 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Remember: Alleviating Visual Forgetting in Efficient MLLM with Vision Feature Resample
Jun 04, 2025In this work, we study the Efficient Multimodal Large Language Model. Redundant vision tokens consume a significant amount of computational memory and resources. Therefore, many previous works compress them in the Vision Projector to reduce the number of vision tokens. However, simply compressing in the Vision Projector can lead to the loss of visual information, especially for tasks that rely on fine-grained spatial relationships, such as OCR and Chart \& Table Understanding. To address this problem, we propose Vision Remember, which is inserted between the LLM decoder layers to allow vision tokens to re-memorize vision features. Specifically, we retain multi-level vision features and resample them with the vision tokens that have interacted with the text token. During the resampling process, each vision token only attends to a local region in vision features, which is referred to as saliency-enhancing local attention. Saliency-enhancing local attention not only improves computational efficiency but also captures more fine-grained contextual information and spatial relationships within the region. Comprehensive experiments on multiple visual understanding benchmarks validate the effectiveness of our method when combined with various Efficient Vision Projectors, showing performance gains without sacrificing efficiency. Based on Vision Remember, LLaVA-VR with only 2B parameters is also superior to previous representative MLLMs such as Tokenpacker-HD-7B and DeepSeek-VL-7B.
Descriptive Caption Enhancement with Visual Specialists for Multimodal Perception
Dec 18, 2024



Training Large Multimodality Models (LMMs) relies on descriptive image caption that connects image and language. Existing methods either distill the caption from the LMM models or construct the captions from the internet images or by human. We propose to leverage off-the-shelf visual specialists, which were trained from annotated images initially not for image captioning, for enhancing the image caption. Our approach, named DCE, explores object low-level and fine-grained attributes (e.g., depth, emotion and fine-grained categories) and object relations (e.g., relative location and human-object-interaction (HOI)), and combine the attributes into the descriptive caption. Experiments demonstrate that such visual specialists are able to improve the performance for visual understanding tasks as well as reasoning that benefits from more accurate visual understanding. We will release the source code and the pipeline so that other visual specialists are easily combined into the pipeline. The complete source code of DCE pipeline and datasets will be available at \url{https://github.com/syp2ysy/DCE}.
EasyChauffeur: A Baseline Advancing Simplicity and Efficiency on Waymax
Aug 29, 2024



Recent advancements in deep-learning-based driving planners have primarily focused on elaborate network engineering, yielding limited improvements. This paper diverges from conventional approaches by exploring three fundamental yet underinvestigated aspects: training policy, data efficiency, and evaluation robustness. We introduce EasyChauffeur, a reproducible and effective planner for both imitation learning (IL) and reinforcement learning (RL) on Waymax, a GPU-accelerated simulator. Notably, our findings indicate that the incorporation of on-policy RL significantly boosts performance and data efficiency. To further enhance this efficiency, we propose SNE-Sampling, a novel method that selectively samples data from the encoder's latent space, substantially improving EasyChauffeur's performance with RL. Additionally, we identify a deficiency in current evaluation methods, which fail to accurately assess the robustness of different planners due to significant performance drops from minor changes in the ego vehicle's initial state. In response, we propose Ego-Shifting, a new evaluation setting for assessing planners' robustness. Our findings advocate for a shift from a primary focus on network architectures to adopting a holistic approach encompassing training strategies, data efficiency, and robust evaluation methods.
Group Pose: A Simple Baseline for End-to-End Multi-person Pose Estimation
Aug 14, 2023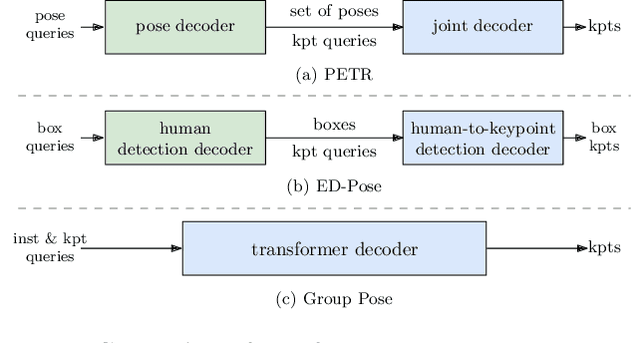

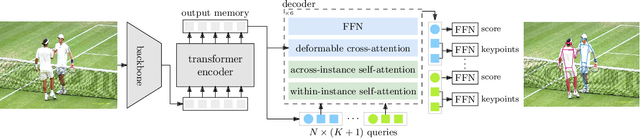
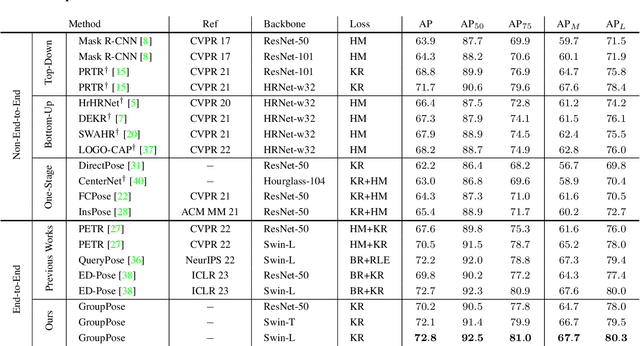
In this paper, we study the problem of end-to-end multi-person pose estimation. State-of-the-art solutions adopt the DETR-like framework, and mainly develop the complex decoder, e.g., regarding pose estimation as keypoint box detection and combining with human detection in ED-Pose, hierarchically predicting with pose decoder and joint (keypoint) decoder in PETR. We present a simple yet effective transformer approach, named Group Pose. We simply regard $K$-keypoint pose estimation as predicting a set of $N\times K$ keypoint positions, each from a keypoint query, as well as representing each pose with an instance query for scoring $N$ pose predictions. Motivated by the intuition that the interaction, among across-instance queries of different types, is not directly helpful, we make a simple modification to decoder self-attention. We replace single self-attention over all the $N\times(K+1)$ queries with two subsequent group self-attentions: (i) $N$ within-instance self-attention, with each over $K$ keypoint queries and one instance query, and (ii) $(K+1)$ same-type across-instance self-attention, each over $N$ queries of the same type. The resulting decoder removes the interaction among across-instance type-different queries, easing the optimization and thus improving the performance. Experimental results on MS COCO and CrowdPose show that our approach without human box supervision is superior to previous methods with complex decoders, and even is slightly better than ED-Pose that uses human box supervision. $\href{https://github.com/Michel-liu/GroupPose-Paddle}{\rm Paddle}$ and $\href{https://github.com/Michel-liu/GroupPose}{\rm PyTorch}$ code are available.
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
May 17, 2023



Modern autonomous driving systems are typically divided into three main tasks: perception, prediction, and planning. The planning task involves predicting the trajectory of the ego vehicle based on inputs from both internal intention and the external environment, and manipulating the vehicle accordingly. Most existing works evaluate their performance on the nuScenes dataset using the L2 error and collision rate between the predicted trajectories and the ground truth. In this paper, we reevaluate these existing evaluation metrics and explore whether they accurately measure the superiority of different methods. Specifically, we design an MLP-based method that takes raw sensor data (e.g., past trajectory, velocity, etc.) as input and directly outputs the future trajectory of the ego vehicle, without using any perception or prediction information such as camera images or LiDAR. Surprisingly, such a simple method achieves state-of-the-art end-to-end planning performance on the nuScenes dataset, reducing the average L2 error by about 30%. We further conduct in-depth analysis and provide new insights into the factors that are critical for the success of the planning task on nuScenes dataset. Our observation also indicates that we need to rethink the current open-loop evaluation scheme of end-to-end autonomous driving in nuScenes. Codes are available at https://github.com/E2E-AD/AD-MLP.
SLAN: Self-Locator Aided Network for Cross-Modal Understanding
Dec 08, 2022



Learning fine-grained interplay between vision and language allows to a more accurate understanding for VisionLanguage tasks. However, it remains challenging to extract key image regions according to the texts for semantic alignments. Most existing works are either limited by textagnostic and redundant regions obtained with the frozen detectors, or failing to scale further due to its heavy reliance on scarce grounding (gold) data to pre-train detectors. To solve these problems, we propose Self-Locator Aided Network (SLAN) for cross-modal understanding tasks without any extra gold data. SLAN consists of a region filter and a region adaptor to localize regions of interest conditioned on different texts. By aggregating cross-modal information, the region filter selects key regions and the region adaptor updates their coordinates with text guidance. With detailed region-word alignments, SLAN can be easily generalized to many downstream tasks. It achieves fairly competitive results on five cross-modal understanding tasks (e.g., 85.7% and 69.2% on COCO image-to-text and text-to-image retrieval, surpassing previous SOTA methods). SLAN also demonstrates strong zero-shot and fine-tuned transferability to two localization tasks.
ECO-TR: Efficient Correspondences Finding Via Coarse-to-Fine Refinement
Sep 25, 2022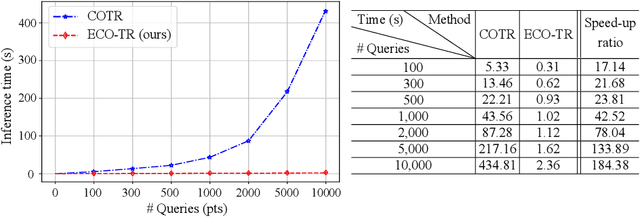
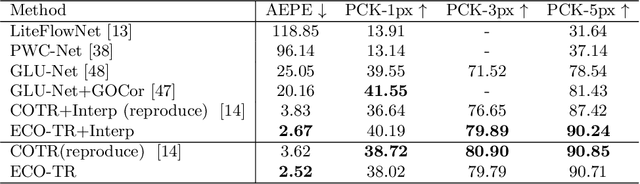
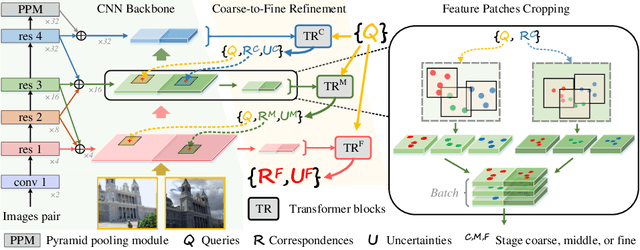
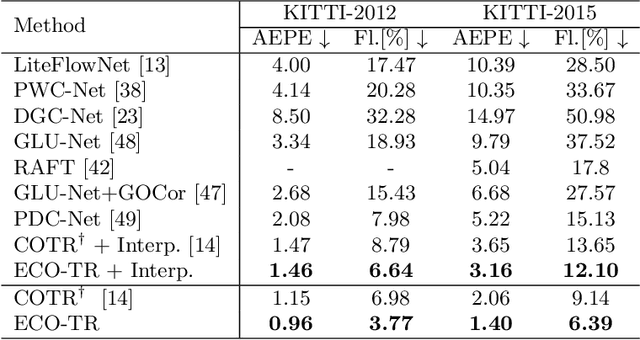
Modeling sparse and dense image matching within a unified functional correspondence model has recently attracted increasing research interest. However, existing efforts mainly focus on improving matching accuracy while ignoring its efficiency, which is crucial for realworld applications. In this paper, we propose an efficient structure named Efficient Correspondence Transformer (ECO-TR) by finding correspondences in a coarse-to-fine manner, which significantly improves the efficiency of functional correspondence model. To achieve this, multiple transformer blocks are stage-wisely connected to gradually refine the predicted coordinates upon a shared multi-scale feature extraction network. Given a pair of images and for arbitrary query coordinates, all the correspondences are predicted within a single feed-forward pass. We further propose an adaptive query-clustering strategy and an uncertainty-based outlier detection module to cooperate with the proposed framework for faster and better predictions. Experiments on various sparse and dense matching tasks demonstrate the superiority of our method in both efficiency and effectiveness against existing state-of-the-arts.
Attention Mechanisms in Computer Vision: A Survey
Nov 15, 2021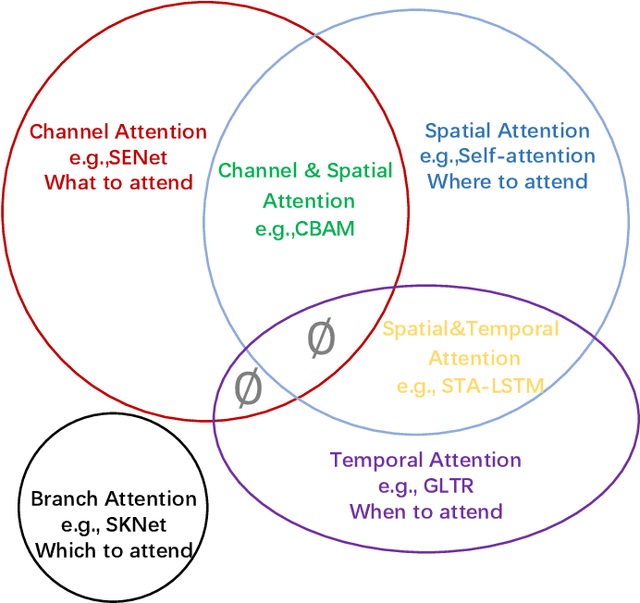

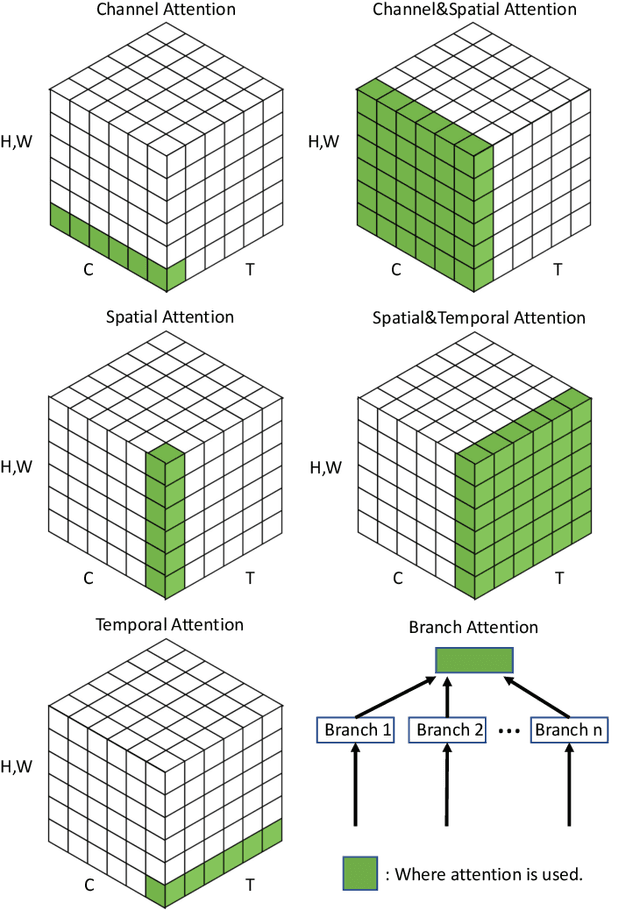
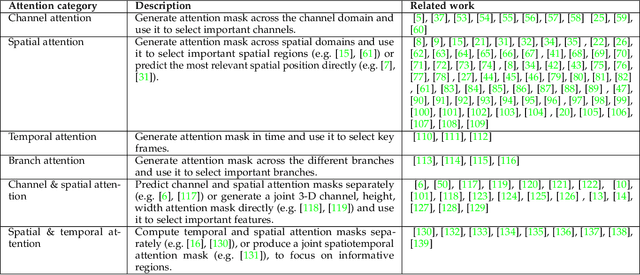
Humans can naturally and effectively find salient regions in complex scenes. Motivated by this observation, attention mechanisms were introduced into computer vision with the aim of imitating this aspect of the human visual system. Such an attention mechanism can be regarded as a dynamic weight adjustment process based on features of the input image. Attention mechanisms have achieved great success in many visual tasks, including image classification, object detection, semantic segmentation, video understanding, image generation, 3D vision, multi-modal tasks and self-supervised learning. In this survey, we provide a comprehensive review of various attention mechanisms in computer vision and categorize them according to approach, such as channel attention, spatial attention, temporal attention and branch attention; a related repository https://github.com/MenghaoGuo/Awesome-Vision-Attentions is dedicated to collecting related work. We also suggest future directions for attention mechanism research.
Centralized Information Interaction for Salient Object Detection
Dec 24, 2020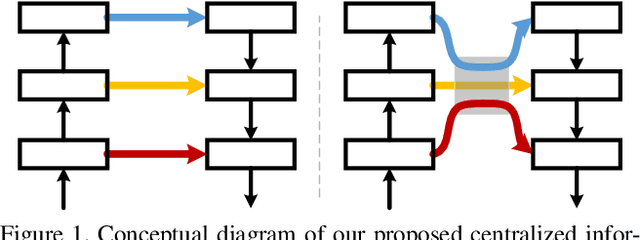
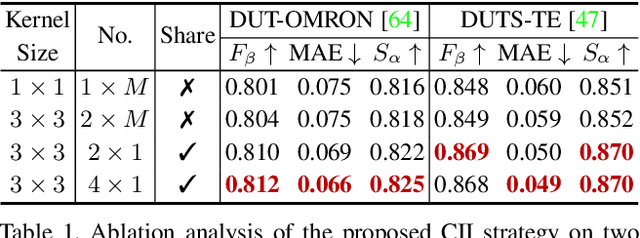

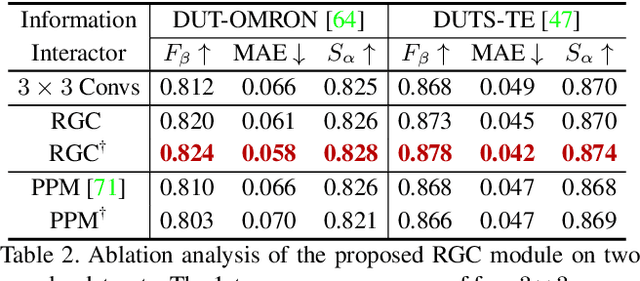
The U-shape structure has shown its advantage in salient object detection for efficiently combining multi-scale features. However, most existing U-shape based methods focused on improving the bottom-up and top-down pathways while ignoring the connections between them. This paper shows that by centralizing these connections, we can achieve the cross-scale information interaction among them, hence obtaining semantically stronger and positionally more precise features. To inspire the potential of the newly proposed strategy, we further design a relative global calibration module that can simultaneously process multi-scale inputs without spatial interpolation. Benefiting from the above strategy and module, our proposed approach can aggregate features more effectively while introducing only a few additional parameters. Our approach can cooperate with various existing U-shape-based salient object detection methods by substituting the connections between the bottom-up and top-down pathways. Experimental results demonstrate that our proposed approach performs favorably against the previous state-of-the-arts on five widely used benchmarks with less computational complexity. The source code will be publicly available.
Dynamic Feature Integration for Simultaneous Detection of Salient Object, Edge and Skeleton
Apr 18, 2020
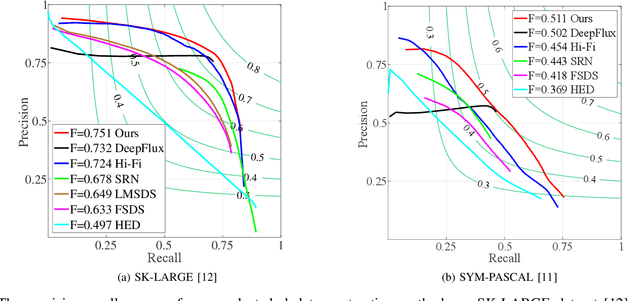

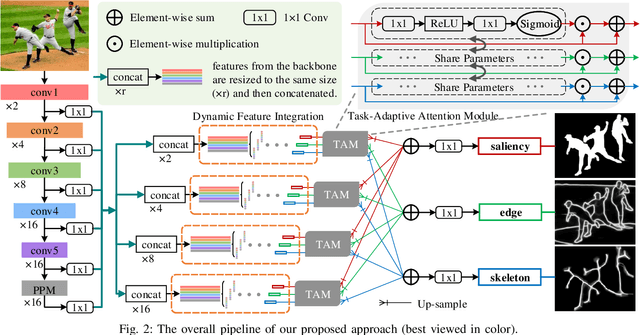
In this paper, we solve three low-level pixel-wise vision problems, including salient object segmentation, edge detection, and skeleton extraction, within a unified framework. We first show some similarities shared by these tasks and then demonstrate how they can be leveraged for developing a unified framework that can be trained end-to-end. In particular, we introduce a selective integration module that allows each task to dynamically choose features at different levels from the shared backbone based on its own characteristics. Furthermore, we design a task-adaptive attention module, aiming at intelligently allocating information for different tasks according to the image content priors. To evaluate the performance of our proposed network on these tasks, we conduct exhaustive experiments on multiple representative datasets. We will show that though these tasks are naturally quite different, our network can work well on all of them and even perform better than current single-purpose state-of-the-art methods. In addition, we also conduct adequate ablation analyses that provide a full understanding of the design principles of the proposed framework. To facilitate future research, source code will be released.