 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Topology Information Enhanced Heterogeneous Graph Representation Learning
Apr 07, 2026Real-world heterogeneous graphs are inherently noisy and usually not in the optimal graph structures for downstream tasks, which often adversely affects the performance of GRL models in downstream tasks. Although Graph Structure Learning (GSL) methods have been proposed to learn graph structures and downstream tasks simultaneously, existing methods are predominantly designed for homogeneous graphs, while GSL for heterogeneous graphs remains largely unexplored. Two challenges arise in this context. Firstly, the quality of the input graph structure has a more profound impact on GNN-based heterogeneous GRL models compared to their homogeneous counterparts. Secondly, most existing homogenous GRL models encounter memory consumption issues when applied directly to heterogeneous graphs. In this paper, we propose a novel Graph Topology learning Enhanced Heterogeneous Graph Representation Learning framework (ToGRL).ToGRL learns high-quality graph structures and representations for downstream tasks by incorporating task-relevant latent topology information. Specifically, a novel GSL module is first proposed to extract downstream task-related topology information from a raw graph structure and project it into topology embeddings. These embeddings are utilized to construct a new graph with smooth graph signals. This two-stage approach to GSL separates the optimization of the adjacency matrix from node representation learning to reduce memory consumption. Following this, a representation learning module takes the new graph as input to learn embeddings for downstream tasks. ToGRL also leverages prompt tuning to better utilize the knowledge embedded in learned representations, thus enhancing adaptability to downstream tasks. Extensive experiments on five real-world datasets show that our ToGRL outperforms state-of-the-art methods by a large margin.
PretrainRL: Alleviating Factuality Hallucination of Large Language Models at the Beginning
Feb 02, 2026Large language models (LLMs), despite their powerful capabilities, suffer from factual hallucinations where they generate verifiable falsehoods. We identify a root of this issue: the imbalanced data distribution in the pretraining corpus, which leads to a state of "low-probability truth" and "high-probability falsehood". Recent approaches, such as teaching models to say "I don't know" or post-hoc knowledge editing, either evade the problem or face catastrophic forgetting. To address this issue from its root, we propose \textbf{PretrainRL}, a novel framework that integrates reinforcement learning into the pretraining phase to consolidate factual knowledge. The core principle of PretrainRL is "\textbf{debiasing then learning}." It actively reshapes the model's probability distribution by down-weighting high-probability falsehoods, thereby making "room" for low-probability truths to be learned effectively. To enable this, we design an efficient negative sampling strategy to discover these high-probability falsehoods and introduce novel metrics to evaluate the model's probabilistic state concerning factual knowledge. Extensive experiments on three public benchmarks demonstrate that PretrainRL significantly alleviates factual hallucinations and outperforms state-of-the-art methods.
Data Distribution Matters: A Data-Centric Perspective on Context Compression for Large Language Model
Feb 02, 2026The deployment of Large Language Models (LLMs) in long-context scenarios is hindered by computational inefficiency and significant information redundancy. Although recent advancements have widely adopted context compression to address these challenges, existing research only focus on model-side improvements, the impact of the data distribution itself on context compression remains largely unexplored. To bridge this gap, we are the first to adopt a data-centric perspective to systematically investigate how data distribution impacts compression quality, including two dimensions: input data and intrinsic data (i.e., the model's internal pretrained knowledge). We evaluate the semantic integrity of compressed representations using an autoencoder-based framework to systematically investigate it. Our experimental results reveal that: (1) encoder-measured input entropy negatively correlates with compression quality, while decoder-measured entropy shows no significant relationship under a frozen-decoder setting; and (2) the gap between intrinsic data of the encoder and decoder significantly diminishes compression gains, which is hard to mitigate. Based on these findings, we further present practical guidelines to optimize compression gains.
Enhancing Diffusion-Based Quantitatively Controllable Image Generation via Matrix-Form EDM and Adaptive Vicinal Training
Feb 02, 2026Continuous Conditional Diffusion Model (CCDM) is a diffusion-based framework designed to generate high-quality images conditioned on continuous regression labels. Although CCDM has demonstrated clear advantages over prior approaches across a range of datasets, it still exhibits notable limitations and has recently been surpassed by a GAN-based method, namely CcGAN-AVAR. These limitations mainly arise from its reliance on an outdated diffusion framework and its low sampling efficiency due to long sampling trajectories. To address these issues, we propose an improved CCDM framework, termed iCCDM, which incorporates the more advanced \textit{Elucidated Diffusion Model} (EDM) framework with substantial modifications to improve both generation quality and sampling efficiency. Specifically, iCCDM introduces a novel matrix-form EDM formulation together with an adaptive vicinal training strategy. Extensive experiments on four benchmark datasets, spanning image resolutions from $64\times64$ to $256\times256$, demonstrate that iCCDM consistently outperforms existing methods, including state-of-the-art large-scale text-to-image diffusion models (e.g., Stable Diffusion 3, FLUX.1, and Qwen-Image), achieving higher generation quality while significantly reducing sampling cost.
NAN: A Training-Free Solution to Coefficient Estimation in Model Merging
May 22, 2025Model merging offers a training-free alternative to multi-task learning by combining independently fine-tuned models into a unified one without access to raw data. However, existing approaches often rely on heuristics to determine the merging coefficients, limiting their scalability and generality. In this work, we revisit model merging through the lens of least-squares optimization and show that the optimal merging weights should scale with the amount of task-specific information encoded in each model. Based on this insight, we propose NAN, a simple yet effective method that estimates model merging coefficients via the inverse of parameter norm. NAN is training-free, plug-and-play, and applicable to a wide range of merging strategies. Extensive experiments on show that NAN consistently improves performance of baseline methods.
Motion-Coupled Mapping Algorithm for Hybrid Rice Canopy
Feb 22, 2025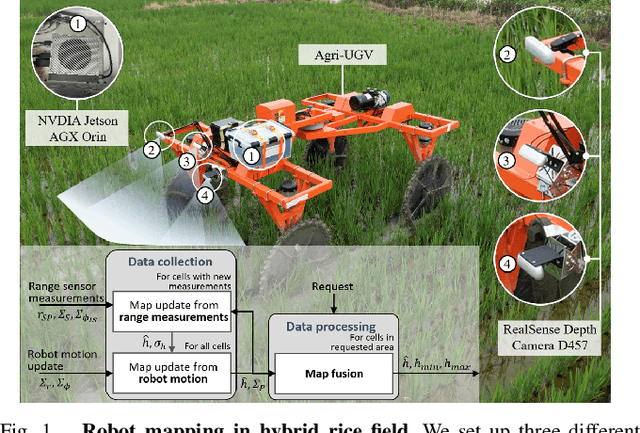
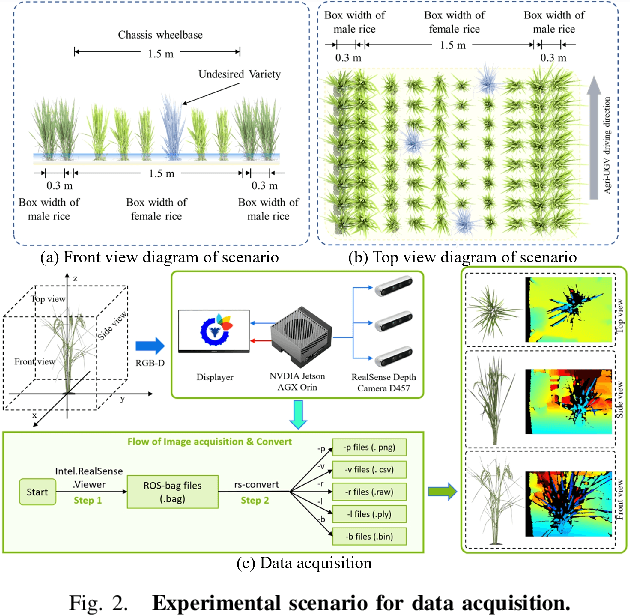
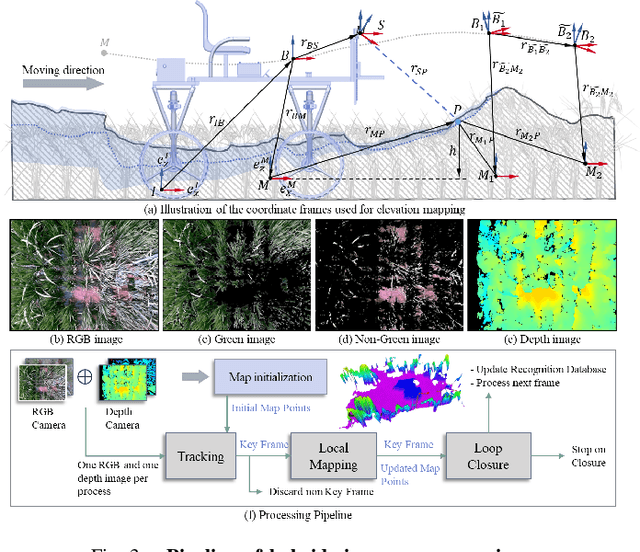
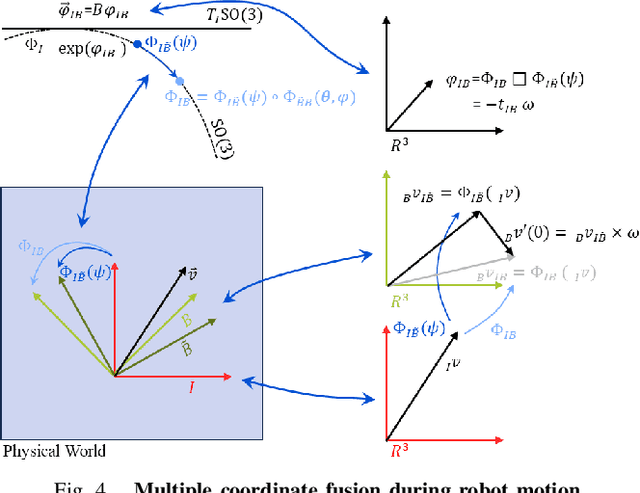
This paper presents a motion-coupled mapping algorithm for contour mapping of hybrid rice canopies, specifically designed for Agricultural Unmanned Ground Vehicles (Agri-UGV) navigating complex and unknown rice fields. Precise canopy mapping is essential for Agri-UGVs to plan efficient routes and avoid protected zones. The motion control of Agri-UGVs, tasked with impurity removal and other operations, depends heavily on accurate estimation of rice canopy height and structure. To achieve this, the proposed algorithm integrates real-time RGB-D sensor data with kinematic and inertial measurements, enabling efficient mapping and proprioceptive localization. The algorithm produces grid-based elevation maps that reflect the probabilistic distribution of canopy contours, accounting for motion-induced uncertainties. It is implemented on a high-clearance Agri-UGV platform and tested in various environments, including both controlled and dynamic rice field settings. This approach significantly enhances the mapping accuracy and operational reliability of Agri-UGVs, contributing to more efficient autonomous agricultural operations.
* Best Paper Award First Place - IROS 2024 Workshop on AI and Robotics For Future Farming
DeMuVGN: Effective Software Defect Prediction Model by Learning Multi-view Software Dependency via Graph Neural Networks
Oct 25, 2024Software defect prediction (SDP) aims to identify high-risk defect modules in software development, optimizing resource allocation. While previous studies show that dependency network metrics improve defect prediction, most methods focus on code-based dependency graphs, overlooking developer factors. Current metrics, based on handcrafted features like ego and global network metrics, fail to fully capture defect-related information. To address this, we propose DeMuVGN, a defect prediction model that learns multi-view software dependency via graph neural networks. We introduce a Multi-view Software Dependency Graph (MSDG) that integrates data, call, and developer dependencies. DeMuVGN also leverages the Synthetic Minority Oversampling Technique (SMOTE) to address class imbalance and enhance defect module identification. In a case study of eight open-source projects across 20 versions, DeMuVGN demonstrates significant improvements: i) models based on multi-view graphs improve F1 scores by 11.1% to 12.1% over single-view models; ii) DeMuVGN improves F1 scores by 17.4% to 45.8% in within-project contexts and by 17.9% to 41.0% in cross-project contexts. Additionally, DeMuVGN excels in software evolution, showing more improvement in later-stage software versions. Its strong performance across different projects highlights its generalizability. We recommend future research focus on multi-view dependency graphs for defect prediction in both mature and newly developed projects.
Training-free LLM-generated Text Detection by Mining Token Probability Sequences
Oct 08, 2024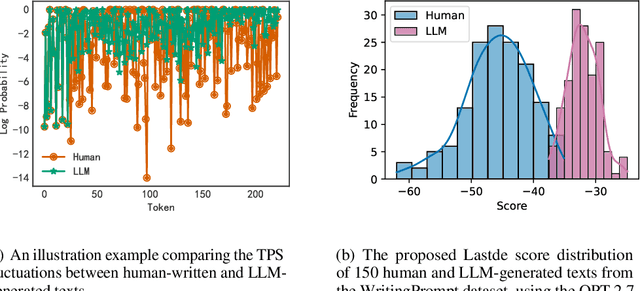
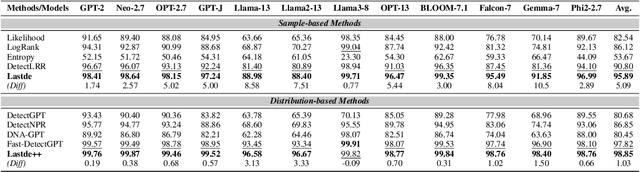
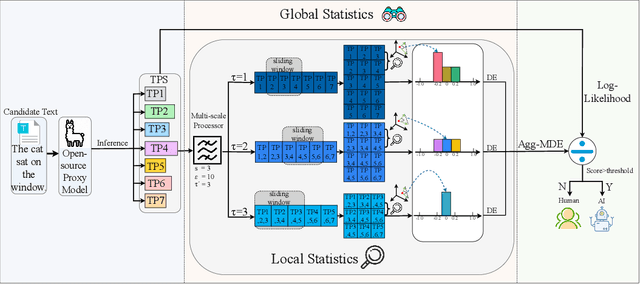
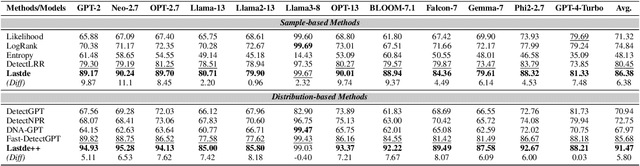
Large language models (LLMs) have demonstrated remarkable capabilities in generating high-quality texts across diverse domains. However, the potential misuse of LLMs has raised significant concerns, underscoring the urgent need for reliable detection of LLM-generated texts. Conventional training-based detectors often struggle with generalization, particularly in cross-domain and cross-model scenarios. In contrast, training-free methods, which focus on inherent discrepancies through carefully designed statistical features, offer improved generalization and interpretability. Despite this, existing training-free detection methods typically rely on global text sequence statistics, neglecting the modeling of local discriminative features, thereby limiting their detection efficacy. In this work, we introduce a novel training-free detector, termed \textbf{Lastde} that synergizes local and global statistics for enhanced detection. For the first time, we introduce time series analysis to LLM-generated text detection, capturing the temporal dynamics of token probability sequences. By integrating these local statistics with global ones, our detector reveals significant disparities between human and LLM-generated texts. We also propose an efficient alternative, \textbf{Lastde++} to enable real-time detection. Extensive experiments on six datasets involving cross-domain, cross-model, and cross-lingual detection scenarios, under both white-box and black-box settings, demonstrated that our method consistently achieves state-of-the-art performance. Furthermore, our approach exhibits greater robustness against paraphrasing attacks compared to existing baseline methods.
Hyper Adversarial Tuning for Boosting Adversarial Robustness of Pretrained Large Vision Models
Oct 08, 2024



Large vision models have been found vulnerable to adversarial examples, emphasizing the need for enhancing their adversarial robustness. While adversarial training is an effective defense for deep convolutional models, it often faces scalability issues with large vision models due to high computational costs. Recent approaches propose robust fine-tuning methods, such as adversarial tuning of low-rank adaptation (LoRA) in large vision models, but they still struggle to match the accuracy of full parameter adversarial fine-tuning. The integration of various defense mechanisms offers a promising approach to enhancing the robustness of large vision models, yet this paradigm remains underexplored. To address this, we propose hyper adversarial tuning (HyperAT), which leverages shared defensive knowledge among different methods to improve model robustness efficiently and effectively simultaneously. Specifically, adversarial tuning of each defense method is formulated as a learning task, and a hypernetwork generates LoRA specific to this defense. Then, a random sampling and tuning strategy is proposed to extract and facilitate the defensive knowledge transfer between different defenses. Finally, diverse LoRAs are merged to enhance the adversarial robustness. Experiments on various datasets and model architectures demonstrate that HyperAT significantly enhances the adversarial robustness of pretrained large vision models without excessive computational overhead, establishing a new state-of-the-art benchmark.
HyperDet: Generalizable Detection of Synthesized Images by Generating and Merging A Mixture of Hyper LoRAs
Oct 08, 2024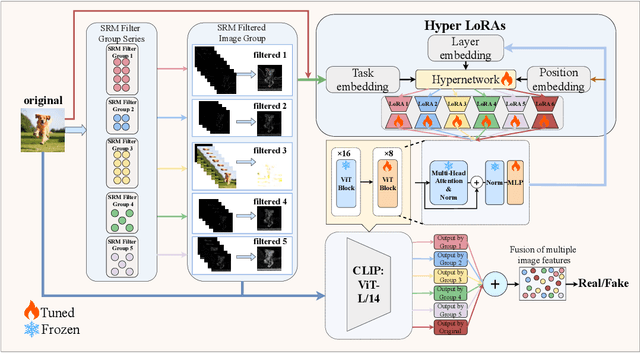



The emergence of diverse generative vision models has recently enabled the synthesis of visually realistic images, underscoring the critical need for effectively detecting these generated images from real photos. Despite advances in this field, existing detection approaches often struggle to accurately identify synthesized images generated by different generative models. In this work, we introduce a novel and generalizable detection framework termed HyperDet, which innovatively captures and integrates shared knowledge from a collection of functionally distinct and lightweight expert detectors. HyperDet leverages a large pretrained vision model to extract general detection features while simultaneously capturing and enhancing task-specific features. To achieve this, HyperDet first groups SRM filters into five distinct groups to efficiently capture varying levels of pixel artifacts based on their different functionality and complexity. Then, HyperDet utilizes a hypernetwork to generate LoRA model weights with distinct embedding parameters. Finally, we merge the LoRA networks to form an efficient model ensemble. Also, we propose a novel objective function that balances the pixel and semantic artifacts effectively. Extensive experiments on the UnivFD and Fake2M datasets demonstrate the effectiveness of our approach, achieving state-of-the-art performance. Moreover, our work paves a new way to establish generalizable domain-specific fake image detectors based on pretrained large vision models.