 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFINN-GL: Generalized Mixed-Precision Extensions for FPGA-Accelerated LSTMs
Jun 25, 2025Recurrent neural networks (RNNs), particularly LSTMs, are effective for time-series tasks like sentiment analysis and short-term stock prediction. However, their computational complexity poses challenges for real-time deployment in resource constrained environments. While FPGAs offer a promising platform for energy-efficient AI acceleration, existing tools mainly target feed-forward networks, and LSTM acceleration typically requires full custom implementation. In this paper, we address this gap by leveraging the open-source and extensible FINN framework to enable the generalized deployment of LSTMs on FPGAs. Specifically, we leverage the Scan operator from the Open Neural Network Exchange (ONNX) specification to model the recurrent nature of LSTM computations, enabling support for mixed quantisation within them and functional verification of LSTM-based models. Furthermore, we introduce custom transformations within the FINN compiler to map the quantised ONNX computation graph to hardware blocks from the HLS kernel library of the FINN compiler and Vitis HLS. We validate the proposed tool-flow by training a quantised ConvLSTM model for a mid-price stock prediction task using the widely used dataset and generating a corresponding hardware IP of the model using our flow, targeting the XCZU7EV device. We show that the generated quantised ConvLSTM accelerator through our flow achieves a balance between performance (latency) and resource consumption, while matching (or bettering) inference accuracy of state-of-the-art models with reduced precision. We believe that the generalisable nature of the proposed flow will pave the way for resource-efficient RNN accelerator designs on FPGAs.
Post-Training Quantization with Low-precision Minifloats and Integers on FPGAs
Nov 21, 2023



Post-Training Quantization (PTQ) is a powerful technique for model compression, reducing the precision of neural networks without additional training overhead. Recent works have investigated adopting 8-bit floating-point quantization (FP8) in the context of PTQ for model inference. However, the exploration of floating-point formats smaller than 8 bits and their comparison with integer quantization remains relatively limited. In this work, we present minifloats, which are reduced-precision floating-point formats capable of further reducing the memory footprint, latency, and energy cost of a model while approaching full-precision model accuracy. Our work presents a novel PTQ design-space exploration, comparing minifloat and integer quantization schemes across a range of 3 to 8 bits for both weights and activations. We examine the applicability of various PTQ techniques to minifloats, including weight equalization, bias correction, SmoothQuant, gradient-based learned rounding, and the GPTQ method. Our experiments validate the effectiveness of low-precision minifloats when compared to their integer counterparts across a spectrum of accuracy-precision trade-offs on a set of reference deep learning vision workloads. Finally, we evaluate our results against an FPGA-based hardware cost model, showing that integer quantization often remains the Pareto-optimal option, given its relatively smaller hardware resource footprint.
MicroRec: Accelerating Deep Recommendation Systems to Microseconds by Hardware and Data Structure Solutions
Oct 12, 2020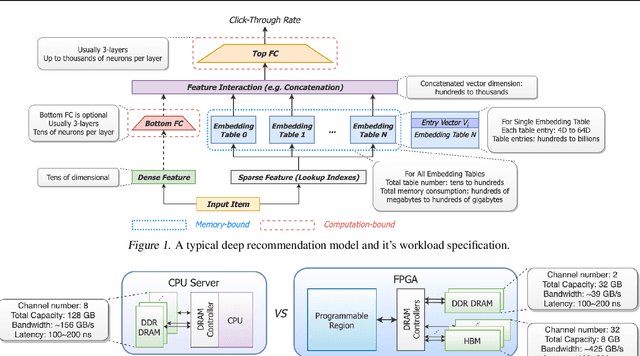
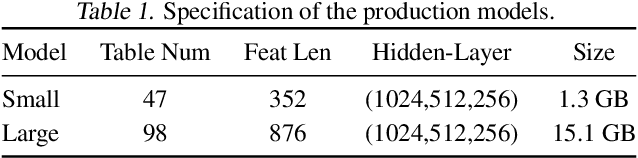
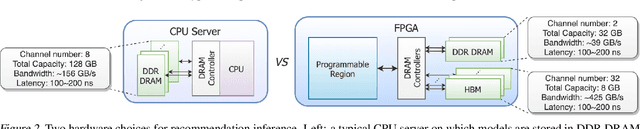
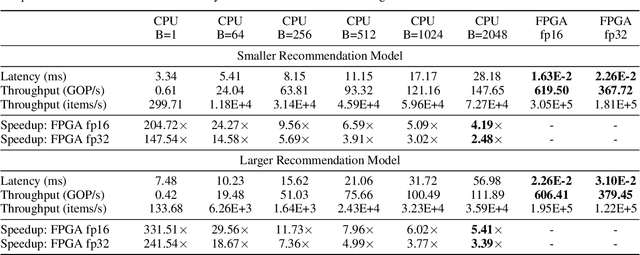
Deep neural networks are widely used in personalized recommendation systems. Unlike regular DNN inference workloads, recommendation inference is memory-bound due to the many random memory accesses needed to lookup the embedding tables. The inference is also heavily constrained in terms of latency because producing a recommendation for a user must be done in about tens of milliseconds. In this paper, we propose MicroRec, a high-performance inference engine for recommendation systems. MicroRec accelerates recommendation inference by (1) redesigning the data structures involved in the embeddings to reduce the number of lookups needed and (2) taking advantage of the availability of High-Bandwidth Memory (HBM) in FPGA accelerators to tackle the latency by enabling parallel lookups. We have implemented the resulting design on an FPGA board including the embedding lookup step as well as the complete inference process. Compared to the optimized CPU baseline (16 vCPU, AVX2-enabled), MicroRec achieves 13.8~14.7x speedup on embedding lookup alone and 2.5$~5.4x speedup for the entire recommendation inference in terms of throughput. As for latency, CPU-based engines needs milliseconds for inferring a recommendation while MicroRec only takes microseconds, a significant advantage in real-time recommendation systems.
Inference of Quantized Neural Networks on Heterogeneous All-Programmable Devices
Jun 21, 2018
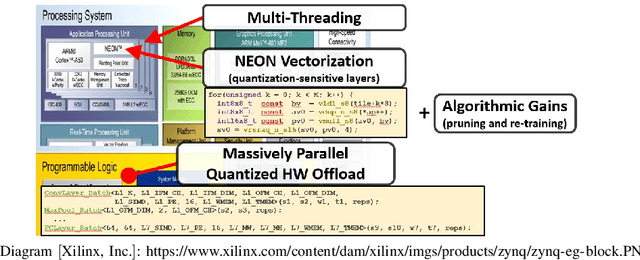

Neural networks have established as a generic and powerful means to approach challenging problems such as image classification, object detection or decision making. Their successful employment foots on an enormous demand of compute. The quantization of network parameters and the processed data has proven a valuable measure to reduce the challenges of network inference so effectively that the feasible scope of applications is expanded even into the embedded domain. This paper describes the making of a real-time object detection in a live video stream processed on an embedded all-programmable device. The presented case illustrates how the required processing is tamed and parallelized across both the CPU cores and the programmable logic and how the most suitable resources and powerful extensions, such as NEON vectorization, are leveraged for the individual processing steps. The crafted result is an extended Darknet framework implementing a fully integrated, end-to-end solution from video capture over object annotation to video output applying neural network inference at different quantization levels running at 16~frames per second on an embedded Zynq UltraScale+ (XCZU3EG) platform.