 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Feature Integration for Simultaneous Detection of Salient Object, Edge and Skeleton
Paper and Code
Apr 18, 2020
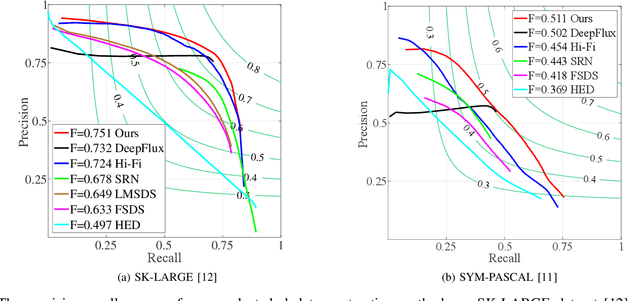

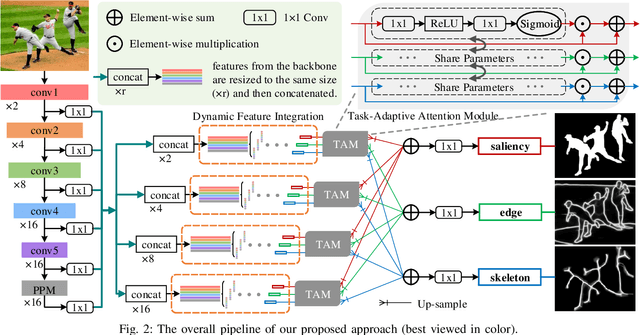
In this paper, we solve three low-level pixel-wise vision problems, including salient object segmentation, edge detection, and skeleton extraction, within a unified framework. We first show some similarities shared by these tasks and then demonstrate how they can be leveraged for developing a unified framework that can be trained end-to-end. In particular, we introduce a selective integration module that allows each task to dynamically choose features at different levels from the shared backbone based on its own characteristics. Furthermore, we design a task-adaptive attention module, aiming at intelligently allocating information for different tasks according to the image content priors. To evaluate the performance of our proposed network on these tasks, we conduct exhaustive experiments on multiple representative datasets. We will show that though these tasks are naturally quite different, our network can work well on all of them and even perform better than current single-purpose state-of-the-art methods. In addition, we also conduct adequate ablation analyses that provide a full understanding of the design principles of the proposed framework. To facilitate future research, source code will be released.