 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Deep Multi-task Learning for Caricature-Visual Face Recognition
Paper and Code


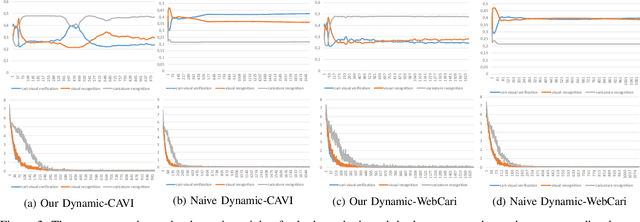
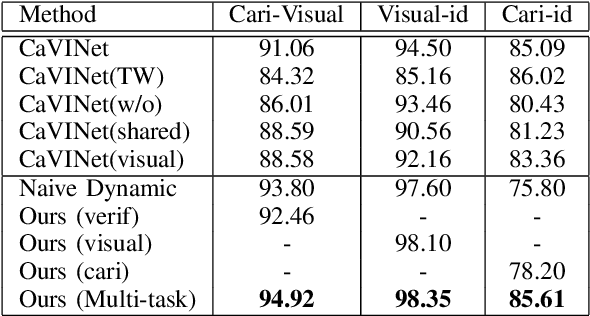
Rather than the visual images, the face recognition of the caricatures is far from the performance of the visual images. The challenge is the extreme non-rigid distortions of the caricatures introduced by exaggerating the facial features to strengthen the characters. In this paper, we propose dynamic multi-task learning based on deep CNNs for cross-modal caricature-visual face recognition. Instead of the conventional multi-task learning with fixed weights of the tasks, the proposed dynamic multi-task learning dynamically updates the weights of tasks according to the importance of the tasks, which enables the training of the networks focus on the hard task instead of being stuck in the overtraining of the easy task. The experimental results demonstrate the effectiveness of the dynamic multi-task learning for caricature-visual face recognition. The performance evaluated on the datasets CaVI and WebCaricature show the superiority over the state-of-art methods. The implementation code is available here.