 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Range Pooling for 3D Large-Scale Scene Understanding
Jan 17, 2023Inspired by the success of recent vision transformers and large kernel design in convolutional neural networks (CNNs), in this paper, we analyze and explore essential reasons for their success. We claim two factors that are critical for 3D large-scale scene understanding: a larger receptive field and operations with greater non-linearity. The former is responsible for providing long range contexts and the latter can enhance the capacity of the network. To achieve the above properties, we propose a simple yet effective long range pooling (LRP) module using dilation max pooling, which provides a network with a large adaptive receptive field. LRP has few parameters, and can be readily added to current CNNs. Also, based on LRP, we present an entire network architecture, LRPNet, for 3D understanding. Ablation studies are presented to support our claims, and show that the LRP module achieves better results than large kernel convolution yet with reduced computation, due to its nonlinearity. We also demonstrate the superiority of LRPNet on various benchmarks: LRPNet performs the best on ScanNet and surpasses other CNN-based methods on S3DIS and Matterport3D. Code will be made publicly available.
Attention Mechanisms in Computer Vision: A Survey
Nov 15, 2021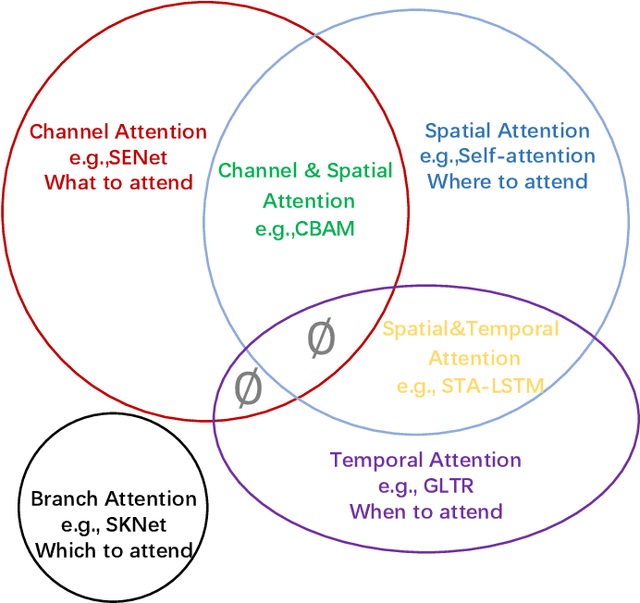

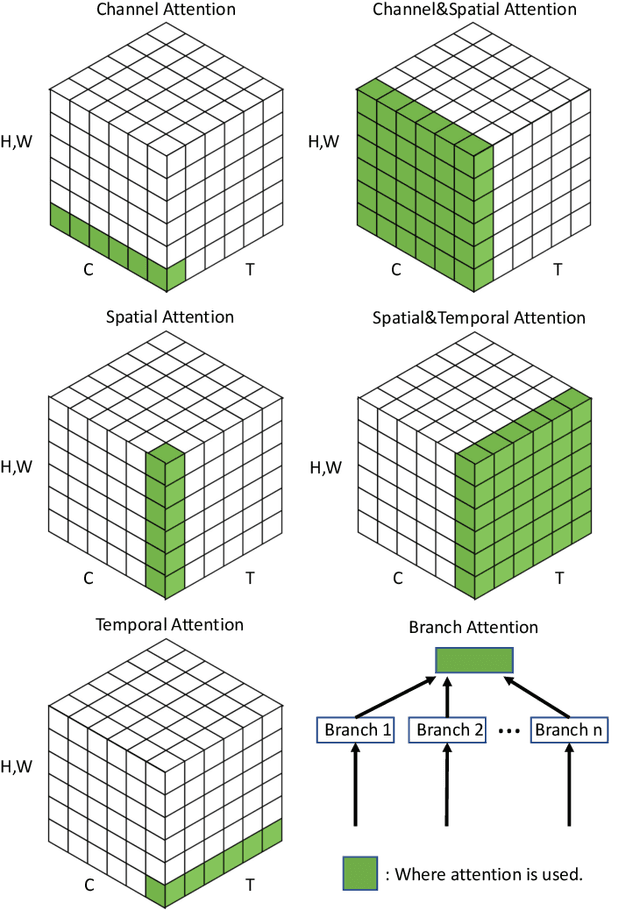
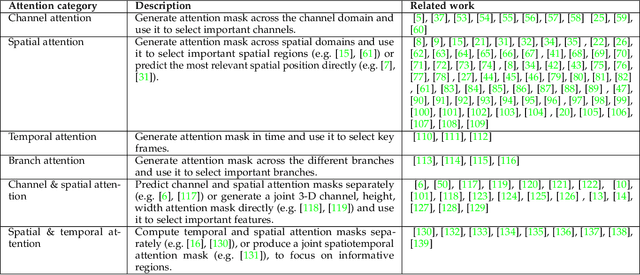
Humans can naturally and effectively find salient regions in complex scenes. Motivated by this observation, attention mechanisms were introduced into computer vision with the aim of imitating this aspect of the human visual system. Such an attention mechanism can be regarded as a dynamic weight adjustment process based on features of the input image. Attention mechanisms have achieved great success in many visual tasks, including image classification, object detection, semantic segmentation, video understanding, image generation, 3D vision, multi-modal tasks and self-supervised learning. In this survey, we provide a comprehensive review of various attention mechanisms in computer vision and categorize them according to approach, such as channel attention, spatial attention, temporal attention and branch attention; a related repository https://github.com/MenghaoGuo/Awesome-Vision-Attentions is dedicated to collecting related work. We also suggest future directions for attention mechanism research.
Sampling Equivariant Self-attention Networks for Object Detection in Aerial Images
Nov 05, 2021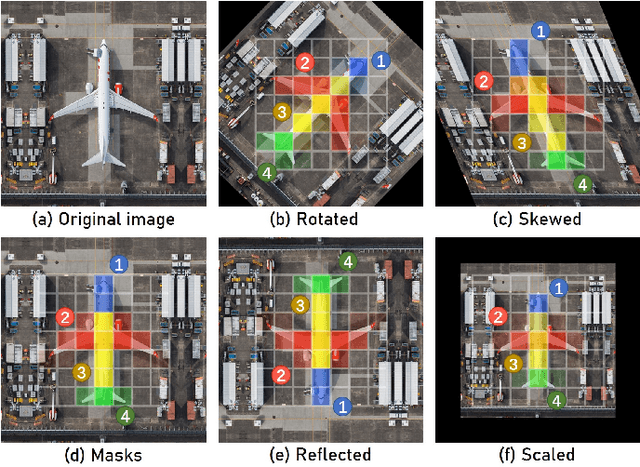
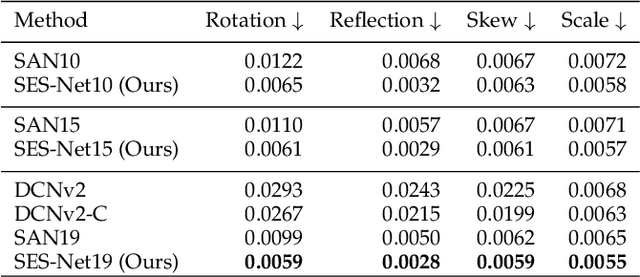
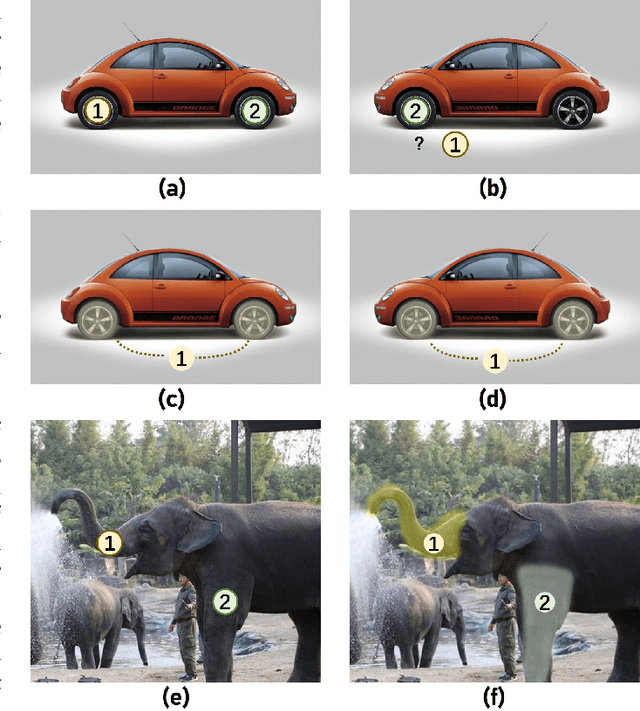
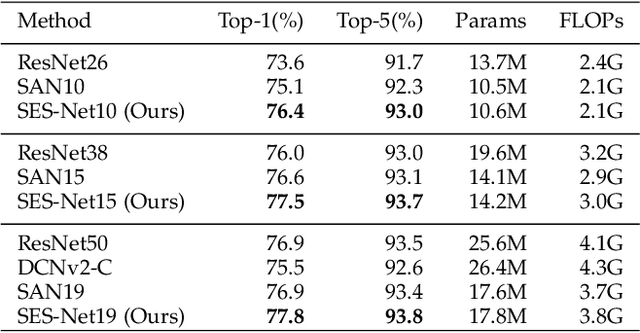
Objects in aerial images have greater variations in scale and orientation than in typical images, so detection is more difficult. Convolutional neural networks use a variety of frequency- and orientation-specific kernels to identify objects subject to different transformations; these require many parameters. Sampling equivariant networks can adjust sampling from input feature maps according to the transformation of the object, allowing a kernel to extract features of an object under different transformations. Doing so requires fewer parameters, and makes the network more suitable for representing deformable objects, like those in aerial images. However, methods like deformable convolutional networks can only provide sampling equivariance under certain circumstances, because of the locations used for sampling. We propose sampling equivariant self-attention networks which consider self-attention restricted to a local image patch as convolution sampling with masks instead of locations, and design a transformation embedding module to further improve the equivariant sampling ability. We also use a novel randomized normalization module to tackle overfitting due to limited aerial image data. We show that our model (i) provides significantly better sampling equivariance than existing methods, without additional supervision, (ii) provides improved classification on ImageNet, and (iii) achieves state-of-the-art results on the DOTA dataset, without increased computation.
Subdivision-Based Mesh Convolution Networks
Jun 04, 2021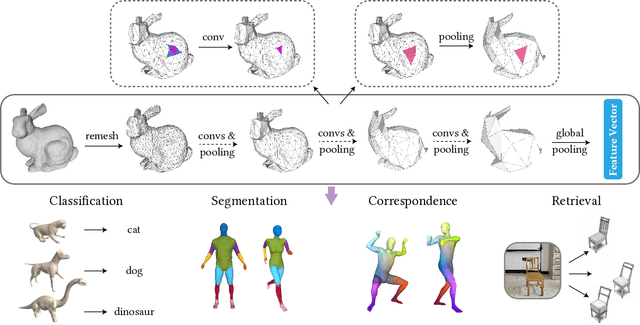
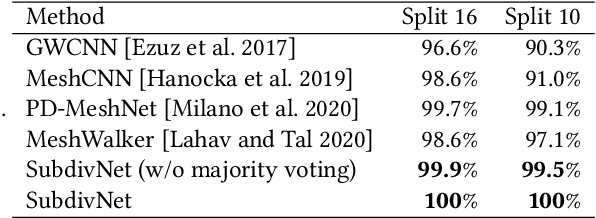
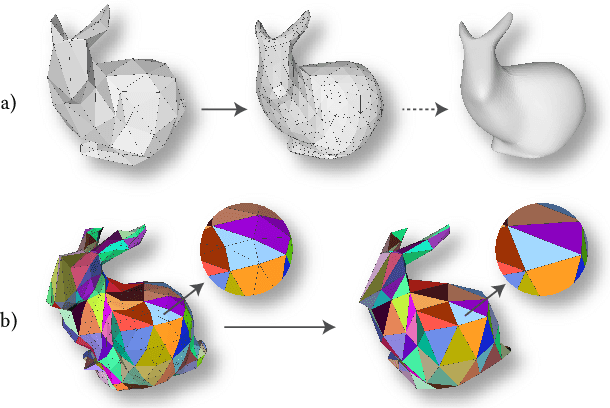
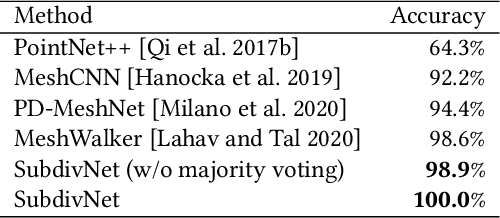
Convolutional neural networks (CNNs) have made great breakthroughs in 2D computer vision. However, the irregular structure of meshes makes it hard to exploit the power of CNNs directly. A subdivision surface provides a hierarchical multi-resolution structure, and each face in a closed 2-manifold triangle mesh is exactly adjacent to three faces. Motivated by these two properties, this paper introduces a novel and flexible CNN framework, named SubdivNet, for 3D triangle meshes with Loop subdivision sequence connectivity. Making an analogy between mesh faces and pixels in a 2D image allows us to present a mesh convolution operator to aggregate local features from adjacent faces. By exploiting face neighborhoods, this convolution can support standard 2D convolutional network concepts, e.g. variable kernel size, stride, and dilation. Based on the multi-resolution hierarchy, we propose a spatial uniform pooling layer which merges four faces into one and an upsampling method which splits one face into four. As a result, many popular 2D CNN architectures can be readily adapted to processing 3D meshes. Meshes with arbitrary connectivity can be remeshed to hold Loop subdivision sequence connectivity via self-parameterization, making SubdivNet a general approach. Experiments on mesh classification, segmentation, correspondence, and retrieval from the real-world demonstrate the effectiveness and efficiency of SubdivNet.
Can Attention Enable MLPs To Catch Up With CNNs?
May 31, 2021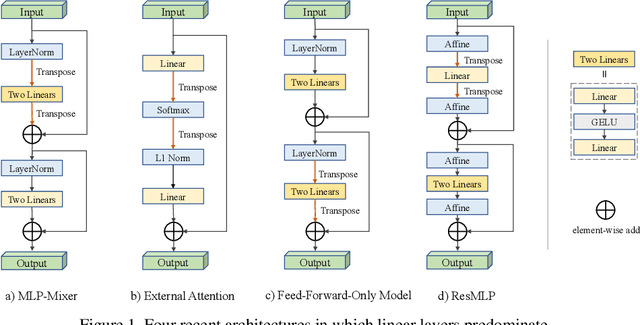
In the first week of May, 2021, researchers from four different institutions: Google, Tsinghua University, Oxford University and Facebook, shared their latest work [16, 7, 12, 17] on arXiv.org almost at the same time, each proposing new learning architectures, consisting mainly of linear layers, claiming them to be comparable, or even superior to convolutional-based models. This sparked immediate discussion and debate in both academic and industrial communities as to whether MLPs are sufficient, many thinking that learning architectures are returning to MLPs. Is this true? In this perspective, we give a brief history of learning architectures, including multilayer perceptrons (MLPs), convolutional neural networks (CNNs) and transformers. We then examine what the four newly proposed architectures have in common. Finally, we give our views on challenges and directions for new learning architectures, hoping to inspire future research.
PCT: Point Cloud Transformer
Dec 17, 2020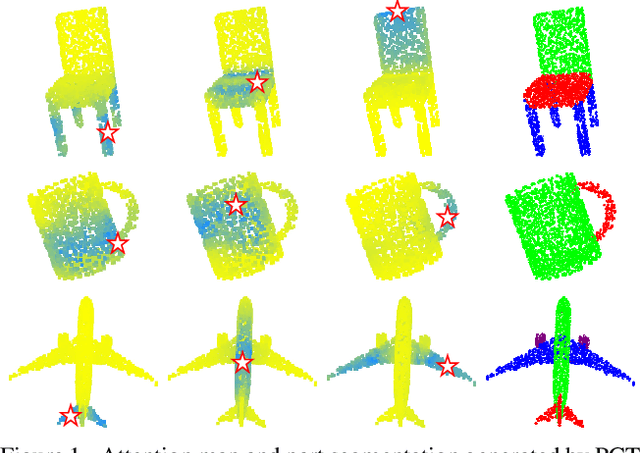
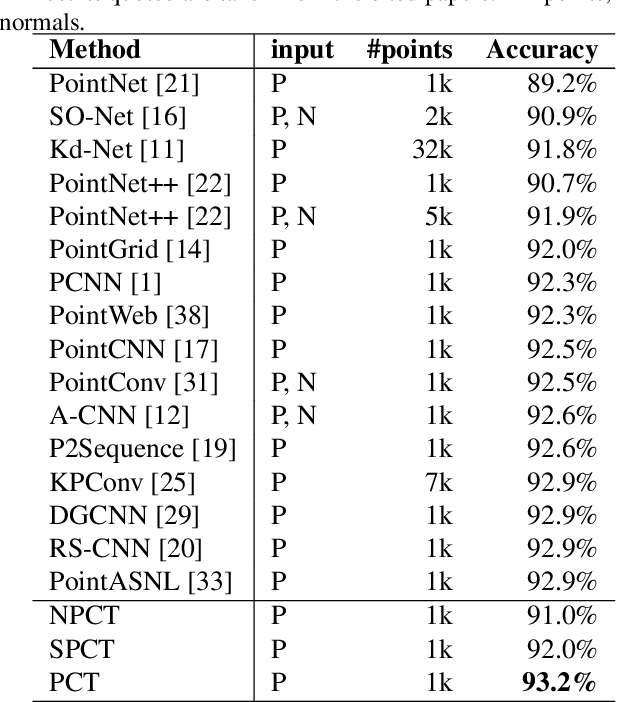

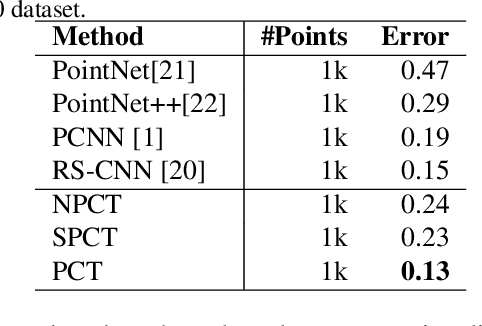
The irregular domain and lack of ordering make it challenging to design deep neural networks for point cloud processing. This paper presents a novel framework named Point Cloud Transformer(PCT) for point cloud learning. PCT is based on Transformer, which achieves huge success in natural language processing and displays great potential in image processing. It is inherently permutation invariant for processing a sequence of points, making it well-suited for point cloud learning. To better capture local context within the point cloud, we enhance input embedding with the support of farthest point sampling and nearest neighbor search. Extensive experiments demonstrate that the PCT achieves the state-of-the-art performance on shape classification, part segmentation and normal estimation tasks.