 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward accessible comics for blind and low vision readers
Jul 11, 2024This work explores how to fine-tune large language models using prompt engineering techniques with contextual information for generating an accurate text description of the full story, ready to be forwarded to off-the-shelve speech synthesis tools. We propose to use existing computer vision and optical character recognition techniques to build a grounded context from the comic strip image content, such as panels, characters, text, reading order and the association of bubbles and characters. Then we infer character identification and generate comic book script with context-aware panel description including character's appearance, posture, mood, dialogues etc. We believe that such enriched content description can be easily used to produce audiobook and eBook with various voices for characters, captions and playing sound effects.
Identity Documents Authentication based on Forgery Detection of Guilloche Pattern
Jun 22, 2022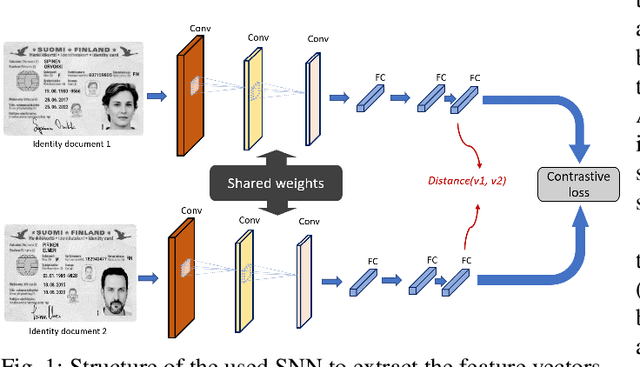

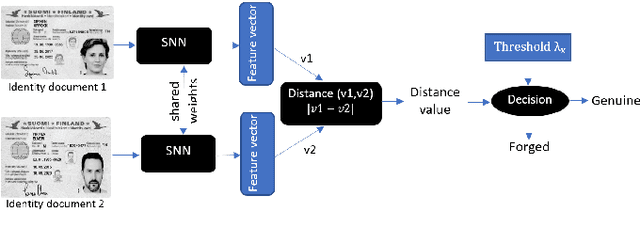

In cases such as digital enrolment via mobile and online services, identity document verification is critical in order to efficiently detect forgery and therefore build user trust in the digital world. In this paper, an authentication model for identity documents based on forgery detection of guilloche patterns is proposed. The proposed approach is made up of two steps: feature extraction and similarity measure between a pair of feature vectors of identity documents. The feature extraction step involves learning the similarity between a pair of identity documents via a convolutional neural network (CNN) architecture and ends by extracting highly discriminative features between them. While, the similarity measure step is applied to decide if a given identity document is authentic or forged. In this work, these two steps are combined together to achieve two objectives: (i) extracted features should have good anticollision (discriminative) capabilities to distinguish between a pair of identity documents belonging to different classes, (ii) checking out the conformity of the guilloche pattern of a given identity document and its similarity to the guilloche pattern of an authentic version of the same country. Experiments are conducted in order to analyze and identify the most proper parameters to achieve higher authentication performance. The experimental results are performed on the MIDV-2020 dataset. The results show the ability of the proposed approach to extract the relevant characteristics of the processed pair of identity documents in order to model the guilloche patterns, and thus distinguish them correctly. The implementation code and the forged dataset are provided here (https://drive.google.com/id-FDGP-1)
ViTransPAD: Video Transformer using convolution and self-attention for Face Presentation Attack Detection
Mar 14, 2022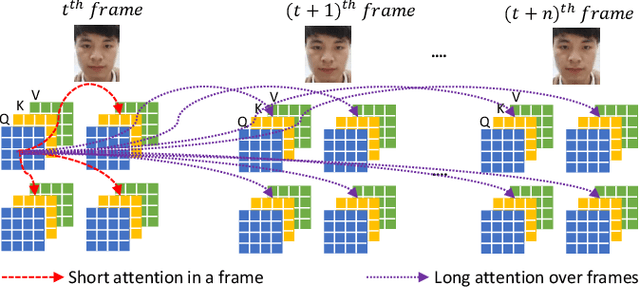
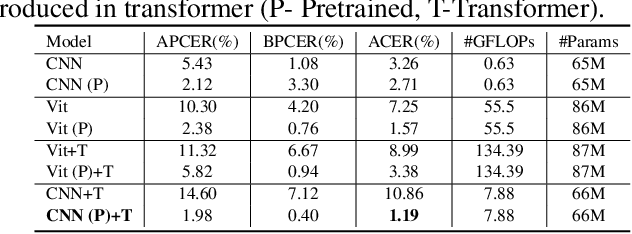
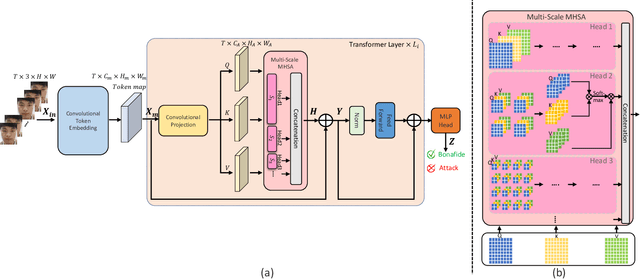
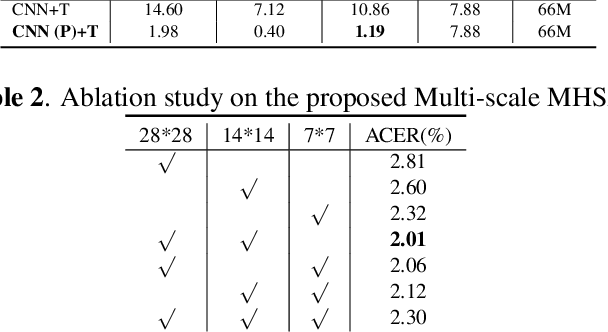
Face Presentation Attack Detection (PAD) is an important measure to prevent spoof attacks for face biometric systems. Many works based on Convolution Neural Networks (CNNs) for face PAD formulate the problem as an image-level binary classification task without considering the context. Alternatively, Vision Transformers (ViT) using self-attention to attend the context of an image become the mainstreams in face PAD. Inspired by ViT, we propose a Video-based Transformer for face PAD (ViTransPAD) with short/long-range spatio-temporal attention which can not only focus on local details with short attention within a frame but also capture long-range dependencies over frames. Instead of using coarse image patches with single-scale as in ViT, we propose the Multi-scale Multi-Head Self-Attention (MsMHSA) architecture to accommodate multi-scale patch partitions of Q, K, V feature maps to the heads of transformer in a coarse-to-fine manner, which enables to learn a fine-grained representation to perform pixel-level discrimination for face PAD. Due to lack inductive biases of convolutions in pure transformers, we also introduce convolutions to the proposed ViTransPAD to integrate the desirable properties of CNNs by using convolution patch embedding and convolution projection. The extensive experiments show the effectiveness of our proposed ViTransPAD with a preferable accuracy-computation balance, which can serve as a new backbone for face PAD.
MIDV-2020: A Comprehensive Benchmark Dataset for Identity Document Analysis
Jul 01, 2021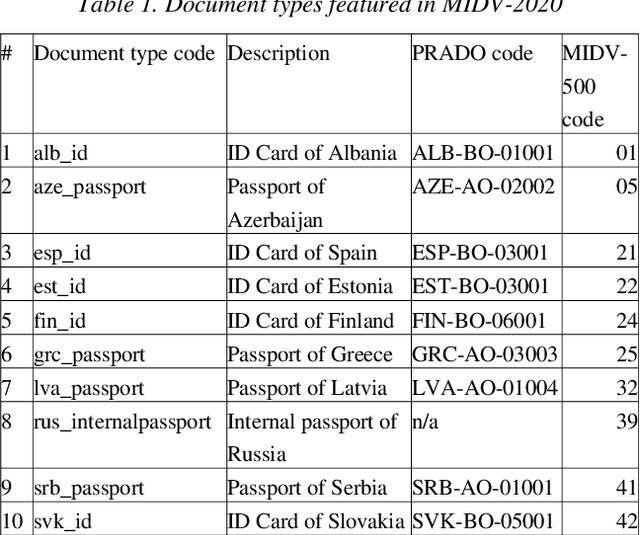

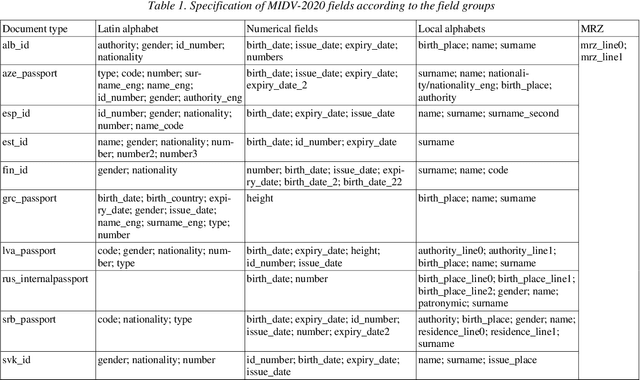

Identity documents recognition is an important sub-field of document analysis, which deals with tasks of robust document detection, type identification, text fields recognition, as well as identity fraud prevention and document authenticity validation given photos, scans, or video frames of an identity document capture. Significant amount of research has been published on this topic in recent years, however a chief difficulty for such research is scarcity of datasets, due to the subject matter being protected by security requirements. A few datasets of identity documents which are available lack diversity of document types, capturing conditions, or variability of document field values. In addition, the published datasets were typically designed only for a subset of document recognition problems, not for a complex identity document analysis. In this paper, we present a dataset MIDV-2020 which consists of 1000 video clips, 2000 scanned images, and 1000 photos of 1000 unique mock identity documents, each with unique text field values and unique artificially generated faces, with rich annotation. For the presented benchmark dataset baselines are provided for such tasks as document location and identification, text fields recognition, and face detection. With 72409 annotated images in total, to the date of publication the proposed dataset is the largest publicly available identity documents dataset with variable artificially generated data, and we believe that it will prove invaluable for advancement of the field of document analysis and recognition. The dataset is available for download at ftp://smartengines.com/midv-2020 and http://l3i-share.univ-lr.fr .
A Survey On Anti-Spoofing Methods For Face Recognition with RGB Cameras of Generic Consumer Devices
Oct 08, 2020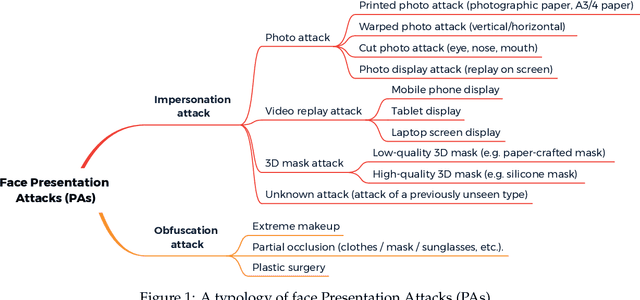
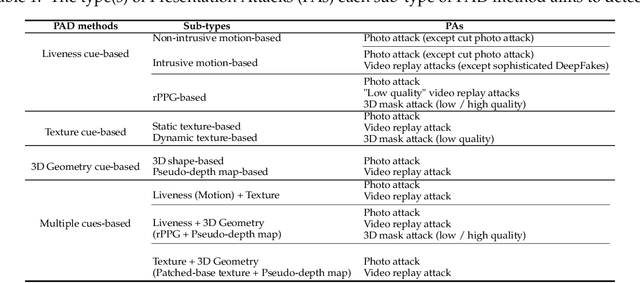

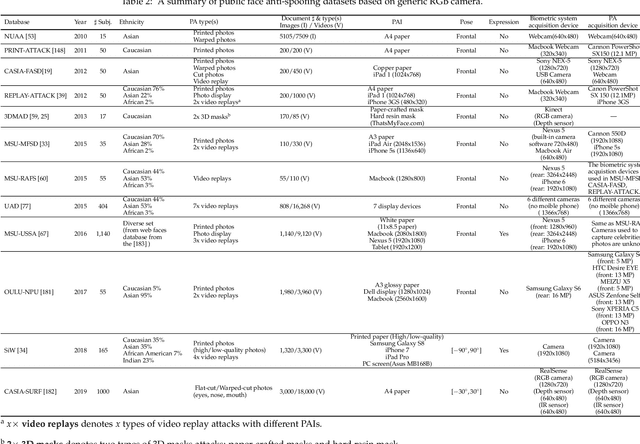
The widespread deployment of face recognition-based biometric systems has made face Presentation Attack Detection (face anti-spoofing) an increasingly critical issue. This survey thoroughly investigates the face Presentation Attack Detection (PAD) methods, that only require RGB cameras of generic consumer devices, over the past two decades. We present an attack scenario-oriented typology of the existing face PAD methods and we provide a review of over 50 of the most recent face PAD methods and their related issues. We adopt a comprehensive presentation of the methods that have most influenced face PAD following the proposed typology, and in chronological order. By doing so, we depict the main challenges, evolutions and current trends in the field of face PAD, and provide insights on its future research. From an experimental point of view, this survey paper provides a summarized overview of the available public databases and extensive comparative experimental results of different PAD methods.
Cross-modal Multi-task Learning for Graphic Recognition of Caricature Face
Mar 10, 2020
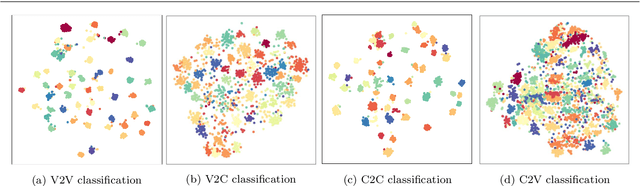
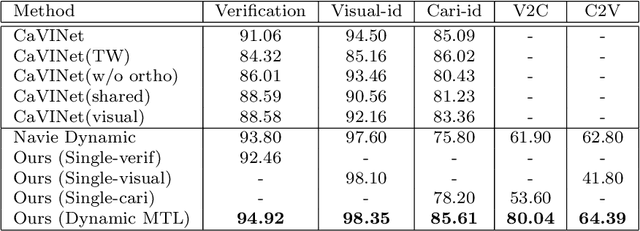
Face recognition of realistic visual images has been well studied and made a significant progress in the recent decade. Unlike the realistic visual images, the face recognition of the caricatures is far from the performance of the visual images. This is largely due to the extreme non-rigid distortions of the caricatures introduced by exaggerating the facial features to strengthen the characters. The heterogeneous modalities of the caricatures and the visual images result the caricature-visual face recognition is a cross-modal problem. In this paper, we propose a method to conduct caricature-visual face recognition via multi-task learning. Rather than the conventional multi-task learning with fixed weights of tasks, this work proposes an approach to learn the weights of tasks according to the importance of tasks. The proposed multi-task learning with dynamic tasks weights enables to appropriately train the hard task and easy task instead of being stuck in the over-training easy task as conventional methods. The experimental results demonstrate the effectiveness of the proposed dynamic multi-task learning for cross-modal caricature-visual face recognition. The performances on the datasets CaVI and WebCaricature show the superiority over the state-of-art methods.
Face Detection in Camera Captured Images of Identity Documents under Challenging Conditions
Nov 08, 2019
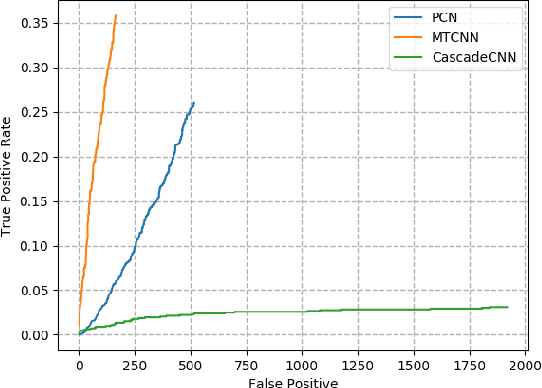


Benefiting from the advance of deep convolutional neural network approaches (CNNs), many face detection algorithms have achieved state-of-the-art performance in terms of accuracy and very high speed in unconstrained applications. However, due to the lack of public datasets and due to the variation of the orientation of face images, the complex background and lighting, defocus and the varying illumination of camera captured images, face detection on identity documents under unconstrained environments has not been sufficiently studied. To address this problem more efficiently, we survey three state-of-the-art face detection methods based on general images, i.e. Cascade-CNN, MTCNN and PCN, for face detection in camera captured images of identity documents, given different image quality assessments. For that, The MIDV-500 dataset, which is the largest and most challenging dataset for identity documents, is used to evaluate the three methods. The evaluation results show the performance and the limitations of the current methods for face detection on identity documents under the wild complex environments. These results show that the face detection task in camera captured images of identity documents is challenging, providing a space to improve in the future works.
Dynamic Deep Multi-task Learning for Caricature-Visual Face Recognition
Nov 08, 2019

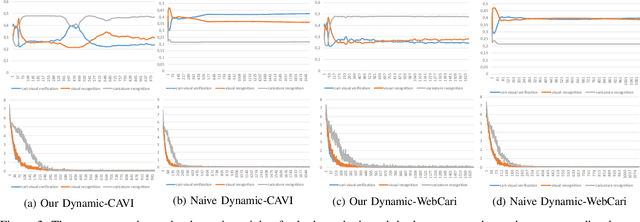
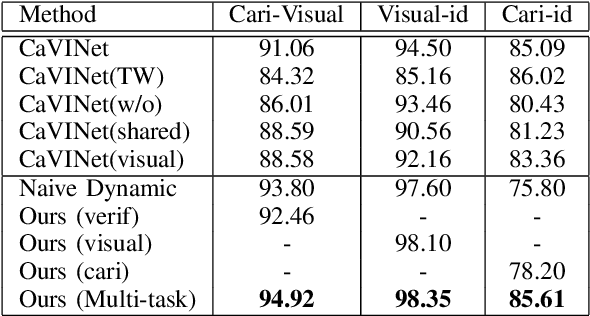
Rather than the visual images, the face recognition of the caricatures is far from the performance of the visual images. The challenge is the extreme non-rigid distortions of the caricatures introduced by exaggerating the facial features to strengthen the characters. In this paper, we propose dynamic multi-task learning based on deep CNNs for cross-modal caricature-visual face recognition. Instead of the conventional multi-task learning with fixed weights of the tasks, the proposed dynamic multi-task learning dynamically updates the weights of tasks according to the importance of the tasks, which enables the training of the networks focus on the hard task instead of being stuck in the overtraining of the easy task. The experimental results demonstrate the effectiveness of the dynamic multi-task learning for caricature-visual face recognition. The performance evaluated on the datasets CaVI and WebCaricature show the superiority over the state-of-art methods. The implementation code is available here.
Dynamic Multi-Task Learning for Face Recognition with Facial Expression
Nov 08, 2019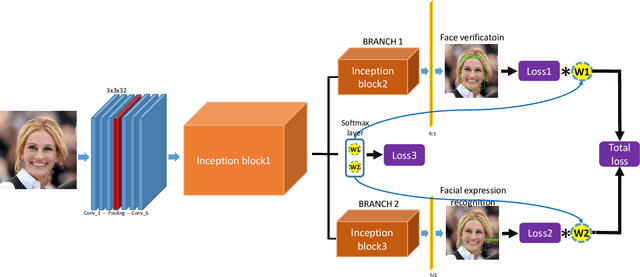

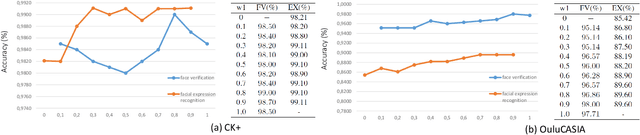
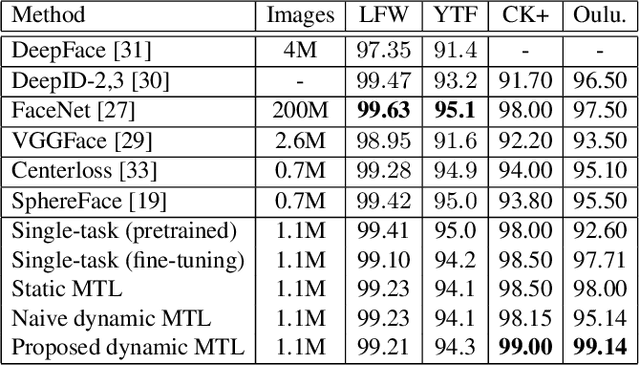
Benefiting from the joint learning of the multiple tasks in the deep multi-task networks, many applications have shown the promising performance comparing to single-task learning. However, the performance of multi-task learning framework is highly dependant on the relative weights of the tasks. How to assign the weight of each task is a critical issue in the multi-task learning. Instead of tuning the weights manually which is exhausted and time-consuming, in this paper we propose an approach which can dynamically adapt the weights of the tasks according to the difficulty for training the task. Specifically, the proposed method does not introduce the hyperparameters and the simple structure allows the other multi-task deep learning networks can easily realize or reproduce this method. We demonstrate our approach for face recognition with facial expression and facial expression recognition from a single input image based on a deep multi-task learning Conventional Neural Networks (CNNs). Both the theoretical analysis and the experimental results demonstrate the effectiveness of the proposed dynamic multi-task learning method. This multi-task learning with dynamic weights also boosts of the performance on the different tasks comparing to the state-of-art methods with single-task learning.
ICDAR2019 Robust Reading Challenge on Multi-lingual Scene Text Detection and Recognition -- RRC-MLT-2019
Jul 01, 2019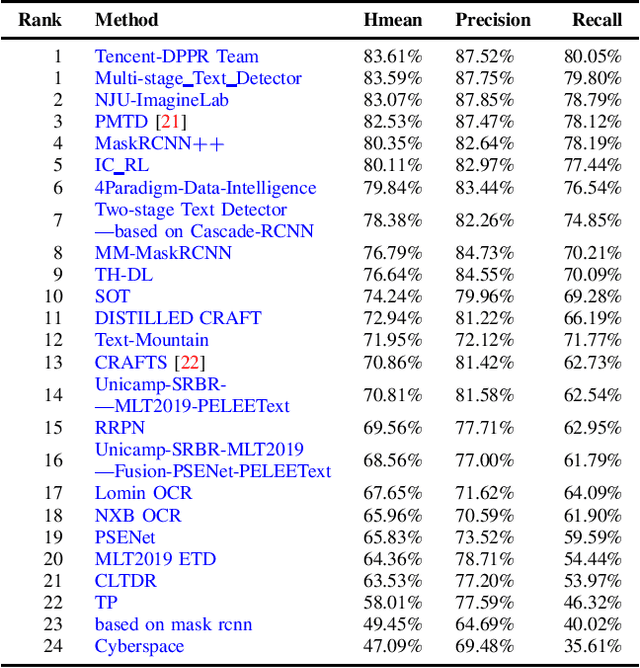
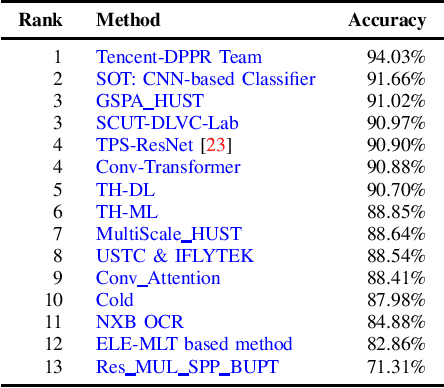
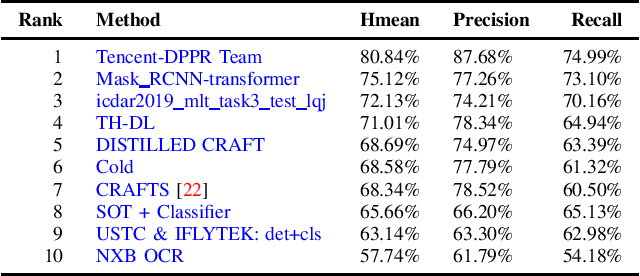
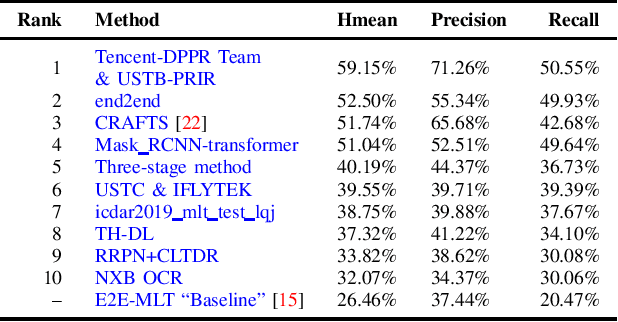
With the growing cosmopolitan culture of modern cities, the need of robust Multi-Lingual scene Text (MLT) detection and recognition systems has never been more immense. With the goal to systematically benchmark and push the state-of-the-art forward, the proposed competition builds on top of the RRC-MLT-2017 with an additional end-to-end task, an additional language in the real images dataset, a large scale multi-lingual synthetic dataset to assist the training, and a baseline End-to-End recognition method. The real dataset consists of 20,000 images containing text from 10 languages. The challenge has 4 tasks covering various aspects of multi-lingual scene text: (a) text detection, (b) cropped word script classification, (c) joint text detection and script classification and (d) end-to-end detection and recognition. In total, the competition received 60 submissions from the research and industrial communities. This paper presents the dataset, the tasks and the findings of the presented RRC-MLT-2019 challenge.