 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Inpainting: Unleash 3D Understanding for Precise Camera-Controlled Video Generation
Jan 15, 2026Camera control has been extensively studied in conditioned video generation; however, performing precisely altering the camera trajectories while faithfully preserving the video content remains a challenging task. The mainstream approach to achieving precise camera control is warping a 3D representation according to the target trajectory. However, such methods fail to fully leverage the 3D priors of video diffusion models (VDMs) and often fall into the Inpainting Trap, resulting in subject inconsistency and degraded generation quality. To address this problem, we propose DepthDirector, a video re-rendering framework with precise camera controllability. By leveraging the depth video from explicit 3D representation as camera-control guidance, our method can faithfully reproduce the dynamic scene of an input video under novel camera trajectories. Specifically, we design a View-Content Dual-Stream Condition mechanism that injects both the source video and the warped depth sequence rendered under the target viewpoint into the pretrained video generation model. This geometric guidance signal enables VDMs to comprehend camera movements and leverage their 3D understanding capabilities, thereby facilitating precise camera control and consistent content generation. Next, we introduce a lightweight LoRA-based video diffusion adapter to train our framework, fully preserving the knowledge priors of VDMs. Additionally, we construct a large-scale multi-camera synchronized dataset named MultiCam-WarpData using Unreal Engine 5, containing 8K videos across 1K dynamic scenes. Extensive experiments show that DepthDirector outperforms existing methods in both camera controllability and visual quality. Our code and dataset will be publicly available.
Tool-Augmented Spatiotemporal Reasoning for Streamlining Video Question Answering Task
Dec 11, 2025Video Question Answering (VideoQA) task serves as a critical playground for evaluating whether foundation models can effectively perceive, understand, and reason about dynamic real-world scenarios. However, existing Multimodal Large Language Models (MLLMs) struggle with simultaneously modeling spatial relationships within video frames and understanding the causal dynamics of temporal evolution on complex and reasoning-intensive VideoQA task. In this work, we equip MLLM with a comprehensive and extensible Video Toolkit, to enhance MLLM's spatiotemporal reasoning capabilities and ensure the harmony between the quantity and diversity of tools. To better control the tool invocation sequence and avoid toolchain shortcut issues, we propose a Spatiotemporal Reasoning Framework (STAR) that strategically schedules temporal and spatial tools, thereby progressively localizing the key area in the video. Our STAR framework enhances GPT-4o using lightweight tools, achieving an 8.2% gain on VideoMME and 4.6% on LongVideoBench. We believe that our proposed Video Toolkit and STAR framework make an important step towards building autonomous and intelligent video analysis assistants. The code is publicly available at https://github.com/fansunqi/VideoTool.
GPR: Towards a Generative Pre-trained One-Model Paradigm for Large-Scale Advertising Recommendation
Nov 13, 2025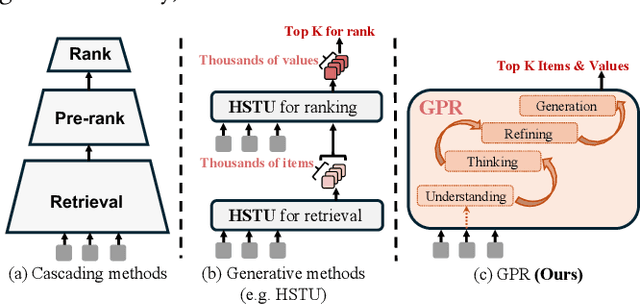
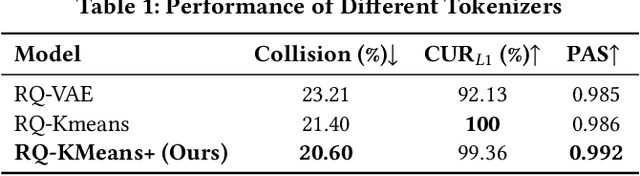
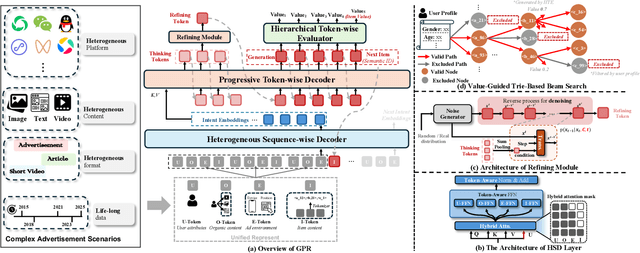
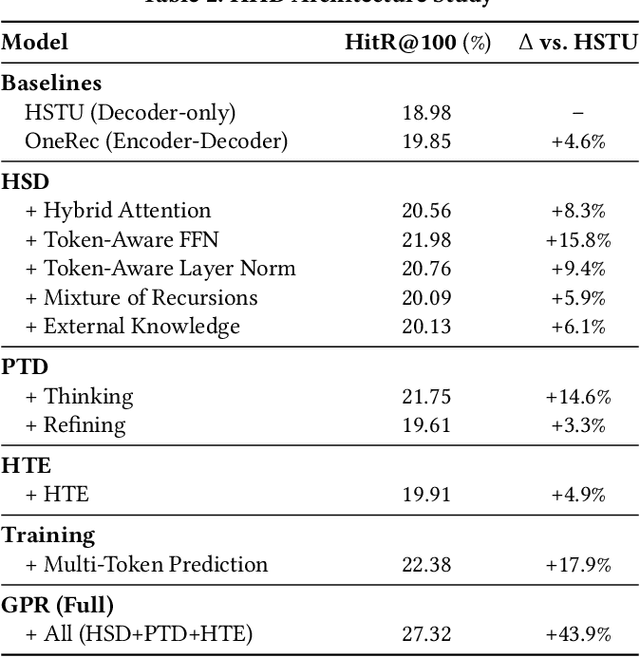
As an intelligent infrastructure connecting users with commercial content, advertising recommendation systems play a central role in information flow and value creation within the digital economy. However, existing multi-stage advertising recommendation systems suffer from objective misalignment and error propagation, making it difficult to achieve global optimality, while unified generative recommendation models still struggle to meet the demands of practical industrial applications. To address these issues, we propose GPR (Generative Pre-trained Recommender), the first one-model framework that redefines advertising recommendation as an end-to-end generative task, replacing the traditional cascading paradigm with a unified generative approach. To realize GPR, we introduce three key innovations spanning unified representation, network architecture, and training strategy. First, we design a unified input schema and tokenization method tailored to advertising scenarios, mapping both ads and organic content into a shared multi-level semantic ID space, thereby enhancing semantic alignment and modeling consistency across heterogeneous data. Second, we develop the Heterogeneous Hierarchical Decoder (HHD), a dual-decoder architecture that decouples user intent modeling from ad generation, achieving a balance between training efficiency and inference flexibility while maintaining strong modeling capacity. Finally, we propose a multi-stage joint training strategy that integrates Multi-Token Prediction (MTP), Value-Aware Fine-Tuning and the Hierarchy Enhanced Policy Optimization (HEPO) algorithm, forming a complete generative recommendation pipeline that unifies interest modeling, value alignment, and policy optimization. GPR has been fully deployed in the Tencent Weixin Channels advertising system, delivering significant improvements in key business metrics including GMV and CTCVR.
Agentic Keyframe Search for Video Question Answering
Mar 20, 2025Video question answering (VideoQA) enables machines to extract and comprehend key information from videos through natural language interaction, which is a critical step towards achieving intelligence. However, the demand for a thorough understanding of videos and high computational costs still limit the widespread applications of VideoQA. To address it, we propose Agentic Keyframe Search (AKeyS), a simple yet powerful algorithm for identifying keyframes in the VideoQA task. It can effectively distinguish key information from redundant, irrelevant content by leveraging modern language agents to direct classical search algorithms. Specifically, we first segment the video and organize it as a tree structure. Then, AKeyS uses a language agent to estimate heuristics and movement costs while dynamically expanding nodes. Finally, the agent determines if sufficient keyframes have been collected based on termination conditions and provides answers. Extensive experiments on the EgoSchema and NExT-QA datasets show that AKeyS outperforms all previous methods with the highest keyframe searching efficiency, which means it can accurately identify key information and conduct effective visual reasoning with minimal computational overhead. For example, on the EgoSchema subset, it achieves 1.8% higher accuracy while processing only 43.5% of the frames compared to VideoTree. We believe that AKeyS represents a significant step towards building intelligent agents for video understanding. The code is publicly available at https://github.com/fansunqi/AKeyS.
Semantic-Aware Label Placement for Augmented Reality in Street View
Dec 15, 2019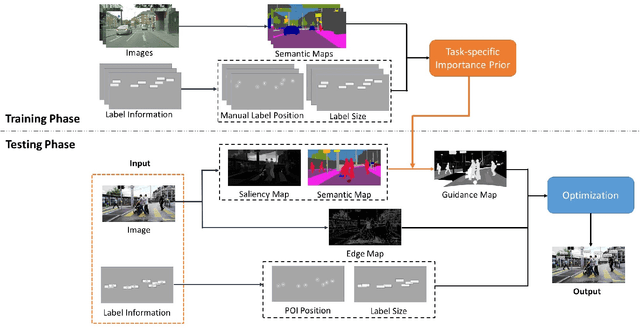

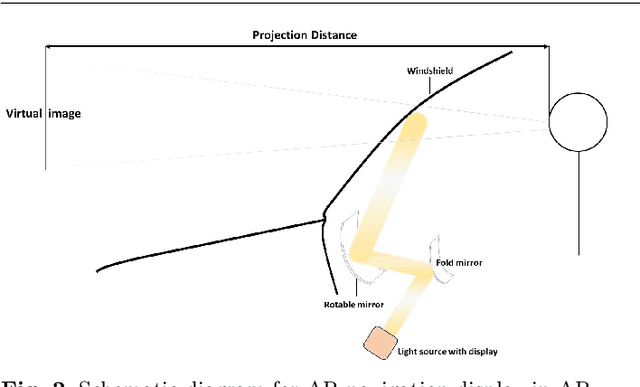
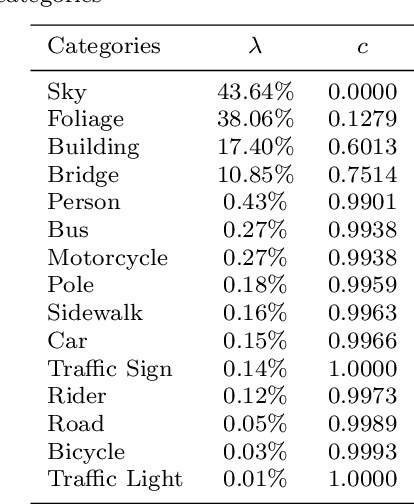
In an augmented reality (AR) application, placing labels in a manner that is clear and readable without occluding the critical information from the real-world can be a challenging problem. This paper introduces a label placement technique for AR used in street view scenarios. We propose a semantic-aware task-specific label placement method by identifying potentially important image regions through a novel feature map, which we refer to as guidance map. Given an input image, its saliency information, semantic information and the task-specific importance prior are integrated into the guidance map for our labeling task. To learn the task prior, we created a label placement dataset with the users' labeling preferences, as well as use it for evaluation. Our solution encodes the constraints for placing labels in an optimization problem to obtain the final label layout, and the labels will be placed in appropriate positions to reduce the chances of overlaying important real-world objects in street view AR scenarios. The experimental validation shows clearly the benefits of our method over previous solutions in the AR street view navigation and similar applications.