 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICDAR2019 Robust Reading Challenge on Multi-lingual Scene Text Detection and Recognition -- RRC-MLT-2019
Paper and Code
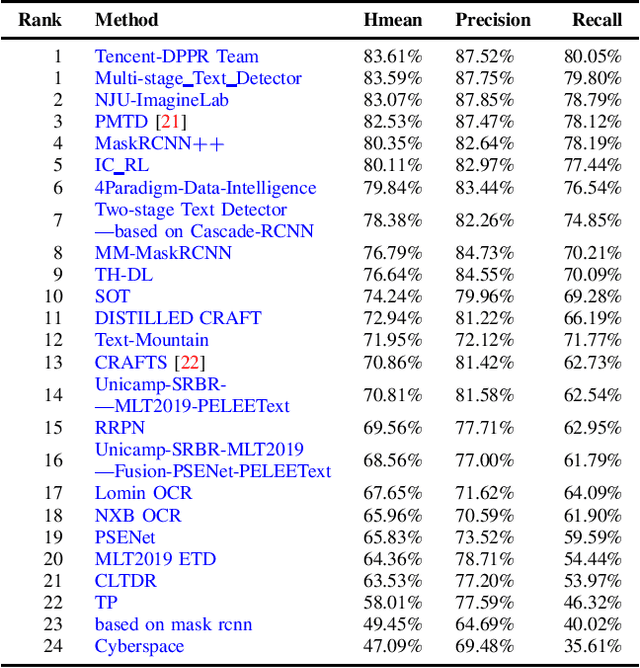
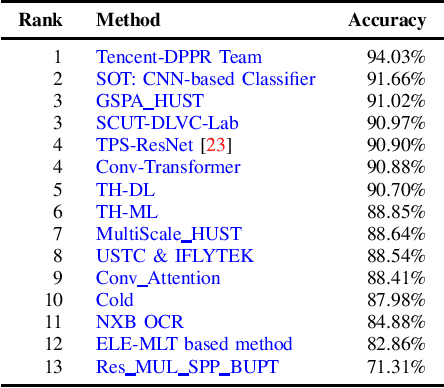
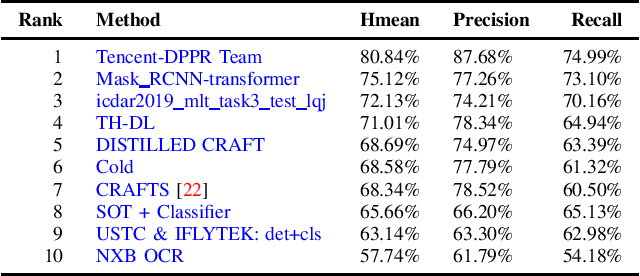
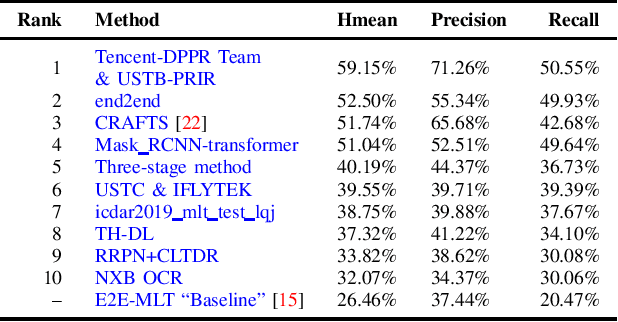
With the growing cosmopolitan culture of modern cities, the need of robust Multi-Lingual scene Text (MLT) detection and recognition systems has never been more immense. With the goal to systematically benchmark and push the state-of-the-art forward, the proposed competition builds on top of the RRC-MLT-2017 with an additional end-to-end task, an additional language in the real images dataset, a large scale multi-lingual synthetic dataset to assist the training, and a baseline End-to-End recognition method. The real dataset consists of 20,000 images containing text from 10 languages. The challenge has 4 tasks covering various aspects of multi-lingual scene text: (a) text detection, (b) cropped word script classification, (c) joint text detection and script classification and (d) end-to-end detection and recognition. In total, the competition received 60 submissions from the research and industrial communities. This paper presents the dataset, the tasks and the findings of the presented RRC-MLT-2019 challenge.