 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEX-4D: EXtreme Viewpoint 4D Video Synthesis via Depth Watertight Mesh
Jun 05, 2025
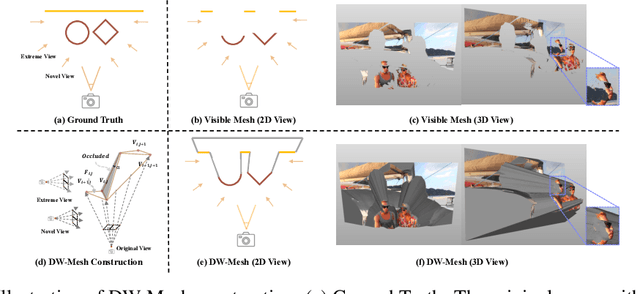


Generating high-quality camera-controllable videos from monocular input is a challenging task, particularly under extreme viewpoint. Existing methods often struggle with geometric inconsistencies and occlusion artifacts in boundaries, leading to degraded visual quality. In this paper, we introduce EX-4D, a novel framework that addresses these challenges through a Depth Watertight Mesh representation. The representation serves as a robust geometric prior by explicitly modeling both visible and occluded regions, ensuring geometric consistency in extreme camera pose. To overcome the lack of paired multi-view datasets, we propose a simulated masking strategy that generates effective training data only from monocular videos. Additionally, a lightweight LoRA-based video diffusion adapter is employed to synthesize high-quality, physically consistent, and temporally coherent videos. Extensive experiments demonstrate that EX-4D outperforms state-of-the-art methods in terms of physical consistency and extreme-view quality, enabling practical 4D video generation.
R-Bench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning Evaluation
May 04, 2025Reasoning stands as a cornerstone of intelligence, enabling the synthesis of existing knowledge to solve complex problems. Despite remarkable progress, existing reasoning benchmarks often fail to rigorously evaluate the nuanced reasoning capabilities required for complex, real-world problemsolving, particularly in multi-disciplinary and multimodal contexts. In this paper, we introduce a graduate-level, multi-disciplinary, EnglishChinese benchmark, dubbed as Reasoning Bench (R-Bench), for assessing the reasoning capability of both language and multimodal models. RBench spans 1,094 questions across 108 subjects for language model evaluation and 665 questions across 83 subjects for multimodal model testing in both English and Chinese. These questions are meticulously curated to ensure rigorous difficulty calibration, subject balance, and crosslinguistic alignment, enabling the assessment to be an Olympiad-level multi-disciplinary benchmark. We evaluate widely used models, including OpenAI o1, GPT-4o, DeepSeek-R1, etc. Experimental results indicate that advanced models perform poorly on complex reasoning, especially multimodal reasoning. Even the top-performing model OpenAI o1 achieves only 53.2% accuracy on our multimodal evaluation. Data and code are made publicly available at here.
DocGenome: An Open Large-scale Scientific Document Benchmark for Training and Testing Multi-modal Large Language Models
Jun 17, 2024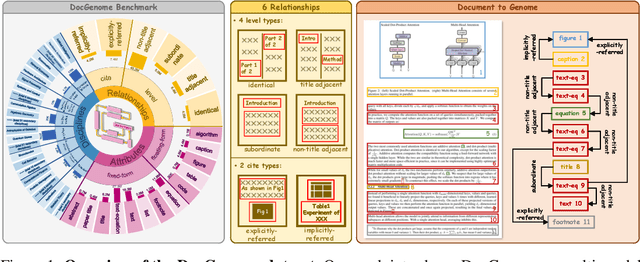
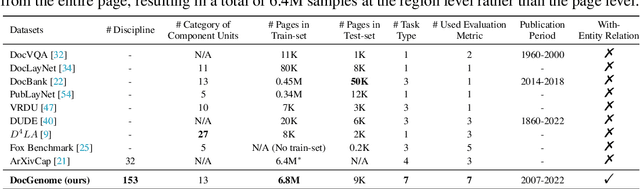
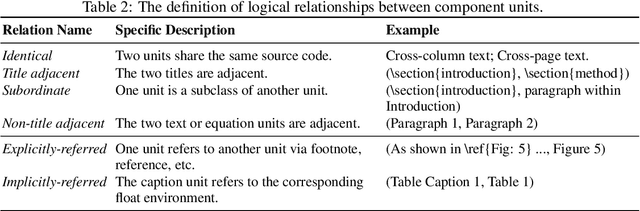
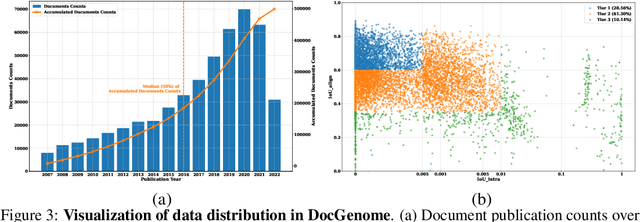
Scientific documents record research findings and valuable human knowledge, comprising a vast corpus of high-quality data. Leveraging multi-modality data extracted from these documents and assessing large models' abilities to handle scientific document-oriented tasks is therefore meaningful. Despite promising advancements, large models still perform poorly on multi-page scientific document extraction and understanding tasks, and their capacity to process within-document data formats such as charts and equations remains under-explored. To address these issues, we present DocGenome, a structured document benchmark constructed by annotating 500K scientific documents from 153 disciplines in the arXiv open-access community, using our custom auto-labeling pipeline. DocGenome features four key characteristics: 1) Completeness: It is the first dataset to structure data from all modalities including 13 layout attributes along with their LaTeX source codes. 2) Logicality: It provides 6 logical relationships between different entities within each scientific document. 3) Diversity: It covers various document-oriented tasks, including document classification, visual grounding, document layout detection, document transformation, open-ended single-page QA and multi-page QA. 4) Correctness: It undergoes rigorous quality control checks conducted by a specialized team. We conduct extensive experiments to demonstrate the advantages of DocGenome and objectively evaluate the performance of large models on our benchmark.
StructChart: Perception, Structuring, Reasoning for Visual Chart Understanding
Sep 25, 2023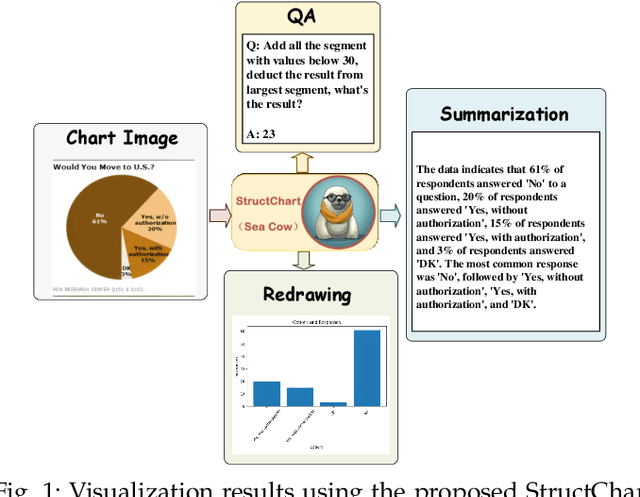
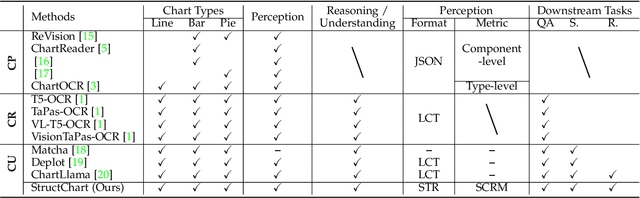
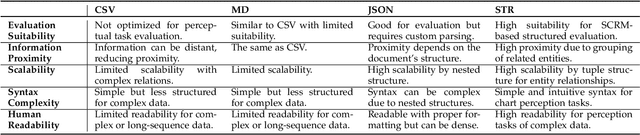
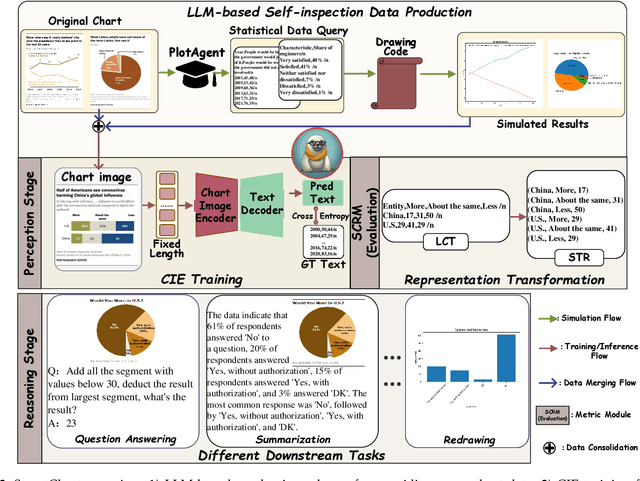
Charts are common in literature across different scientific fields, conveying rich information easily accessible to readers. Current chart-related tasks focus on either chart perception which refers to extracting information from the visual charts, or performing reasoning given the extracted data, e.g. in a tabular form. In this paper, we aim to establish a unified and label-efficient learning paradigm for joint perception and reasoning tasks, which can be generally applicable to different downstream tasks, beyond the question-answering task as specifically studied in peer works. Specifically, StructChart first reformulates the chart information from the popular tubular form (specifically linearized CSV) to the proposed Structured Triplet Representations (STR), which is more friendly for reducing the task gap between chart perception and reasoning due to the employed structured information extraction for charts. We then propose a Structuring Chart-oriented Representation Metric (SCRM) to quantitatively evaluate the performance for the chart perception task. To enrich the dataset for training, we further explore the possibility of leveraging the Large Language Model (LLM), enhancing the chart diversity in terms of both chart visual style and its statistical information. Extensive experiments are conducted on various chart-related tasks, demonstrating the effectiveness and promising potential for a unified chart perception-reasoning paradigm to push the frontier of chart understanding.
Multi-view Vision-Prompt Fusion Network: Can 2D Pre-trained Model Boost 3D Point Cloud Data-scarce Learning?
Apr 20, 2023



Point cloud based 3D deep model has wide applications in many applications such as autonomous driving, house robot, and so on. Inspired by the recent prompt learning in natural language processing, this work proposes a novel Multi-view Vision-Prompt Fusion Network (MvNet) for few-shot 3D point cloud classification. MvNet investigates the possibility of leveraging the off-the-shelf 2D pre-trained models to achieve the few-shot classification, which can alleviate the over-dependence issue of the existing baseline models towards the large-scale annotated 3D point cloud data. Specifically, MvNet first encodes a 3D point cloud into multi-view image features for a number of different views. Then, a novel multi-view prompt fusion module is developed to effectively fuse information from different views to bridge the gap between 3D point cloud data and 2D pre-trained models. A set of 2D image prompts can then be derived to better describe the suitable prior knowledge for a large-scale pre-trained image model for few-shot 3D point cloud classification. Extensive experiments on ModelNet, ScanObjectNN, and ShapeNet datasets demonstrate that MvNet achieves new state-of-the-art performance for 3D few-shot point cloud image classification. The source code of this work will be available soon.