 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoCap: Learning Topology-Agnostic Motion Priors for Monocular Video-to-Animation
Jun 10, 2026The explosion of generative 3D assets has created a massive demand for animation, yet current motion capture methods remain brittle, restricted to species-specific templates (e.g., SMPL) or requiring labor-intensive manual rigging. We introduce TopoCap, the first unified framework capable of extracting motion from monocular video and retargeting it onto characters with arbitrary, unseen skeletal topologies, i.e., from bipeds to hexapods and inanimate objects, without test-time optimization. Our key insight is that while skeletal structures are combinatorial and discrete, the underlying physics of motion occupy a continuous, low-dimensional manifold. We materialize this insight via a two-stage generative pipeline. First, we learn a Universal Motion Manifold using a Graph CVAE that compresses heterogeneous kinematic chains into a shared, fixed-length latent code. By explicitly conditioning the decoder on a structural embedding of the target rig, we disentangle motion dynamics from skeletal topology. Second, we treat video-to-animation as a conditional flow matching problem, predicting these topology-agnostic codes from visual features. To learn this generalized prior, we introduce Mobjaverse, a massive-scale dataset curated from Objaverse-XL. Comprising over 5,000 unique skeletal topologies and 2 million frames, it exceeds the structural diversity of existing datasets by two orders of magnitude. Extensive experiments demonstrate that \MethodMotion outperforms specialist models on human and quadruped benchmarks while enabling zero-shot retargeting for the long tail of 3D creatures. Dataset is publicly available at https://huggingface.co/datasets/duckduckplz/Mobjaverse.
Pixal3D: Pixel-Aligned 3D Generation from Images
May 11, 2026Recent advances in 3D generative models have rapidly improved image-to-3D synthesis quality, enabling higher-resolution geometry and more realistic appearance. Yet fidelity, which measures pixel-level faithfulness of the generated 3D asset to the input image, still remains a central bottleneck. We argue this stems from an implicit 2D-3D correspondence issue: most 3D-native generators synthesize shape in canonical space and inject image cues via attention, leaving pixel-to-3D associations ambiguous. To tackle this issue, we draw inspiration from 3D reconstruction and propose Pixal3D, a pixel-aligned 3D generation paradigm for high-fidelity 3D asset creation from images. Instead of generating in a canonical pose, Pixal3D directly generates 3D in a pixel-aligned way, consistent with the input view. To enable this, we introduce a pixel back-projection conditioning scheme that explicitly lifts multi-scale image features into a 3D feature volume, establishing direct pixel-to-3D correspondence without ambiguity. We show that Pixal3D is not only scalable and capable of producing high-quality 3D assets, but also substantially improves fidelity, approaching the fidelity level of reconstruction. Furthermore, Pixal3D naturally extends to multi-view generation by aggregating back-projected feature volumes across views. Finally, we show pixel-aligned generation benefits scene synthesis, and present a modular pipeline that produces high-fidelity, object-separated 3D scenes from images. Pixal3D for the first time demonstrates 3D-native pixel-aligned generation at scale, and provides a new inspiring way towards high-fidelity 3D generation of object or scene from single or multi-view images. Project page: https://ldyang694.github.io/projects/pixal3d/
Towards Universal Video MLLMs with Attribute-Structured and Quality-Verified Instructions
Feb 13, 2026Universal video understanding requires modeling fine-grained visual and audio information over time in diverse real-world scenarios. However, the performance of existing models is primarily constrained by video-instruction data that represents complex audiovisual content as single, incomplete descriptions, lacking fine-grained organization and reliable annotation. To address this, we introduce: (i) ASID-1M, an open-source collection of one million structured, fine-grained audiovisual instruction annotations with single- and multi-attribute supervision; (ii) ASID-Verify, a scalable data curation pipeline for annotation, with automatic verification and refinement that enforces semantic and temporal consistency between descriptions and the corresponding audiovisual content; and (iii) ASID-Captioner, a video understanding model trained via Supervised Fine-Tuning (SFT) on the ASID-1M. Experiments across seven benchmarks covering audiovisual captioning, attribute-wise captioning, caption-based QA, and caption-based temporal grounding show that ASID-Captioner improves fine-grained caption quality while reducing hallucinations and improving instruction following. It achieves state-of-the-art performance among open-source models and is competitive with Gemini-3-Pro.
Improving Variable-Length Generation in Diffusion Language Models via Length Regularization
Feb 07, 2026Diffusion Large Language Models (DLLMs) are inherently ill-suited for variable-length generation, as their inference is defined on a fixed-length canvas and implicitly assumes a known target length. When the length is unknown, as in realistic completion and infilling, naively comparing confidence across mask lengths becomes systematically biased, leading to under-generation or redundant continuations. In this paper, we show that this failure arises from an intrinsic lengthinduced bias in generation confidence estimates, leaving existing DLLMs without a robust way to determine generation length and making variablelength inference unreliable. To address this issue, we propose LR-DLLM, a length-regularized inference framework for DLLMs that treats generation length as an explicit variable and achieves reliable length determination at inference time. It decouples semantic compatibility from lengthinduced uncertainty through an explicit length regularization that corrects biased confidence estimates. Based on this, LR-DLLM enables dynamic expansion or contraction of the generation span without modifying the underlying DLLM or its training procedure. Experiments show that LRDLLM achieves 51.3% Pass@1 on HumanEvalInfilling under fully unknown lengths (+13.4% vs. DreamOn) and 51.5% average Pass@1 on four-language McEval (+14.3% vs. DreamOn).
Skin Tokens: A Learned Compact Representation for Unified Autoregressive Rigging
Feb 04, 2026The rapid proliferation of generative 3D models has created a critical bottleneck in animation pipelines: rigging. Existing automated methods are fundamentally limited by their approach to skinning, treating it as an ill-posed, high-dimensional regression task that is inefficient to optimize and is typically decoupled from skeleton generation. We posit this is a representation problem and introduce SkinTokens: a learned, compact, and discrete representation for skinning weights. By leveraging an FSQ-CVAE to capture the intrinsic sparsity of skinning, we reframe the task from continuous regression to a more tractable token sequence prediction problem. This representation enables TokenRig, a unified autoregressive framework that models the entire rig as a single sequence of skeletal parameters and SkinTokens, learning the complicated dependencies between skeletons and skin deformations. The unified model is then amenable to a reinforcement learning stage, where tailored geometric and semantic rewards improve generalization to complex, out-of-distribution assets. Quantitatively, the SkinTokens representation leads to a 98%-133% percents improvement in skinning accuracy over state-of-the-art methods, while the full TokenRig framework, refined with RL, enhances bone prediction by 17%-22%. Our work presents a unified, generative approach to rigging that yields higher fidelity and robustness, offering a scalable solution to a long-standing challenge in 3D content creation.
DEER: Draft with Diffusion, Verify with Autoregressive Models
Dec 17, 2025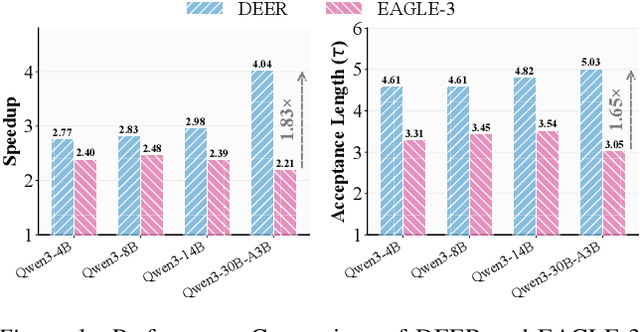
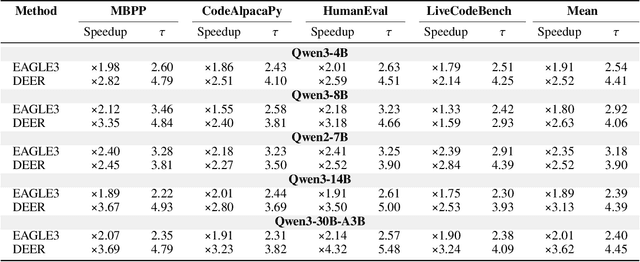
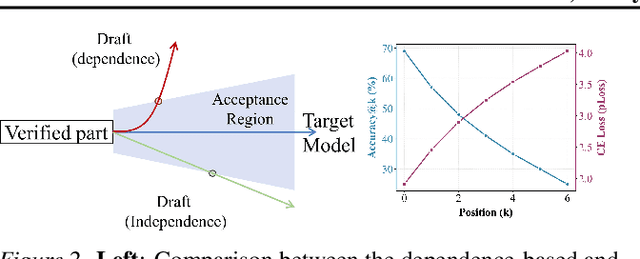
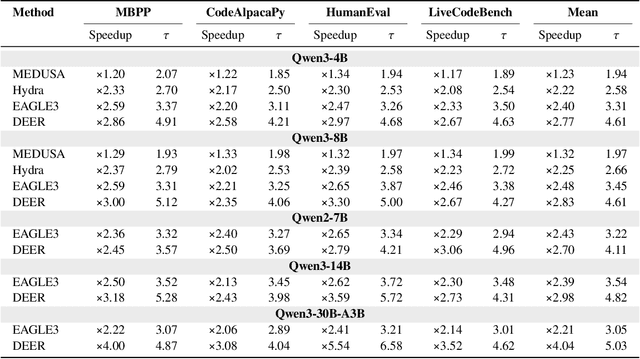
Efficiency, as a critical practical challenge for LLM-driven agentic and reasoning systems, is increasingly constrained by the inherent latency of autoregressive (AR) decoding. Speculative decoding mitigates this cost through a draft-verify scheme, yet existing approaches rely on AR draft models (a.k.a., drafters), which introduce two fundamental issues: (1) step-wise uncertainty accumulation leads to a progressive collapse of trust between the target model and the drafter, and (2) inherently sequential decoding of AR drafters. Together, these factors cause limited speedups. In this paper, we show that a diffusion large language model (dLLM) drafters can naturally overcome these issues through its fundamentally different probabilistic modeling and efficient parallel decoding strategy. Building on this insight, we introduce DEER, an efficient speculative decoding framework that drafts with diffusion and verifies with AR models. To enable high-quality drafting, DEER employs a two-stage training pipeline to align the dLLM-based drafters with the target AR model, and further adopts single-step decoding to generate long draft segments. Experiments show DEER reaches draft acceptance lengths of up to 32 tokens, far surpassing the 10 tokens achieved by EAGLE-3. Moreover, on HumanEval with Qwen3-30B-A3B, DEER attains a 5.54x speedup, while EAGLE-3 achieves only 2.41x. Code, model, demo, etc, will be available at https://czc726.github.io/DEER/
Tool-Augmented Spatiotemporal Reasoning for Streamlining Video Question Answering Task
Dec 11, 2025Video Question Answering (VideoQA) task serves as a critical playground for evaluating whether foundation models can effectively perceive, understand, and reason about dynamic real-world scenarios. However, existing Multimodal Large Language Models (MLLMs) struggle with simultaneously modeling spatial relationships within video frames and understanding the causal dynamics of temporal evolution on complex and reasoning-intensive VideoQA task. In this work, we equip MLLM with a comprehensive and extensible Video Toolkit, to enhance MLLM's spatiotemporal reasoning capabilities and ensure the harmony between the quantity and diversity of tools. To better control the tool invocation sequence and avoid toolchain shortcut issues, we propose a Spatiotemporal Reasoning Framework (STAR) that strategically schedules temporal and spatial tools, thereby progressively localizing the key area in the video. Our STAR framework enhances GPT-4o using lightweight tools, achieving an 8.2% gain on VideoMME and 4.6% on LongVideoBench. We believe that our proposed Video Toolkit and STAR framework make an important step towards building autonomous and intelligent video analysis assistants. The code is publicly available at https://github.com/fansunqi/VideoTool.
GPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
Nov 13, 2025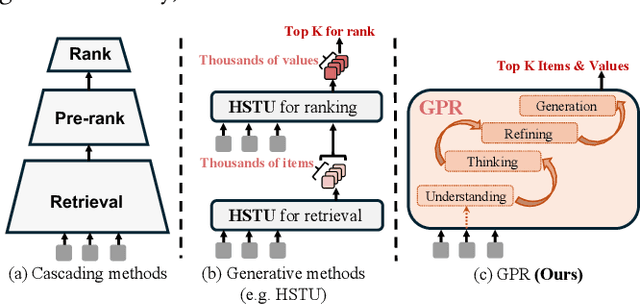
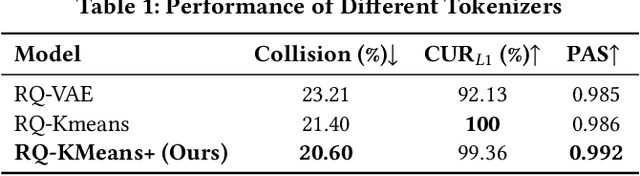
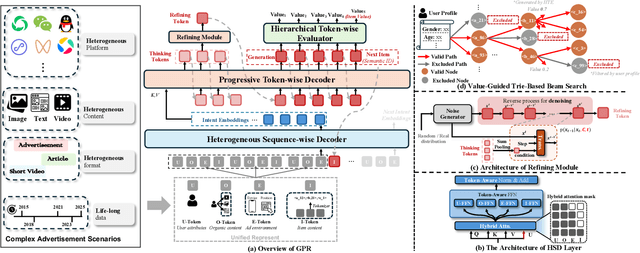
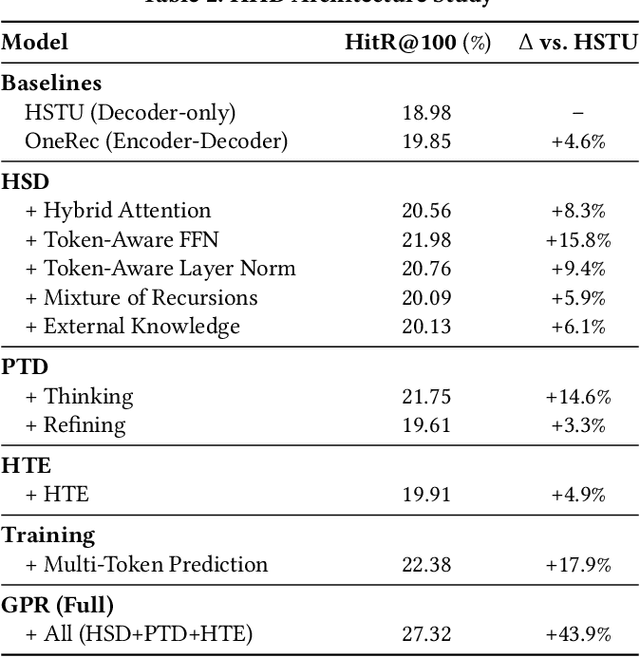
As an intelligent infrastructure connecting users with commercial content, advertising recommendation systems play a central role in information flow and value creation within the digital economy. However, existing multi-stage advertising recommendation systems suffer from objective misalignment and error propagation, making it difficult to achieve global optimality, while unified generative recommendation models still struggle to meet the demands of practical industrial applications. To address these issues, we propose GPR (Generative Pre-trained Recommender), the first one-model framework that redefines advertising recommendation as an end-to-end generative task, replacing the traditional cascading paradigm with a unified generative approach. To realize GPR, we introduce three key innovations spanning unified representation, network architecture, and training strategy. First, we design a unified input schema and tokenization method tailored to advertising scenarios, mapping both ads and organic content into a shared multi-level semantic ID space, thereby enhancing semantic alignment and modeling consistency across heterogeneous data. Second, we develop the Heterogeneous Hierarchical Decoder (HHD), a dual-decoder architecture that decouples user intent modeling from ad generation, achieving a balance between training efficiency and inference flexibility while maintaining strong modeling capacity. Finally, we propose a multi-stage joint training strategy that integrates Multi-Token Prediction (MTP), Value-Aware Fine-Tuning and the Hierarchy Enhanced Policy Optimization (HEPO) algorithm, forming a complete generative recommendation pipeline that unifies interest modeling, value alignment, and policy optimization. GPR has been fully deployed in the Tencent Weixin Channels advertising system, delivering significant improvements in key business metrics including GMV and CTCVR.
RBench-V: A Primary Assessment for Visual Reasoning Models with Multi-modal Outputs
May 22, 2025The rapid advancement of native multi-modal models and omni-models, exemplified by GPT-4o, Gemini, and o3, with their capability to process and generate content across modalities such as text and images, marks a significant milestone in the evolution of intelligence. Systematic evaluation of their multi-modal output capabilities in visual thinking processes (also known as multi-modal chain of thought, M-CoT) becomes critically important. However, existing benchmarks for evaluating multi-modal models primarily focus on assessing multi-modal inputs and text-only reasoning while neglecting the importance of reasoning through multi-modal outputs. In this paper, we present a benchmark, dubbed RBench-V, designed to assess models' vision-indispensable reasoning abilities. To construct RBench-V, we carefully hand-pick 803 questions covering math, physics, counting, and games. Unlike previous benchmarks that typically specify certain input modalities, RBench-V presents problems centered on multi-modal outputs, which require image manipulation such as generating novel images and constructing auxiliary lines to support the reasoning process. We evaluate numerous open- and closed-source models on RBench-V, including o3, Gemini 2.5 Pro, Qwen2.5-VL, etc. Even the best-performing model, o3, achieves only 25.8% accuracy on RBench-V, far below the human score of 82.3%, highlighting that current models struggle to leverage multi-modal reasoning. Data and code are available at https://evalmodels.github.io/rbenchv
R-Bench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning Evaluation
May 04, 2025Reasoning stands as a cornerstone of intelligence, enabling the synthesis of existing knowledge to solve complex problems. Despite remarkable progress, existing reasoning benchmarks often fail to rigorously evaluate the nuanced reasoning capabilities required for complex, real-world problemsolving, particularly in multi-disciplinary and multimodal contexts. In this paper, we introduce a graduate-level, multi-disciplinary, EnglishChinese benchmark, dubbed as Reasoning Bench (R-Bench), for assessing the reasoning capability of both language and multimodal models. RBench spans 1,094 questions across 108 subjects for language model evaluation and 665 questions across 83 subjects for multimodal model testing in both English and Chinese. These questions are meticulously curated to ensure rigorous difficulty calibration, subject balance, and crosslinguistic alignment, enabling the assessment to be an Olympiad-level multi-disciplinary benchmark. We evaluate widely used models, including OpenAI o1, GPT-4o, DeepSeek-R1, etc. Experimental results indicate that advanced models perform poorly on complex reasoning, especially multimodal reasoning. Even the top-performing model OpenAI o1 achieves only 53.2% accuracy on our multimodal evaluation. Data and code are made publicly available at here.