportunities in gaze estimation and interaction. This paper aims to serve this purpose by presenting an end-to-end holistic view in this area, from gaze capturing sensors, to gaze estimation workflows, to deep learning techniques, and to gaze interactive applications.
* 37 Pages, Paper accepted by ACM Computing Surveys
Deep learning is competing random forest in computational docking
Aug 23, 2016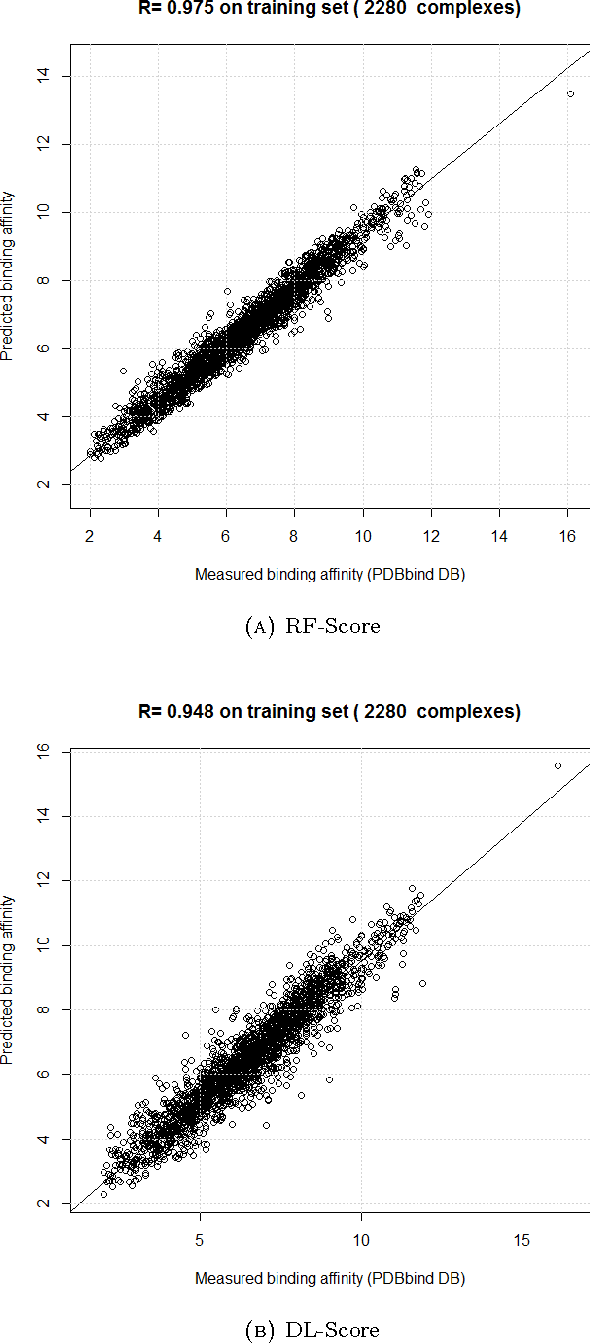

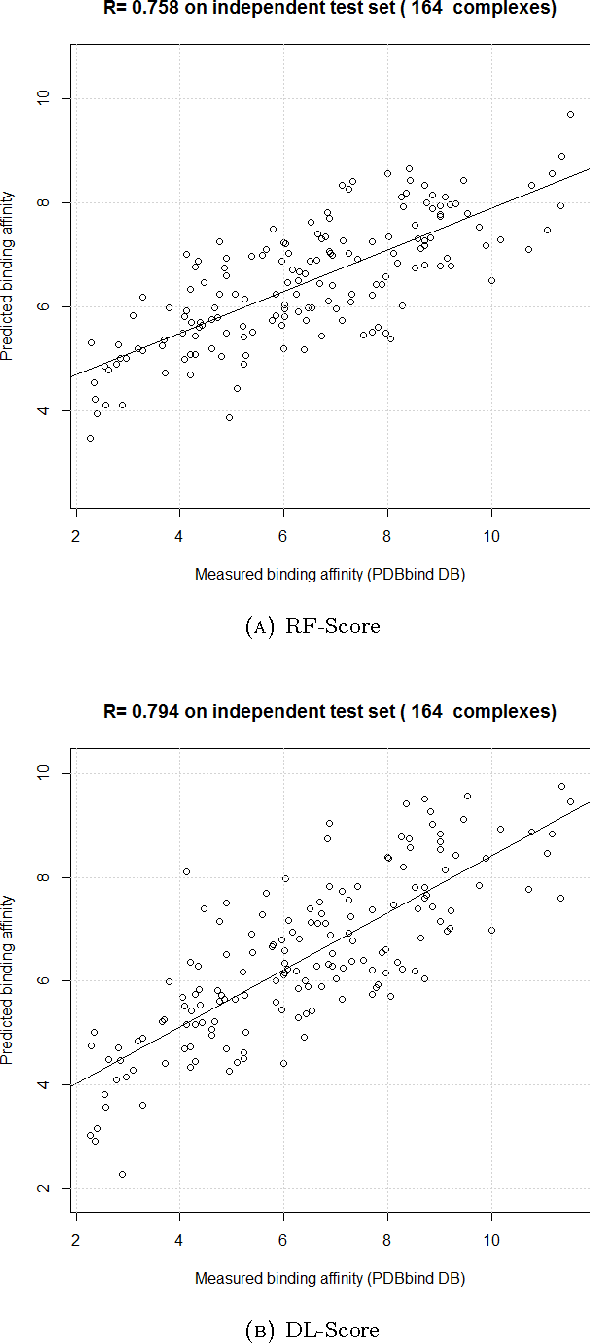
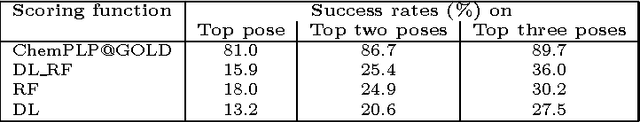
Computational docking is the core process of computer-aided drug design; it aims at predicting the best orientation and conformation of a small drug molecule when bound to a target large protein receptor. The docking quality is typically measured by a scoring function: a mathematical predictive model that produces a score representing the binding free energy and hence the stability of the resulting complex molecule. We analyze the performance of both learning techniques on the scoring power, the ranking power, docking power, and screening power using the PDBbind 2013 database. For the scoring and ranking powers, the proposed learning scoring functions depend on a wide range of features (energy terms, pharmacophore, intermolecular) that entirely characterize the protein-ligand complexes. For the docking and screening powers, the proposed learning scoring functions depend on the intermolecular features of the RF-Score to utilize a larger number of training complexes. For the scoring power, the DL\_RF scoring function achieves Pearson's correlation coefficient between the predicted and experimentally measured binding affinities of 0.799 versus 0.758 of the RF scoring function. For the ranking power, the DL scoring function ranks the ligands bound to fixed target protein with accuracy 54% for the high-level ranking and with accuracy 78% for the low-level ranking while the RF scoring function achieves (46% and 62%) respectively. For the docking power, the DL\_RF scoring function has a success rate when the three best-scored ligand binding poses are considered within 2 \AA\ root-mean-square-deviation from the native pose of 36.0% versus 30.2% of the RF scoring function. For the screening power, the DL scoring function has an average enrichment factor and success rate at the top 1% level of (2.69 and 6.45%) respectively versus (1.61 and 4.84%) respectively of the RF scoring function.