 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Knowledge Selection and Restoration for Non-Exemplar Class Incremental Learning
Dec 20, 2023Non-exemplar class incremental learning aims to learn both the new and old tasks without accessing any training data from the past. This strict restriction enlarges the difficulty of alleviating catastrophic forgetting since all techniques can only be applied to current task data. Considering this challenge, we propose a novel framework of fine-grained knowledge selection and restoration. The conventional knowledge distillation-based methods place too strict constraints on the network parameters and features to prevent forgetting, which limits the training of new tasks. To loose this constraint, we proposed a novel fine-grained selective patch-level distillation to adaptively balance plasticity and stability. Some task-agnostic patches can be used to preserve the decision boundary of the old task. While some patches containing the important foreground are favorable for learning the new task. Moreover, we employ a task-agnostic mechanism to generate more realistic prototypes of old tasks with the current task sample for reducing classifier bias for fine-grained knowledge restoration. Extensive experiments on CIFAR100, TinyImageNet and ImageNet-Subset demonstrate the effectiveness of our method. Code is available at https://github.com/scok30/vit-cil.
Masked Autoencoders are Efficient Class Incremental Learners
Aug 24, 2023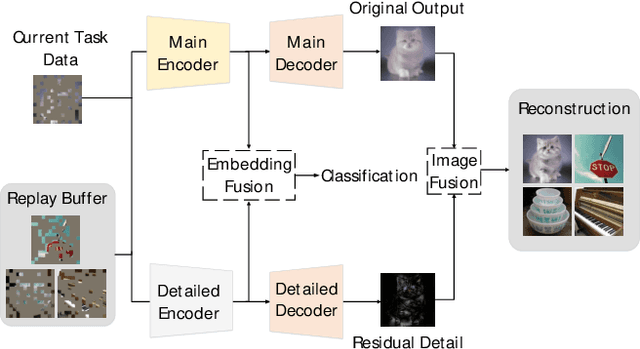
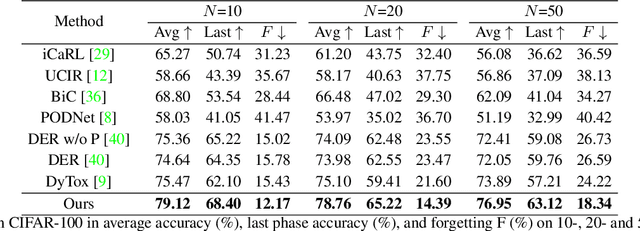
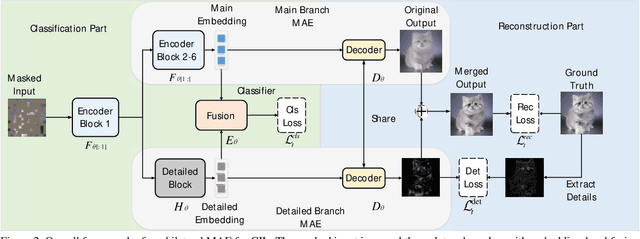
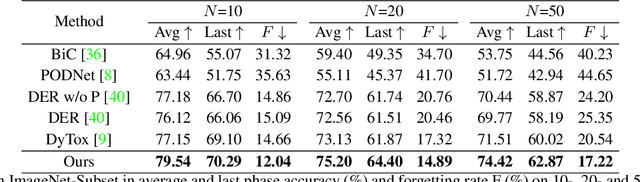
Class Incremental Learning (CIL) aims to sequentially learn new classes while avoiding catastrophic forgetting of previous knowledge. We propose to use Masked Autoencoders (MAEs) as efficient learners for CIL. MAEs were originally designed to learn useful representations through reconstructive unsupervised learning, and they can be easily integrated with a supervised loss for classification. Moreover, MAEs can reliably reconstruct original input images from randomly selected patches, which we use to store exemplars from past tasks more efficiently for CIL. We also propose a bilateral MAE framework to learn from image-level and embedding-level fusion, which produces better-quality reconstructed images and more stable representations. Our experiments confirm that our approach performs better than the state-of-the-art on CIFAR-100, ImageNet-Subset, and ImageNet-Full. The code is available at https://github.com/scok30/MAE-CIL .
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
May 17, 2023



Modern autonomous driving systems are typically divided into three main tasks: perception, prediction, and planning. The planning task involves predicting the trajectory of the ego vehicle based on inputs from both internal intention and the external environment, and manipulating the vehicle accordingly. Most existing works evaluate their performance on the nuScenes dataset using the L2 error and collision rate between the predicted trajectories and the ground truth. In this paper, we reevaluate these existing evaluation metrics and explore whether they accurately measure the superiority of different methods. Specifically, we design an MLP-based method that takes raw sensor data (e.g., past trajectory, velocity, etc.) as input and directly outputs the future trajectory of the ego vehicle, without using any perception or prediction information such as camera images or LiDAR. Surprisingly, such a simple method achieves state-of-the-art end-to-end planning performance on the nuScenes dataset, reducing the average L2 error by about 30%. We further conduct in-depth analysis and provide new insights into the factors that are critical for the success of the planning task on nuScenes dataset. Our observation also indicates that we need to rethink the current open-loop evaluation scheme of end-to-end autonomous driving in nuScenes. Codes are available at https://github.com/E2E-AD/AD-MLP.
Robust Saliency Guidance for Data-free Class Incremental Learning
Dec 16, 2022



Data-Free Class Incremental Learning (DFCIL) aims to sequentially learn tasks with access only to data from the current one. DFCIL is of interest because it mitigates concerns about privacy and long-term storage of data, while at the same time alleviating the problem of catastrophic forgetting in incremental learning. In this work, we introduce robust saliency guidance for DFCIL and propose a new framework, which we call RObust Saliency Supervision (ROSS), for mitigating the negative effect of saliency drift. Firstly, we use a teacher-student architecture leveraging low-level tasks to supervise the model with global saliency. We also apply boundary-guided saliency to protect it from drifting across object boundaries at intermediate layers. Finally, we introduce a module for injecting and recovering saliency noise to increase robustness of saliency preservation. Our experiments demonstrate that our method can retain better saliency maps across tasks and achieve state-of-the-art results on the CIFAR-100, Tiny-ImageNet and ImageNet-Subset DFCIL benchmarks. Code will be made publicly available.
SLAN: Self-Locator Aided Network for Cross-Modal Understanding
Dec 08, 2022



Learning fine-grained interplay between vision and language allows to a more accurate understanding for VisionLanguage tasks. However, it remains challenging to extract key image regions according to the texts for semantic alignments. Most existing works are either limited by textagnostic and redundant regions obtained with the frozen detectors, or failing to scale further due to its heavy reliance on scarce grounding (gold) data to pre-train detectors. To solve these problems, we propose Self-Locator Aided Network (SLAN) for cross-modal understanding tasks without any extra gold data. SLAN consists of a region filter and a region adaptor to localize regions of interest conditioned on different texts. By aggregating cross-modal information, the region filter selects key regions and the region adaptor updates their coordinates with text guidance. With detailed region-word alignments, SLAN can be easily generalized to many downstream tasks. It achieves fairly competitive results on five cross-modal understanding tasks (e.g., 85.7% and 69.2% on COCO image-to-text and text-to-image retrieval, surpassing previous SOTA methods). SLAN also demonstrates strong zero-shot and fine-tuned transferability to two localization tasks.