 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAG-MPBS: a Mobility-Aware Prediction and Behavior-Based Scheduling Framework for Air-Ground Unmanned Systems
Dec 18, 2025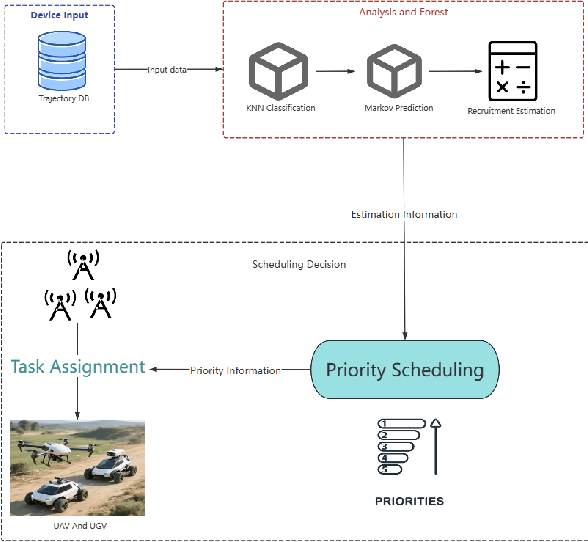
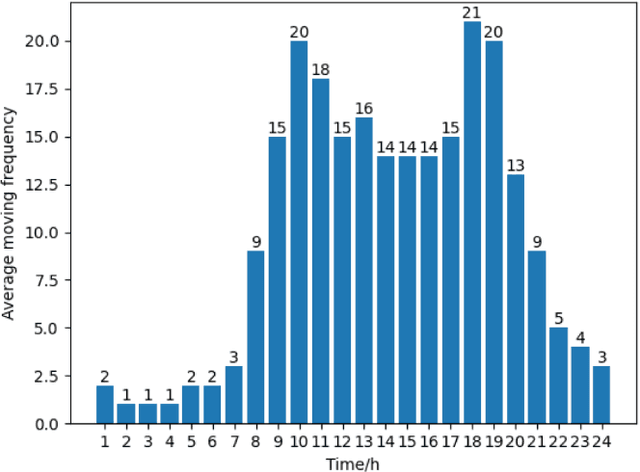
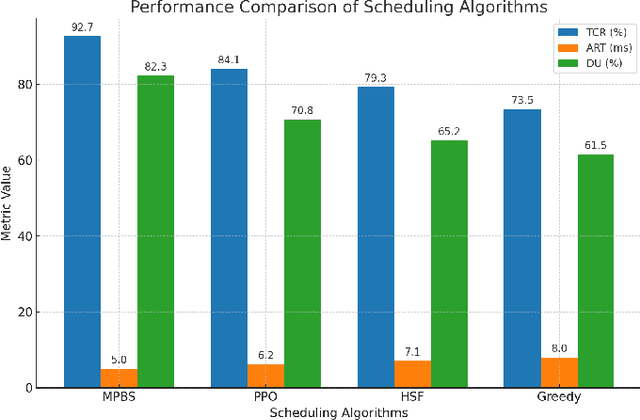
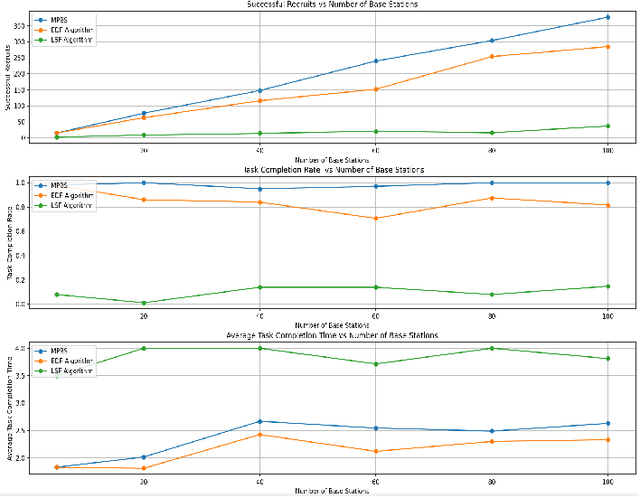
As unmanned systems such as Unmanned Aerial Vehicles (UAVs) and Unmanned Ground Vehicles (UGVs) become increasingly important to applications like urban sensing and emergency response, efficiently recruiting these autonomous devices to perform time-sensitive tasks has become a critical challenge. This paper presents MPBS (Mobility-aware Prediction and Behavior-based Scheduling), a scalable task recruitment framework that treats each device as a recruitable "user". MPBS integrates three key modules: a behavior-aware KNN classifier, a time-varying Markov prediction model for forecasting device mobility, and a dynamic priority scheduling mechanism that considers task urgency and base station performance. By combining behavioral classification with spatiotemporal prediction, MPBS adaptively assigns tasks to the most suitable devices in real time. Experimental evaluations on the real-world GeoLife dataset show that MPBS significantly improves task completion efficiency and resource utilization. The proposed framework offers a predictive, behavior-aware solution for intelligent and collaborative scheduling in unmanned systems.
Tri-Select: A Multi-Stage Visual Data Selection Framework for Mobile Visual Crowdsensing
Dec 18, 2025Mobile visual crowdsensing enables large-scale, fine-grained environmental monitoring through the collection of images from distributed mobile devices. However, the resulting data is often redundant and heterogeneous due to overlapping acquisition perspectives, varying resolutions, and diverse user behaviors. To address these challenges, this paper proposes Tri-Select, a multi-stage visual data selection framework that efficiently filters redundant and low-quality images. Tri-Select operates in three stages: (1) metadata-based filtering to discard irrelevant samples; (2) spatial similarity-based spectral clustering to organize candidate images; and (3) a visual-feature-guided selection based on maximum independent set search to retain high-quality, representative images. Experiments on real-world and public datasets demonstrate that Tri-Select improves both selection efficiency and dataset quality, making it well-suited for scalable crowdsensing applications.
MAC-Gaze: Motion-Aware Continual Calibration for Mobile Gaze Tracking
May 28, 2025Mobile gaze tracking faces a fundamental challenge: maintaining accuracy as users naturally change their postures and device orientations. Traditional calibration approaches, like one-off, fail to adapt to these dynamic conditions, leading to degraded performance over time. We present MAC-Gaze, a Motion-Aware continual Calibration approach that leverages smartphone Inertial measurement unit (IMU) sensors and continual learning techniques to automatically detect changes in user motion states and update the gaze tracking model accordingly. Our system integrates a pre-trained visual gaze estimator and an IMU-based activity recognition model with a clustering-based hybrid decision-making mechanism that triggers recalibration when motion patterns deviate significantly from previously encountered states. To enable accumulative learning of new motion conditions while mitigating catastrophic forgetting, we employ replay-based continual learning, allowing the model to maintain performance across previously encountered motion conditions. We evaluate our system through extensive experiments on the publicly available RGBDGaze dataset and our own 10-hour multimodal MotionGaze dataset (481K+ images, 800K+ IMU readings), encompassing a wide range of postures under various motion conditions including sitting, standing, lying, and walking. Results demonstrate that our method reduces gaze estimation error by 19.9% on RGBDGaze (from 1.73 cm to 1.41 cm) and by 31.7% on MotionGaze (from 2.81 cm to 1.92 cm) compared to traditional calibration approaches. Our framework provides a robust solution for maintaining gaze estimation accuracy in mobile scenarios.
MMFormer: Multimodal Transformer Using Multiscale Self-Attention for Remote Sensing Image Classification
Mar 23, 2023



To benefit the complementary information between heterogeneous data, we introduce a new Multimodal Transformer (MMFormer) for Remote Sensing (RS) image classification using Hyperspectral Image (HSI) accompanied by another source of data such as Light Detection and Ranging (LiDAR). Compared with traditional Vision Transformer (ViT) lacking inductive biases of convolutions, we first introduce convolutional layers to our MMFormer to tokenize patches from multimodal data of HSI and LiDAR. Then we propose a Multi-scale Multi-head Self-Attention (MSMHSA) module to address the problem of compatibility which often limits to fuse HSI with high spectral resolution and LiDAR with relatively low spatial resolution. The proposed MSMHSA module can incorporate HSI to LiDAR data in a coarse-to-fine manner enabling us to learn a fine-grained representation. Extensive experiments on widely used benchmarks (e.g., Trento and MUUFL) demonstrate the effectiveness and superiority of our proposed MMFormer for RS image classification.
Dynamic Multi-Task Learning for Face Recognition with Facial Expression
Nov 08, 2019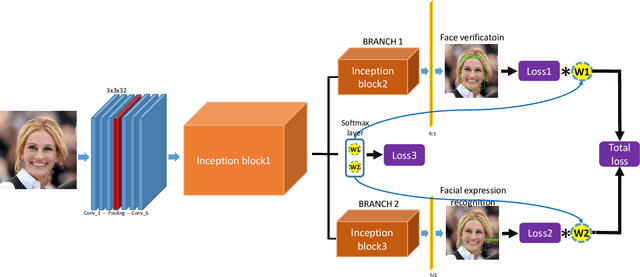

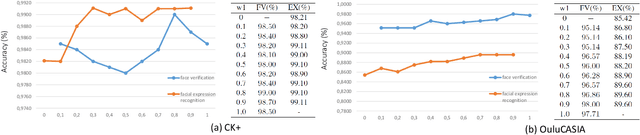
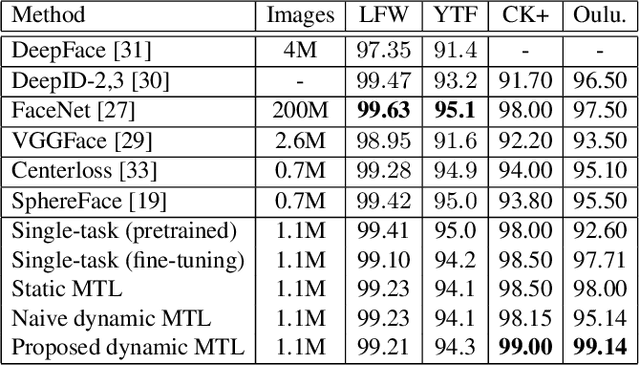
Benefiting from the joint learning of the multiple tasks in the deep multi-task networks, many applications have shown the promising performance comparing to single-task learning. However, the performance of multi-task learning framework is highly dependant on the relative weights of the tasks. How to assign the weight of each task is a critical issue in the multi-task learning. Instead of tuning the weights manually which is exhausted and time-consuming, in this paper we propose an approach which can dynamically adapt the weights of the tasks according to the difficulty for training the task. Specifically, the proposed method does not introduce the hyperparameters and the simple structure allows the other multi-task deep learning networks can easily realize or reproduce this method. We demonstrate our approach for face recognition with facial expression and facial expression recognition from a single input image based on a deep multi-task learning Conventional Neural Networks (CNNs). Both the theoretical analysis and the experimental results demonstrate the effectiveness of the proposed dynamic multi-task learning method. This multi-task learning with dynamic weights also boosts of the performance on the different tasks comparing to the state-of-art methods with single-task learning.
FaceLiveNet+: A Holistic Networks For Face Authentication Based On Dynamic Multi-task Convolutional Neural Networks
Feb 28, 2019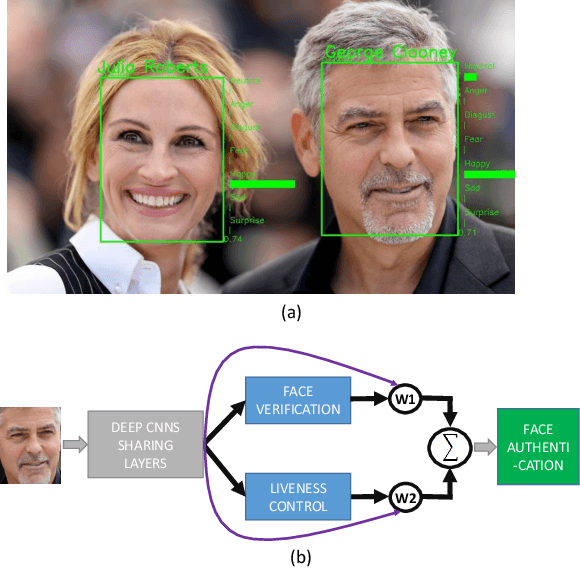

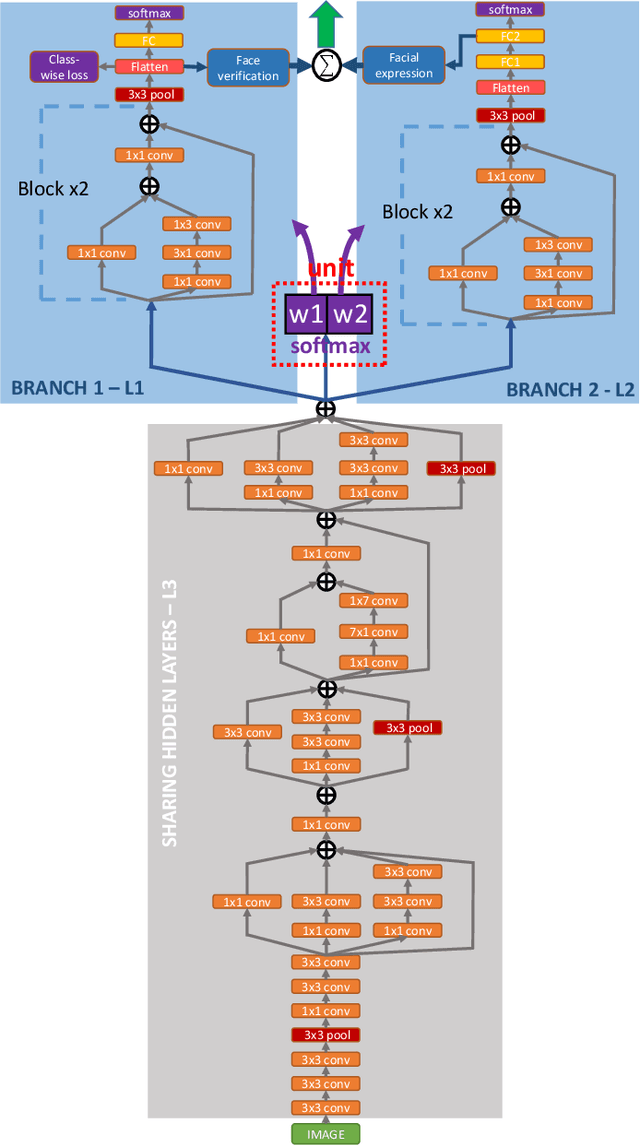
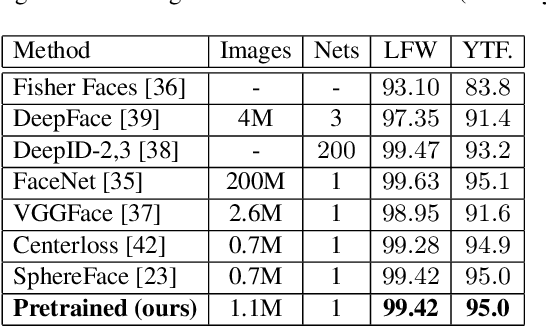
This paper proposes a holistic multi-task Convolutional Neural Networks (CNNs) with the dynamic weights of the tasks,namely FaceLiveNet+, for face authentication. FaceLiveNet+ can employ face verification and facial expression recognition as a solution of liveness control simultaneously. Comparing to the single-task learning, the proposed multi-task learning can better capture the feature representation for all of the tasks. The experimental results show the superiority of the multi-task learning to the single-task learning for both the face verification task and facial expression recognition task. Rather using a conventional multi-task learning with fixed weights for the tasks, this work proposes a so called dynamic-weight-unit to automatically learn the weights of the tasks. The experiments have shown the effectiveness of the dynamic weights for training the networks. Finally, the holistic evaluation for face authentication based on the proposed protocol has shown the feasibility to apply the FaceLiveNet+ for face authentication.