 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper Adversarial Tuning for Boosting Adversarial Robustness of Pretrained Large Vision Models
Oct 08, 2024



Large vision models have been found vulnerable to adversarial examples, emphasizing the need for enhancing their adversarial robustness. While adversarial training is an effective defense for deep convolutional models, it often faces scalability issues with large vision models due to high computational costs. Recent approaches propose robust fine-tuning methods, such as adversarial tuning of low-rank adaptation (LoRA) in large vision models, but they still struggle to match the accuracy of full parameter adversarial fine-tuning. The integration of various defense mechanisms offers a promising approach to enhancing the robustness of large vision models, yet this paradigm remains underexplored. To address this, we propose hyper adversarial tuning (HyperAT), which leverages shared defensive knowledge among different methods to improve model robustness efficiently and effectively simultaneously. Specifically, adversarial tuning of each defense method is formulated as a learning task, and a hypernetwork generates LoRA specific to this defense. Then, a random sampling and tuning strategy is proposed to extract and facilitate the defensive knowledge transfer between different defenses. Finally, diverse LoRAs are merged to enhance the adversarial robustness. Experiments on various datasets and model architectures demonstrate that HyperAT significantly enhances the adversarial robustness of pretrained large vision models without excessive computational overhead, establishing a new state-of-the-art benchmark.
HyperDet: Generalizable Detection of Synthesized Images by Generating and Merging A Mixture of Hyper LoRAs
Oct 08, 2024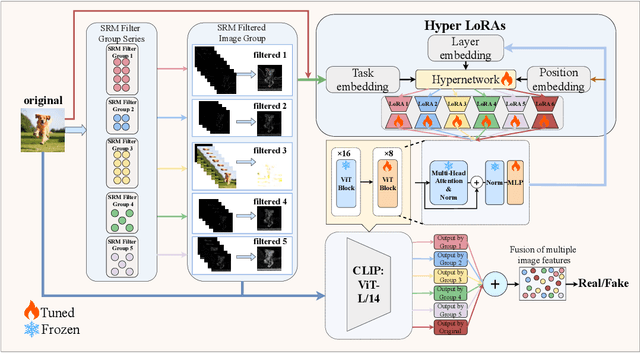



The emergence of diverse generative vision models has recently enabled the synthesis of visually realistic images, underscoring the critical need for effectively detecting these generated images from real photos. Despite advances in this field, existing detection approaches often struggle to accurately identify synthesized images generated by different generative models. In this work, we introduce a novel and generalizable detection framework termed HyperDet, which innovatively captures and integrates shared knowledge from a collection of functionally distinct and lightweight expert detectors. HyperDet leverages a large pretrained vision model to extract general detection features while simultaneously capturing and enhancing task-specific features. To achieve this, HyperDet first groups SRM filters into five distinct groups to efficiently capture varying levels of pixel artifacts based on their different functionality and complexity. Then, HyperDet utilizes a hypernetwork to generate LoRA model weights with distinct embedding parameters. Finally, we merge the LoRA networks to form an efficient model ensemble. Also, we propose a novel objective function that balances the pixel and semantic artifacts effectively. Extensive experiments on the UnivFD and Fake2M datasets demonstrate the effectiveness of our approach, achieving state-of-the-art performance. Moreover, our work paves a new way to establish generalizable domain-specific fake image detectors based on pretrained large vision models.
Training-free LLM-generated Text Detection by Mining Token Probability Sequences
Oct 08, 2024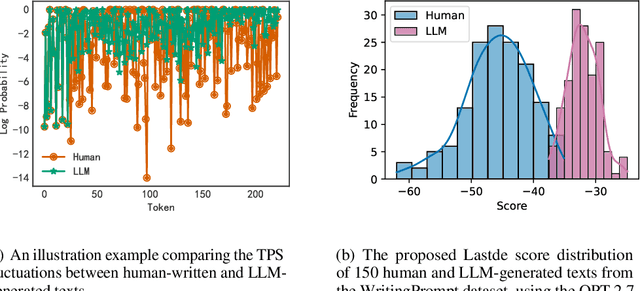
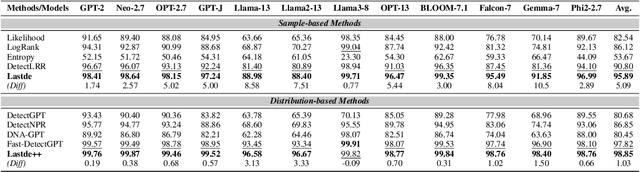
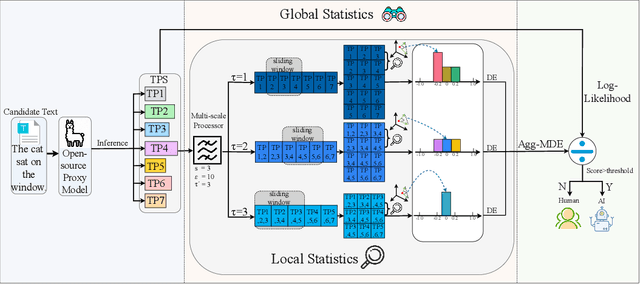
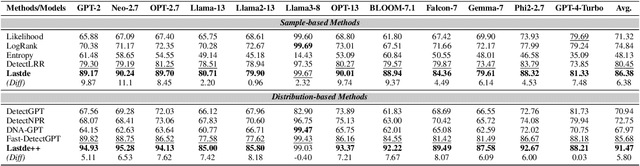
Large language models (LLMs) have demonstrated remarkable capabilities in generating high-quality texts across diverse domains. However, the potential misuse of LLMs has raised significant concerns, underscoring the urgent need for reliable detection of LLM-generated texts. Conventional training-based detectors often struggle with generalization, particularly in cross-domain and cross-model scenarios. In contrast, training-free methods, which focus on inherent discrepancies through carefully designed statistical features, offer improved generalization and interpretability. Despite this, existing training-free detection methods typically rely on global text sequence statistics, neglecting the modeling of local discriminative features, thereby limiting their detection efficacy. In this work, we introduce a novel training-free detector, termed \textbf{Lastde} that synergizes local and global statistics for enhanced detection. For the first time, we introduce time series analysis to LLM-generated text detection, capturing the temporal dynamics of token probability sequences. By integrating these local statistics with global ones, our detector reveals significant disparities between human and LLM-generated texts. We also propose an efficient alternative, \textbf{Lastde++} to enable real-time detection. Extensive experiments on six datasets involving cross-domain, cross-model, and cross-lingual detection scenarios, under both white-box and black-box settings, demonstrated that our method consistently achieves state-of-the-art performance. Furthermore, our approach exhibits greater robustness against paraphrasing attacks compared to existing baseline methods.