 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Attention Network
Mar 08, 2022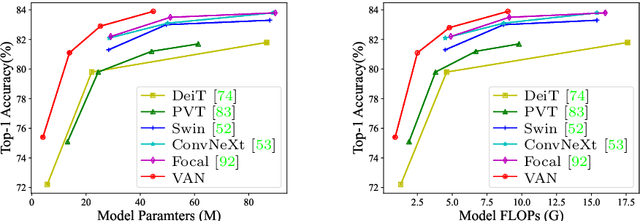

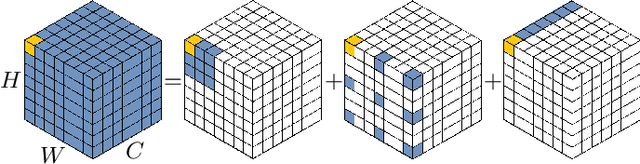

While originally designed for natural language processing tasks, the self-attention mechanism has recently taken various computer vision areas by storm. However, the 2D nature of images brings three challenges for applying self-attention in computer vision. (1) Treating images as 1D sequences neglects their 2D structures. (2) The quadratic complexity is too expensive for high-resolution images. (3) It only captures spatial adaptability but ignores channel adaptability. In this paper, we propose a novel large kernel attention (LKA) module to enable self-adaptive and long-range correlations in self-attention while avoiding the above issues. We further introduce a novel neural network based on LKA, namely Visual Attention Network (VAN). While extremely simple, VAN outperforms the state-of-the-art vision transformers and convolutional neural networks with a large margin in extensive experiments, including image classification, object detection, semantic segmentation, instance segmentation, etc. Code is available at https://github.com/Visual-Attention-Network.
Attention Mechanisms in Computer Vision: A Survey
Nov 15, 2021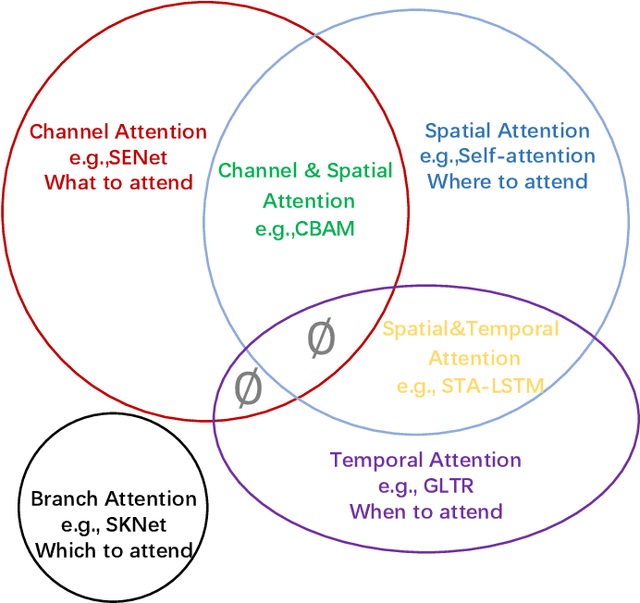

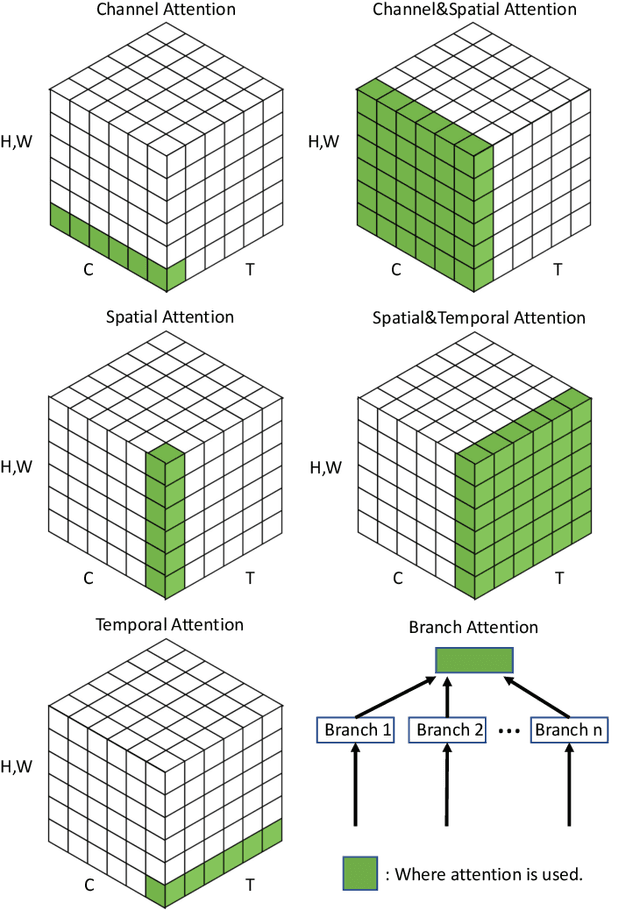
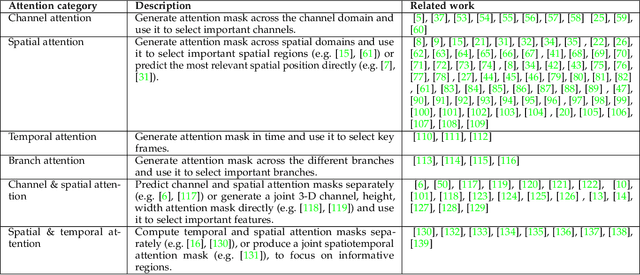
Humans can naturally and effectively find salient regions in complex scenes. Motivated by this observation, attention mechanisms were introduced into computer vision with the aim of imitating this aspect of the human visual system. Such an attention mechanism can be regarded as a dynamic weight adjustment process based on features of the input image. Attention mechanisms have achieved great success in many visual tasks, including image classification, object detection, semantic segmentation, video understanding, image generation, 3D vision, multi-modal tasks and self-supervised learning. In this survey, we provide a comprehensive review of various attention mechanisms in computer vision and categorize them according to approach, such as channel attention, spatial attention, temporal attention and branch attention; a related repository https://github.com/MenghaoGuo/Awesome-Vision-Attentions is dedicated to collecting related work. We also suggest future directions for attention mechanism research.
Subdivision-Based Mesh Convolution Networks
Jun 04, 2021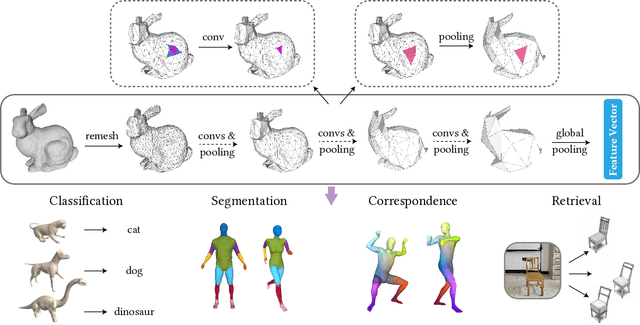
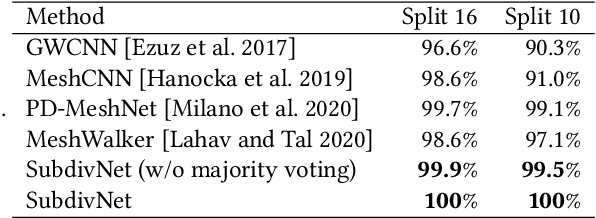
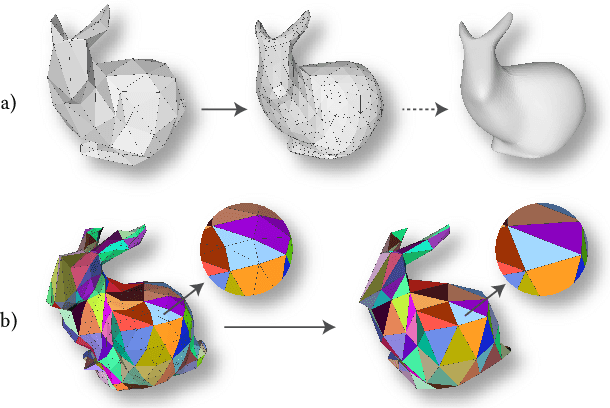
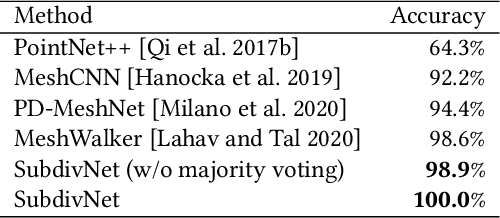
Convolutional neural networks (CNNs) have made great breakthroughs in 2D computer vision. However, the irregular structure of meshes makes it hard to exploit the power of CNNs directly. A subdivision surface provides a hierarchical multi-resolution structure, and each face in a closed 2-manifold triangle mesh is exactly adjacent to three faces. Motivated by these two properties, this paper introduces a novel and flexible CNN framework, named SubdivNet, for 3D triangle meshes with Loop subdivision sequence connectivity. Making an analogy between mesh faces and pixels in a 2D image allows us to present a mesh convolution operator to aggregate local features from adjacent faces. By exploiting face neighborhoods, this convolution can support standard 2D convolutional network concepts, e.g. variable kernel size, stride, and dilation. Based on the multi-resolution hierarchy, we propose a spatial uniform pooling layer which merges four faces into one and an upsampling method which splits one face into four. As a result, many popular 2D CNN architectures can be readily adapted to processing 3D meshes. Meshes with arbitrary connectivity can be remeshed to hold Loop subdivision sequence connectivity via self-parameterization, making SubdivNet a general approach. Experiments on mesh classification, segmentation, correspondence, and retrieval from the real-world demonstrate the effectiveness and efficiency of SubdivNet.
Can Attention Enable MLPs To Catch Up With CNNs?
May 31, 2021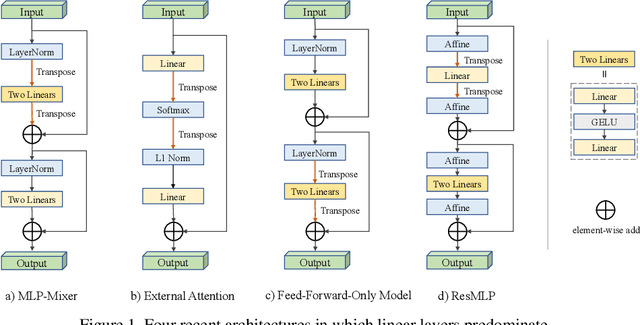
In the first week of May, 2021, researchers from four different institutions: Google, Tsinghua University, Oxford University and Facebook, shared their latest work [16, 7, 12, 17] on arXiv.org almost at the same time, each proposing new learning architectures, consisting mainly of linear layers, claiming them to be comparable, or even superior to convolutional-based models. This sparked immediate discussion and debate in both academic and industrial communities as to whether MLPs are sufficient, many thinking that learning architectures are returning to MLPs. Is this true? In this perspective, we give a brief history of learning architectures, including multilayer perceptrons (MLPs), convolutional neural networks (CNNs) and transformers. We then examine what the four newly proposed architectures have in common. Finally, we give our views on challenges and directions for new learning architectures, hoping to inspire future research.
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks
May 31, 2021



Attention mechanisms, especially self-attention, have played an increasingly important role in deep feature representation for visual tasks. Self-attention updates the feature at each position by computing a weighted sum of features using pair-wise affinities across all positions to capture the long-range dependency within a single sample. However, self-attention has quadratic complexity and ignores potential correlation between different samples. This paper proposes a novel attention mechanism which we call external attention, based on two external, small, learnable, shared memories, which can be implemented easily by simply using two cascaded linear layers and two normalization layers; it conveniently replaces self-attention in existing popular architectures. External attention has linear complexity and implicitly considers the correlations between all data samples. We further incorporate the multi-head mechanism into external attention to provide an all-MLP architecture, external attention MLP (EAMLP), for image classification. Extensive experiments on image classification, object detection, semantic segmentation, instance segmentation, image generation, and point cloud analysis reveal that our method provides results comparable or superior to the self-attention mechanism and some of its variants, with much lower computational and memory costs.
PCT: Point Cloud Transformer
Dec 17, 2020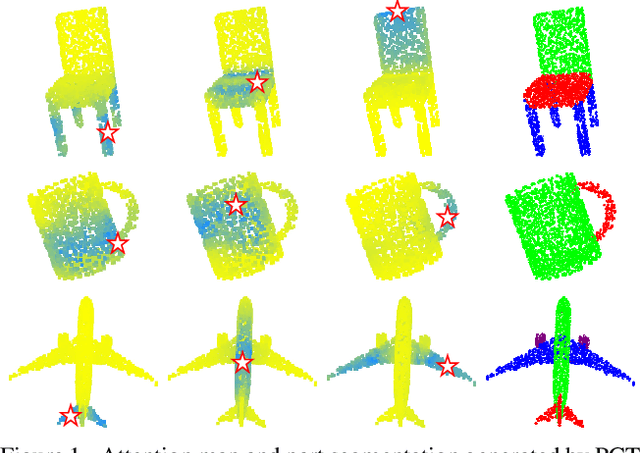
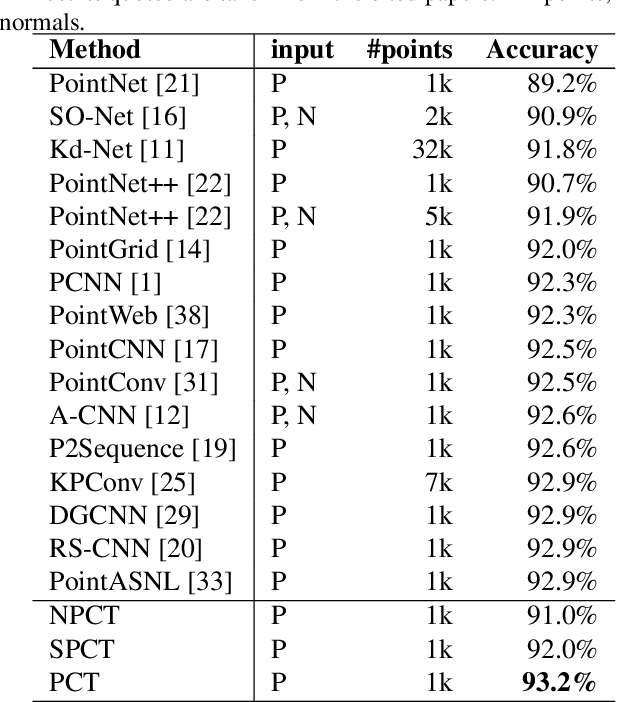

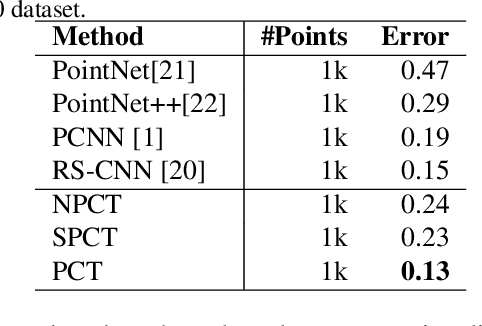
The irregular domain and lack of ordering make it challenging to design deep neural networks for point cloud processing. This paper presents a novel framework named Point Cloud Transformer(PCT) for point cloud learning. PCT is based on Transformer, which achieves huge success in natural language processing and displays great potential in image processing. It is inherently permutation invariant for processing a sequence of points, making it well-suited for point cloud learning. To better capture local context within the point cloud, we enhance input embedding with the support of farthest point sampling and nearest neighbor search. Extensive experiments demonstrate that the PCT achieves the state-of-the-art performance on shape classification, part segmentation and normal estimation tasks.