 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision KAN: Towards an Attention-Free Backbone for Vision with Kolmogorov-Arnold Networks
Jan 29, 2026Attention mechanisms have become a key module in modern vision backbones due to their ability to model long-range dependencies. However, their quadratic complexity in sequence length and the difficulty of interpreting attention weights limit both scalability and clarity. Recent attention-free architectures demonstrate that strong performance can be achieved without pairwise attention, motivating the search for alternatives. In this work, we introduce Vision KAN (ViK), an attention-free backbone inspired by the Kolmogorov-Arnold Networks. At its core lies MultiPatch-RBFKAN, a unified token mixer that combines (a) patch-wise nonlinear transform with Radial Basis Function-based KANs, (b) axis-wise separable mixing for efficient local propagation, and (c) low-rank global mapping for long-range interaction. Employing as a drop-in replacement for attention modules, this formulation tackles the prohibitive cost of full KANs on high-resolution features by adopting a patch-wise grouping strategy with lightweight operators to restore cross-patch dependencies. Experiments on ImageNet-1K show that ViK achieves competitive accuracy with linear complexity, demonstrating the potential of KAN-based token mixing as an efficient and theoretically grounded alternative to attention.
MedKAN: An Advanced Kolmogorov-Arnold Network for Medical Image Classification
Feb 25, 2025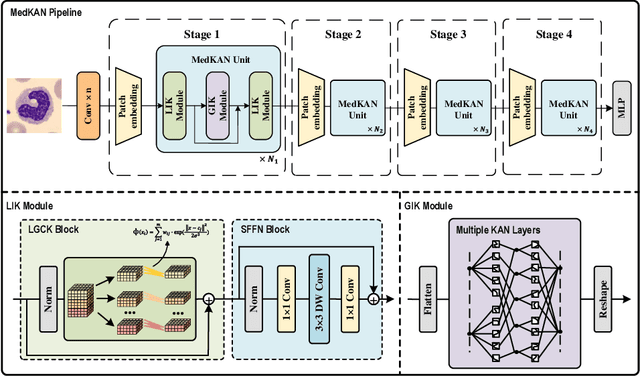
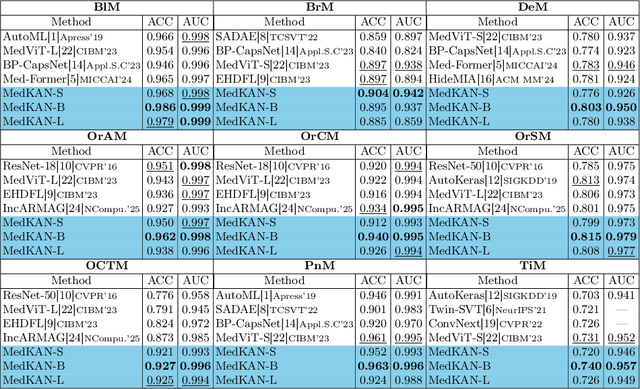
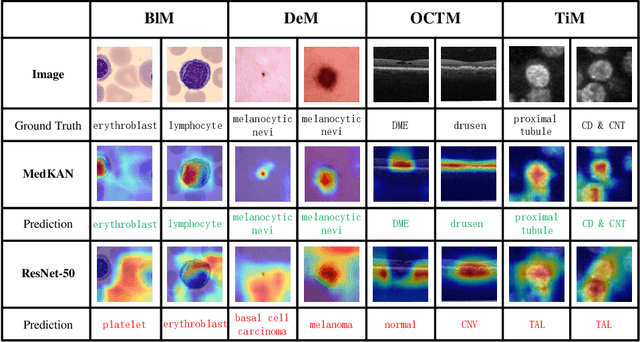
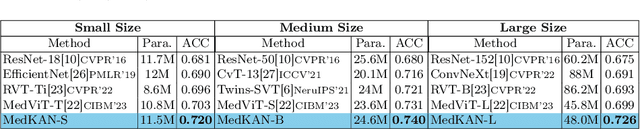
Recent advancements in deep learning for image classification predominantly rely on convolutional neural networks (CNNs) or Transformer-based architectures. However, these models face notable challenges in medical imaging, particularly in capturing intricate texture details and contextual features. Kolmogorov-Arnold Networks (KANs) represent a novel class of architectures that enhance nonlinear transformation modeling, offering improved representation of complex features. In this work, we present MedKAN, a medical image classification framework built upon KAN and its convolutional extensions. MedKAN features two core modules: the Local Information KAN (LIK) module for fine-grained feature extraction and the Global Information KAN (GIK) module for global context integration. By combining these modules, MedKAN achieves robust feature modeling and fusion. To address diverse computational needs, we introduce three scalable variants--MedKAN-S, MedKAN-B, and MedKAN-L. Experimental results on nine public medical imaging datasets demonstrate that MedKAN achieves superior performance compared to CNN- and Transformer-based models, highlighting its effectiveness and generalizability in medical image analysis.
Natias: Neuron Attribution based Transferable Image Adversarial Steganography
Sep 08, 2024



Image steganography is a technique to conceal secret messages within digital images. Steganalysis, on the contrary, aims to detect the presence of secret messages within images. Recently, deep-learning-based steganalysis methods have achieved excellent detection performance. As a countermeasure, adversarial steganography has garnered considerable attention due to its ability to effectively deceive deep-learning-based steganalysis. However, steganalysts often employ unknown steganalytic models for detection. Therefore, the ability of adversarial steganography to deceive non-target steganalytic models, known as transferability, becomes especially important. Nevertheless, existing adversarial steganographic methods do not consider how to enhance transferability. To address this issue, we propose a novel adversarial steganographic scheme named Natias. Specifically, we first attribute the output of a steganalytic model to each neuron in the target middle layer to identify critical features. Next, we corrupt these critical features that may be adopted by diverse steganalytic models. Consequently, it can promote the transferability of adversarial steganography. Our proposed method can be seamlessly integrated with existing adversarial steganography frameworks. Thorough experimental analyses affirm that our proposed technique possesses improved transferability when contrasted with former approaches, and it attains heightened security in retraining scenarios.
Activation Space Selectable Kolmogorov-Arnold Networks
Aug 15, 2024



The multilayer perceptron (MLP), a fundamental paradigm in current artificial intelligence, is widely applied in fields such as computer vision and natural language processing. However, the recently proposed Kolmogorov-Arnold Network (KAN), based on nonlinear additive connections, has been proven to achieve performance comparable to MLPs with significantly fewer parameters. Despite this potential, the use of a single activation function space results in reduced performance of KAN and related works across different tasks. To address this issue, we propose an activation space Selectable KAN (S-KAN). S-KAN employs an adaptive strategy to choose the possible activation mode for data at each feedforward KAN node. Our approach outperforms baseline methods in seven representative function fitting tasks and significantly surpasses MLP methods with the same level of parameters. Furthermore, we extend the structure of S-KAN and propose an activation space selectable Convolutional KAN (S-ConvKAN), which achieves leading results on four general image classification datasets. Our method mitigates the performance variability of the original KAN across different tasks and demonstrates through extensive experiments that feedforward KANs with selectable activations can achieve or even exceed the performance of MLP-based methods. This work contributes to the understanding of the data-centric design of new AI paradigms and provides a foundational reference for innovations in KAN-based network architectures.
Evaluation of Infrastructure-based Warning System on Driving Behaviors-A Roundabout Study
Dec 06, 2023Smart intersections have the potential to improve road safety with sensing, communication, and edge computing technologies. Perception sensors installed at a smart intersection can monitor the traffic environment in real time and send infrastructure-based warnings to nearby travelers through V2X communication. This paper investigated how infrastructure-based warnings can influence driving behaviors and improve roundabout safety through a driving-simulator study - a challenging driving scenario for human drivers. A co-simulation platform integrating Simulation of Urban Mobility (SUMO) and Webots was developed to serve as the driving simulator. A real-world roundabout in Ann Arbor, Michigan was built in the co-simulation platform as the study area, and the merging scenarios were investigated. 36 participants were recruited and asked to navigate the roundabout under three danger levels (e.g., low, medium, high) and three collision warning designs (e.g., no warning, warning issued 1 second in advance, warning issued 2 seconds in advance). Results indicated that advanced warnings can significantly enhance safety by minimizing potential risks compared to scenarios without warnings. Earlier warnings enabled smoother driver responses and reduced abrupt decelerations. In addition, a personalized intention prediction model was developed to predict drivers' stop-or-go decisions when the warning is displayed. Among all tested machine learning models, the XGBoost model achieved the highest prediction accuracy with a precision rate of 95.56% and a recall rate of 97.73%.
From Pretext to Purpose: Batch-Adaptive Self-Supervised Learning
Nov 16, 2023In recent years, self-supervised contrastive learning has emerged as a distinguished paradigm in the artificial intelligence landscape. It facilitates unsupervised feature learning through contrastive delineations at the instance level. However, crafting an effective self-supervised paradigm remains a pivotal challenge within this field. This paper delves into two crucial factors impacting self-supervised contrastive learning-bach size and pretext tasks, and from a data processing standpoint, proposes an adaptive technique of batch fusion. The proposed method, via dimensionality reduction and reconstruction of batch data, enables formerly isolated individual data to partake in intra-batch communication through the Embedding Layer. Moreover, it adaptively amplifies the self-supervised feature encoding capability as the training progresses. We conducted a linear classification test of this method based on the classic contrastive learning framework on ImageNet-1k. The empirical findings illustrate that our approach achieves state-of-the-art performance under equitable comparisons. Benefiting from its "plug-and-play" characteristics, we further explored other contrastive learning methods. On the ImageNet-100, compared to the original performance, the top1 has seen a maximum increase of 1.25%. We suggest that the proposed method may contribute to the advancement of data-driven self-supervised learning research, bringing a fresh perspective to this community.
Multi-source adversarial transfer learning based on similar source domains with local features
May 30, 2023Transfer learning leverages knowledge from other domains and has been successful in many applications. Transfer learning methods rely on the overall similarity of the source and target domains. However, in some cases, it is impossible to provide an overall similar source domain, and only some source domains with similar local features can be provided. Can transfer learning be achieved? In this regard, we propose a multi-source adversarial transfer learning method based on local feature similarity to the source domain to handle transfer scenarios where the source and target domains have only local similarities. This method extracts transferable local features between a single source domain and the target domain through a sub-network. Specifically, the feature extractor of the sub-network is induced by the domain discriminator to learn transferable knowledge between the source domain and the target domain. The extracted features are then weighted by an attention module to suppress non-transferable local features while enhancing transferable local features. In order to ensure that the data from the target domain in different sub-networks in the same batch is exactly the same, we designed a multi-source domain independent strategy to provide the possibility for later local feature fusion to complete the key features required. In order to verify the effectiveness of the method, we made the dataset "Local Carvana Image Masking Dataset". Applying the proposed method to the image segmentation task of the proposed dataset achieves better transfer performance than other multi-source transfer learning methods. It is shown that the designed transfer learning method is feasible for transfer scenarios where the source and target domains have only local similarities.
Multi-source adversarial transfer learning for ultrasound image segmentation with limited similarity
May 30, 2023Lesion segmentation of ultrasound medical images based on deep learning techniques is a widely used method for diagnosing diseases. Although there is a large amount of ultrasound image data in medical centers and other places, labeled ultrasound datasets are a scarce resource, and it is likely that no datasets are available for new tissues/organs. Transfer learning provides the possibility to solve this problem, but there are too many features in natural images that are not related to the target domain. As a source domain, redundant features that are not conducive to the task will be extracted. Migration between ultrasound images can avoid this problem, but there are few types of public datasets, and it is difficult to find sufficiently similar source domains. Compared with natural images, ultrasound images have less information, and there are fewer transferable features between different ultrasound images, which may cause negative transfer. To this end, a multi-source adversarial transfer learning network for ultrasound image segmentation is proposed. Specifically, to address the lack of annotations, the idea of adversarial transfer learning is used to adaptively extract common features between a certain pair of source and target domains, which provides the possibility to utilize unlabeled ultrasound data. To alleviate the lack of knowledge in a single source domain, multi-source transfer learning is adopted to fuse knowledge from multiple source domains. In order to ensure the effectiveness of the fusion and maximize the use of precious data, a multi-source domain independent strategy is also proposed to improve the estimation of the target domain data distribution, which further increases the learning ability of the multi-source adversarial migration learning network in multiple domains.
The Spike Gating Flow: A Hierarchical Structure Based Spiking Neural Network for Online Gesture Recognition
Jun 07, 2022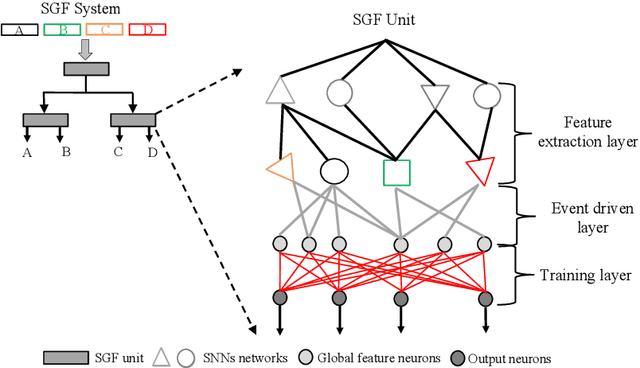
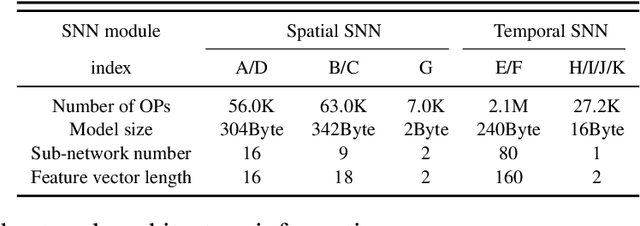
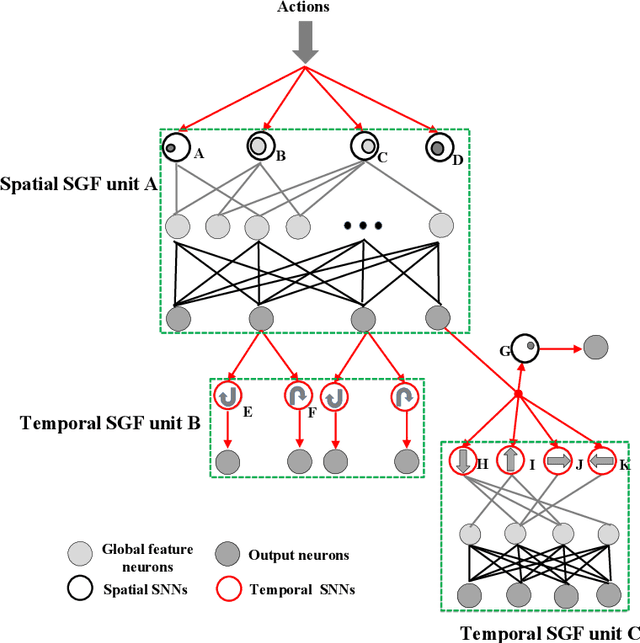
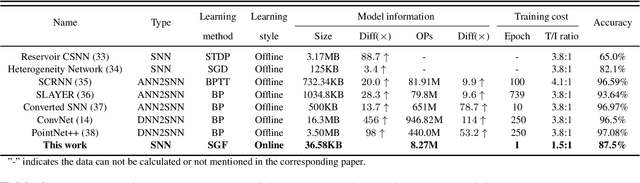
Action recognition is an exciting research avenue for artificial intelligence since it may be a game changer in the emerging industrial fields such as robotic visions and automobiles. However, current deep learning faces major challenges for such applications because of the huge computational cost and the inefficient learning. Hence, we develop a novel brain-inspired Spiking Neural Network (SNN) based system titled Spiking Gating Flow (SGF) for online action learning. The developed system consists of multiple SGF units which assembled in a hierarchical manner. A single SGF unit involves three layers: a feature extraction layer, an event-driven layer and a histogram-based training layer. To demonstrate the developed system capabilities, we employ a standard Dynamic Vision Sensor (DVS) gesture classification as a benchmark. The results indicate that we can achieve 87.5% accuracy which is comparable with Deep Learning (DL), but at smaller training/inference data number ratio 1.5:1. And only a single training epoch is required during the learning process. Meanwhile, to the best of our knowledge, this is the highest accuracy among the non-backpropagation algorithm based SNNs. At last, we conclude the few-shot learning paradigm of the developed network: 1) a hierarchical structure-based network design involves human prior knowledge; 2) SNNs for content based global dynamic feature detection.
MicroRec: Accelerating Deep Recommendation Systems to Microseconds by Hardware and Data Structure Solutions
Oct 12, 2020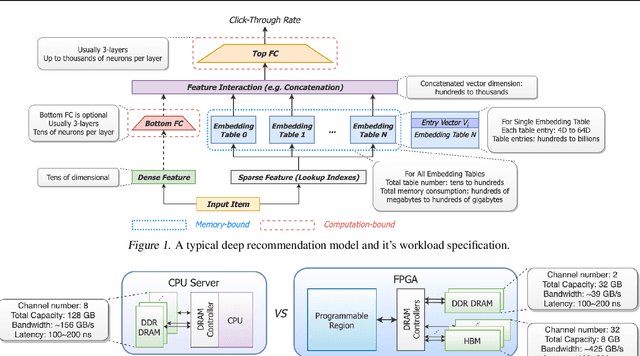
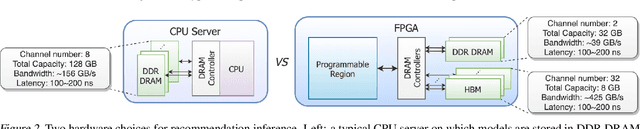
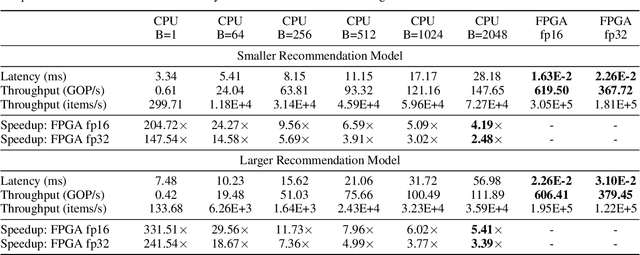
Deep neural networks are widely used in personalized recommendation systems. Unlike regular DNN inference workloads, recommendation inference is memory-bound due to the many random memory accesses needed to lookup the embedding tables. The inference is also heavily constrained in terms of latency because producing a recommendation for a user must be done in about tens of milliseconds. In this paper, we propose MicroRec, a high-performance inference engine for recommendation systems. MicroRec accelerates recommendation inference by (1) redesigning the data structures involved in the embeddings to reduce the number of lookups needed and (2) taking advantage of the availability of High-Bandwidth Memory (HBM) in FPGA accelerators to tackle the latency by enabling parallel lookups. We have implemented the resulting design on an FPGA board including the embedding lookup step as well as the complete inference process. Compared to the optimized CPU baseline (16 vCPU, AVX2-enabled), MicroRec achieves 13.8~14.7x speedup on embedding lookup alone and 2.5$~5.4x speedup for the entire recommendation inference in terms of throughput. As for latency, CPU-based engines needs milliseconds for inferring a recommendation while MicroRec only takes microseconds, a significant advantage in real-time recommendation systems.