 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALIVE: Animate Your World with Lifelike Audio-Video Generation
Feb 09, 2026Video generation is rapidly evolving towards unified audio-video generation. In this paper, we present ALIVE, a generation model that adapts a pretrained Text-to-Video (T2V) model to Sora-style audio-video generation and animation. In particular, the model unlocks the Text-to-Video&Audio (T2VA) and Reference-to-Video&Audio (animation) capabilities compared to the T2V foundation models. To support the audio-visual synchronization and reference animation, we augment the popular MMDiT architecture with a joint audio-video branch which includes TA-CrossAttn for temporally-aligned cross-modal fusion and UniTemp-RoPE for precise audio-visual alignment. Meanwhile, a comprehensive data pipeline consisting of audio-video captioning, quality control, etc., is carefully designed to collect high-quality finetuning data. Additionally, we introduce a new benchmark to perform a comprehensive model test and comparison. After continue pretraining and finetuning on million-level high-quality data, ALIVE demonstrates outstanding performance, consistently outperforming open-source models and matching or surpassing state-of-the-art commercial solutions. With detailed recipes and benchmarks, we hope ALIVE helps the community develop audio-video generation models more efficiently. Official page: https://github.com/FoundationVision/Alive.
Med-DANet V2: A Flexible Dynamic Architecture for Efficient Medical Volumetric Segmentation
Oct 28, 2023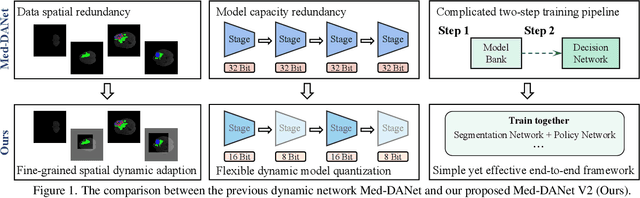
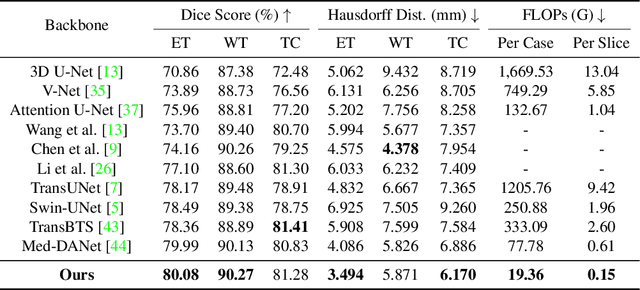
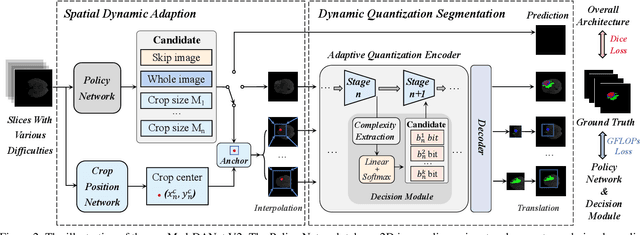
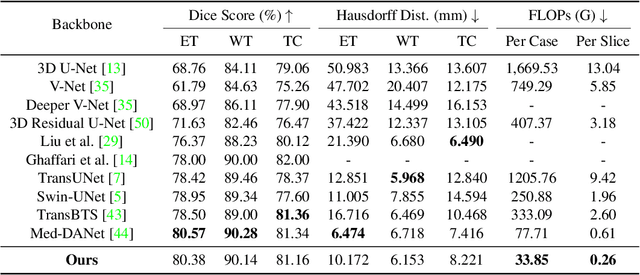
Recent works have shown that the computational efficiency of 3D medical image (e.g. CT and MRI) segmentation can be impressively improved by dynamic inference based on slice-wise complexity. As a pioneering work, a dynamic architecture network for medical volumetric segmentation (i.e. Med-DANet) has achieved a favorable accuracy and efficiency trade-off by dynamically selecting a suitable 2D candidate model from the pre-defined model bank for different slices. However, the issues of incomplete data analysis, high training costs, and the two-stage pipeline in Med-DANet require further improvement. To this end, this paper further explores a unified formulation of the dynamic inference framework from the perspective of both the data itself and the model structure. For each slice of the input volume, our proposed method dynamically selects an important foreground region for segmentation based on the policy generated by our Decision Network and Crop Position Network. Besides, we propose to insert a stage-wise quantization selector to the employed segmentation model (e.g. U-Net) for dynamic architecture adapting. Extensive experiments on BraTS 2019 and 2020 show that our method achieves comparable or better performance than previous state-of-the-art methods with much less model complexity. Compared with previous methods Med-DANet and TransBTS with dynamic and static architecture respectively, our framework improves the model efficiency by up to nearly 4.1 and 17.3 times with comparable segmentation results on BraTS 2019.
DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model
Oct 11, 2023With the increasing popularity of autonomous driving based on the powerful and unified bird's-eye-view (BEV) representation, a demand for high-quality and large-scale multi-view video data with accurate annotation is urgently required. However, such large-scale multi-view data is hard to obtain due to expensive collection and annotation costs. To alleviate the problem, we propose a spatial-temporal consistent diffusion framework DrivingDiffusion, to generate realistic multi-view videos controlled by 3D layout. There are three challenges when synthesizing multi-view videos given a 3D layout: How to keep 1) cross-view consistency and 2) cross-frame consistency? 3) How to guarantee the quality of the generated instances? Our DrivingDiffusion solves the problem by cascading the multi-view single-frame image generation step, the single-view video generation step shared by multiple cameras, and post-processing that can handle long video generation. In the multi-view model, the consistency of multi-view images is ensured by information exchange between adjacent cameras. In the temporal model, we mainly query the information that needs attention in subsequent frame generation from the multi-view images of the first frame. We also introduce the local prompt to effectively improve the quality of generated instances. In post-processing, we further enhance the cross-view consistency of subsequent frames and extend the video length by employing temporal sliding window algorithm. Without any extra cost, our model can generate large-scale realistic multi-camera driving videos in complex urban scenes, fueling the downstream driving tasks. The code will be made publicly available.
3D-U-SAM Network For Few-shot Tooth Segmentation in CBCT Images
Sep 20, 2023Accurate representation of tooth position is extremely important in treatment. 3D dental image segmentation is a widely used method, however labelled 3D dental datasets are a scarce resource, leading to the problem of small samples that this task faces in many cases. To this end, we address this problem with a pretrained SAM and propose a novel 3D-U-SAM network for 3D dental image segmentation. Specifically, in order to solve the problem of using 2D pre-trained weights on 3D datasets, we adopted a convolution approximation method; in order to retain more details, we designed skip connections to fuse features at all levels with reference to U-Net. The effectiveness of the proposed method is demonstrated in ablation experiments, comparison experiments, and sample size experiments.
CityTrack: Improving City-Scale Multi-Camera Multi-Target Tracking by Location-Aware Tracking and Box-Grained Matching
Jul 06, 2023



Multi-Camera Multi-Target Tracking (MCMT) is a computer vision technique that involves tracking multiple targets simultaneously across multiple cameras. MCMT in urban traffic visual analysis faces great challenges due to the complex and dynamic nature of urban traffic scenes, where multiple cameras with different views and perspectives are often used to cover a large city-scale area. Targets in urban traffic scenes often undergo occlusion, illumination changes, and perspective changes, making it difficult to associate targets across different cameras accurately. To overcome these challenges, we propose a novel systematic MCMT framework, called CityTrack. Specifically, we present a Location-Aware SCMT tracker which integrates various advanced techniques to improve its effectiveness in the MCMT task and propose a novel Box-Grained Matching (BGM) method for the ICA module to solve the aforementioned problems. We evaluated our approach on the public test set of the CityFlowV2 dataset and achieved an IDF1 of 84.91%, ranking 1st in the 2022 AI CITY CHALLENGE. Our experimental results demonstrate the effectiveness of our approach in overcoming the challenges posed by urban traffic scenes.
Multi-source adversarial transfer learning based on similar source domains with local features
May 30, 2023Transfer learning leverages knowledge from other domains and has been successful in many applications. Transfer learning methods rely on the overall similarity of the source and target domains. However, in some cases, it is impossible to provide an overall similar source domain, and only some source domains with similar local features can be provided. Can transfer learning be achieved? In this regard, we propose a multi-source adversarial transfer learning method based on local feature similarity to the source domain to handle transfer scenarios where the source and target domains have only local similarities. This method extracts transferable local features between a single source domain and the target domain through a sub-network. Specifically, the feature extractor of the sub-network is induced by the domain discriminator to learn transferable knowledge between the source domain and the target domain. The extracted features are then weighted by an attention module to suppress non-transferable local features while enhancing transferable local features. In order to ensure that the data from the target domain in different sub-networks in the same batch is exactly the same, we designed a multi-source domain independent strategy to provide the possibility for later local feature fusion to complete the key features required. In order to verify the effectiveness of the method, we made the dataset "Local Carvana Image Masking Dataset". Applying the proposed method to the image segmentation task of the proposed dataset achieves better transfer performance than other multi-source transfer learning methods. It is shown that the designed transfer learning method is feasible for transfer scenarios where the source and target domains have only local similarities.
Multi-source adversarial transfer learning for ultrasound image segmentation with limited similarity
May 30, 2023Lesion segmentation of ultrasound medical images based on deep learning techniques is a widely used method for diagnosing diseases. Although there is a large amount of ultrasound image data in medical centers and other places, labeled ultrasound datasets are a scarce resource, and it is likely that no datasets are available for new tissues/organs. Transfer learning provides the possibility to solve this problem, but there are too many features in natural images that are not related to the target domain. As a source domain, redundant features that are not conducive to the task will be extracted. Migration between ultrasound images can avoid this problem, but there are few types of public datasets, and it is difficult to find sufficiently similar source domains. Compared with natural images, ultrasound images have less information, and there are fewer transferable features between different ultrasound images, which may cause negative transfer. To this end, a multi-source adversarial transfer learning network for ultrasound image segmentation is proposed. Specifically, to address the lack of annotations, the idea of adversarial transfer learning is used to adaptively extract common features between a certain pair of source and target domains, which provides the possibility to utilize unlabeled ultrasound data. To alleviate the lack of knowledge in a single source domain, multi-source transfer learning is adopted to fuse knowledge from multiple source domains. In order to ensure the effectiveness of the fusion and maximize the use of precious data, a multi-source domain independent strategy is also proposed to improve the estimation of the target domain data distribution, which further increases the learning ability of the multi-source adversarial migration learning network in multiple domains.
Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes
May 17, 2023



Modern autonomous driving systems are typically divided into three main tasks: perception, prediction, and planning. The planning task involves predicting the trajectory of the ego vehicle based on inputs from both internal intention and the external environment, and manipulating the vehicle accordingly. Most existing works evaluate their performance on the nuScenes dataset using the L2 error and collision rate between the predicted trajectories and the ground truth. In this paper, we reevaluate these existing evaluation metrics and explore whether they accurately measure the superiority of different methods. Specifically, we design an MLP-based method that takes raw sensor data (e.g., past trajectory, velocity, etc.) as input and directly outputs the future trajectory of the ego vehicle, without using any perception or prediction information such as camera images or LiDAR. Surprisingly, such a simple method achieves state-of-the-art end-to-end planning performance on the nuScenes dataset, reducing the average L2 error by about 30%. We further conduct in-depth analysis and provide new insights into the factors that are critical for the success of the planning task on nuScenes dataset. Our observation also indicates that we need to rethink the current open-loop evaluation scheme of end-to-end autonomous driving in nuScenes. Codes are available at https://github.com/E2E-AD/AD-MLP.
ByteTrackV2: 2D and 3D Multi-Object Tracking by Associating Every Detection Box
Mar 27, 2023Multi-object tracking (MOT) aims at estimating bounding boxes and identities of objects across video frames. Detection boxes serve as the basis of both 2D and 3D MOT. The inevitable changing of detection scores leads to object missing after tracking. We propose a hierarchical data association strategy to mine the true objects in low-score detection boxes, which alleviates the problems of object missing and fragmented trajectories. The simple and generic data association strategy shows effectiveness under both 2D and 3D settings. In 3D scenarios, it is much easier for the tracker to predict object velocities in the world coordinate. We propose a complementary motion prediction strategy that incorporates the detected velocities with a Kalman filter to address the problem of abrupt motion and short-term disappearing. ByteTrackV2 leads the nuScenes 3D MOT leaderboard in both camera (56.4% AMOTA) and LiDAR (70.1% AMOTA) modalities. Furthermore, it is nonparametric and can be integrated with various detectors, making it appealing in real applications. The source code is released at https://github.com/ifzhang/ByteTrack-V2.
Robust Multi-Object Tracking by Marginal Inference
Aug 07, 2022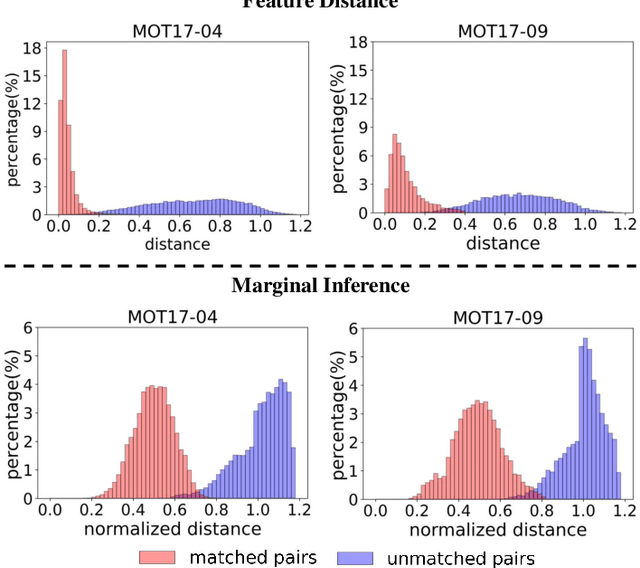
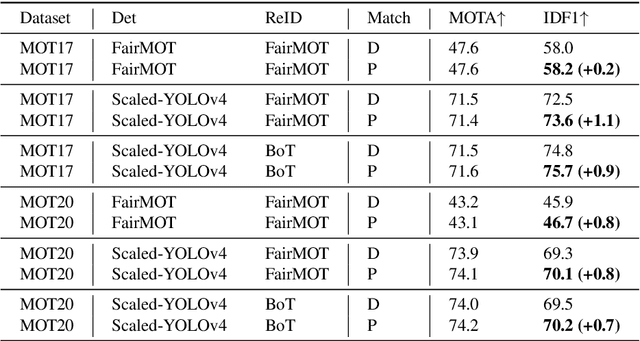
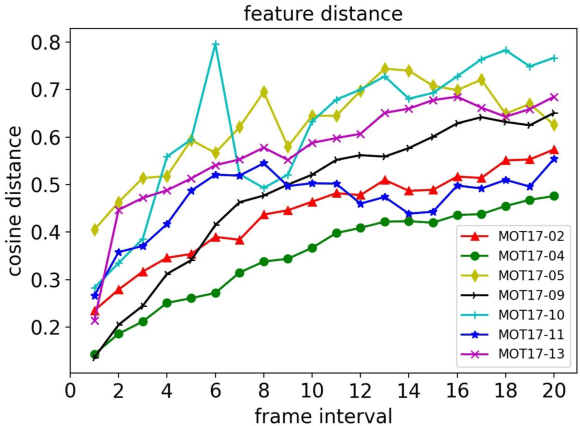

Multi-object tracking in videos requires to solve a fundamental problem of one-to-one assignment between objects in adjacent frames. Most methods address the problem by first discarding impossible pairs whose feature distances are larger than a threshold, followed by linking objects using Hungarian algorithm to minimize the overall distance. However, we find that the distribution of the distances computed from Re-ID features may vary significantly for different videos. So there isn't a single optimal threshold which allows us to safely discard impossible pairs. To address the problem, we present an efficient approach to compute a marginal probability for each pair of objects in real time. The marginal probability can be regarded as a normalized distance which is significantly more stable than the original feature distance. As a result, we can use a single threshold for all videos. The approach is general and can be applied to the existing trackers to obtain about one point improvement in terms of IDF1 metric. It achieves competitive results on MOT17 and MOT20 benchmarks. In addition, the computed probability is more interpretable which facilitates subsequent post-processing operations.