 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled Self-Evolution for Algorithmic Code Optimization
Jan 13, 2026Self-evolution methods enhance code generation through iterative "generate-verify-refine" cycles, yet existing approaches suffer from low exploration efficiency, failing to discover solutions with superior complexity within limited budgets. This inefficiency stems from initialization bias trapping evolution in poor solution regions, uncontrolled stochastic operations lacking feedback guidance, and insufficient experience utilization across tasks. To address these bottlenecks, we propose Controlled Self-Evolution (CSE), which consists of three key components. Diversified Planning Initialization generates structurally distinct algorithmic strategies for broad solution space coverage. Genetic Evolution replaces stochastic operations with feedback-guided mechanisms, enabling targeted mutation and compositional crossover. Hierarchical Evolution Memory captures both successful and failed experiences at inter-task and intra-task levels. Experiments on EffiBench-X demonstrate that CSE consistently outperforms all baselines across various LLM backbones. Furthermore, CSE achieves higher efficiency from early generations and maintains continuous improvement throughout evolution. Our code is publicly available at https://github.com/QuantaAlpha/EvoControl.
RAGO: Systematic Performance Optimization for Retrieval-Augmented Generation Serving
Mar 21, 2025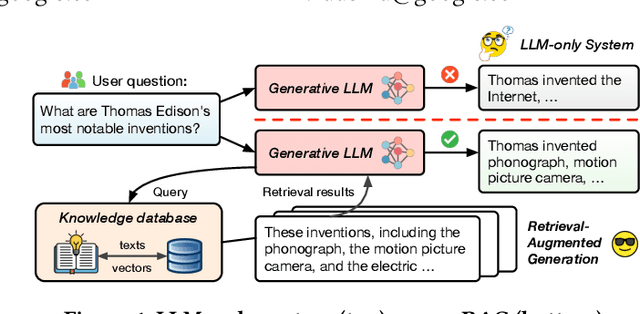



Retrieval-augmented generation (RAG), which combines large language models (LLMs) with retrievals from external knowledge databases, is emerging as a popular approach for reliable LLM serving. However, efficient RAG serving remains an open challenge due to the rapid emergence of many RAG variants and the substantial differences in workload characteristics across them. In this paper, we make three fundamental contributions to advancing RAG serving. First, we introduce RAGSchema, a structured abstraction that captures the wide range of RAG algorithms, serving as a foundation for performance optimization. Second, we analyze several representative RAG workloads with distinct RAGSchema, revealing significant performance variability across these workloads. Third, to address this variability and meet diverse performance requirements, we propose RAGO (Retrieval-Augmented Generation Optimizer), a system optimization framework for efficient RAG serving. Our evaluation shows that RAGO achieves up to a 2x increase in QPS per chip and a 55% reduction in time-to-first-token latency compared to RAG systems built on LLM-system extensions.
In-Network Preprocessing of Recommender Systems on Multi-Tenant SmartNICs
Jan 21, 2025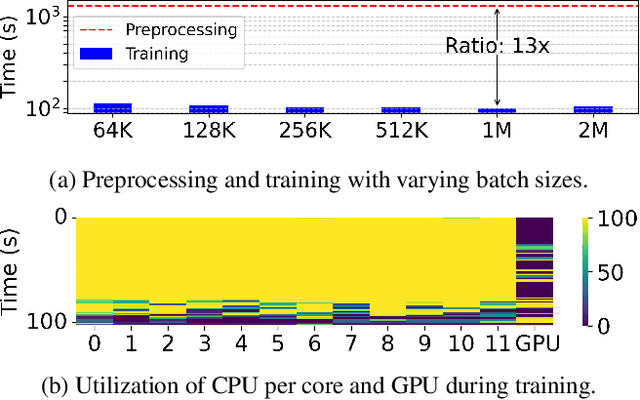

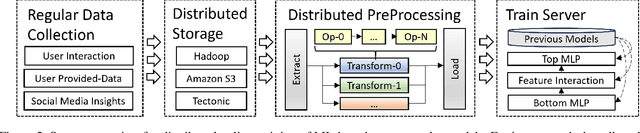

Keeping ML-based recommender models up-to-date as data drifts and evolves is essential to maintain accuracy. As a result, online data preprocessing plays an increasingly important role in serving recommender systems. Existing solutions employ multiple CPU workers to saturate the input bandwidth of a single training node. Such an approach results in high deployment costs and energy consumption. For instance, a recent report from industrial deployments shows that data storage and ingestion pipelines can account for over 60\% of the power consumption in a recommender system. In this paper, we tackle the issue from a hardware perspective by introducing Piper, a flexible and network-attached accelerator that executes data loading and preprocessing pipelines in a streaming fashion. As part of the design, we define MiniPipe, the smallest pipeline unit enabling multi-pipeline implementation by executing various data preprocessing tasks across the single board, giving Piper the ability to be reconfigured at runtime. Our results, using publicly released commercial pipelines, show that Piper, prototyped on a power-efficient FPGA, achieves a 39$\sim$105$\times$ speedup over a server-grade, 128-core CPU and 3$\sim$17$\times$ speedup over GPUs like RTX 3090 and A100 in multiple pipelines. The experimental analysis demonstrates that Piper provides advantages in both latency and energy efficiency for preprocessing tasks in recommender systems, providing an alternative design point for systems that today are in very high demand.
MS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels
May 13, 2024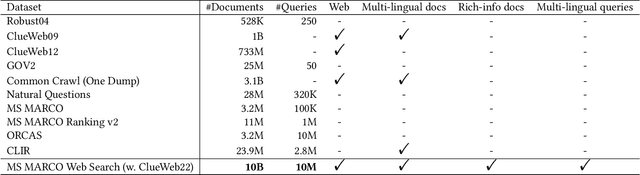
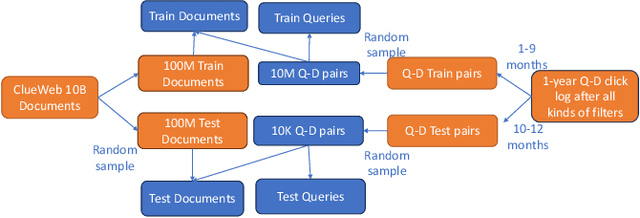
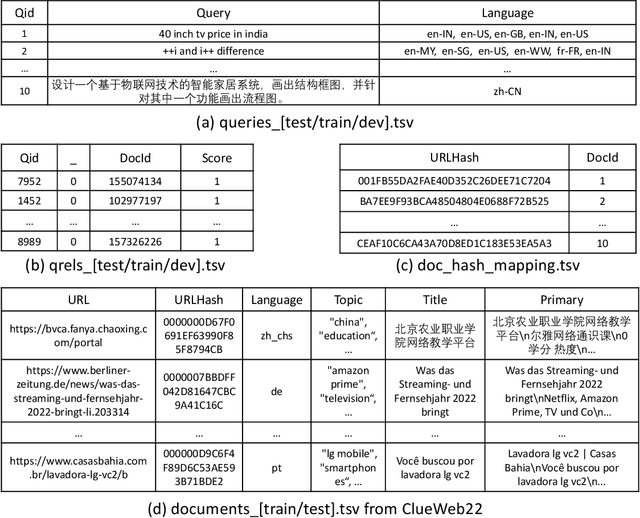
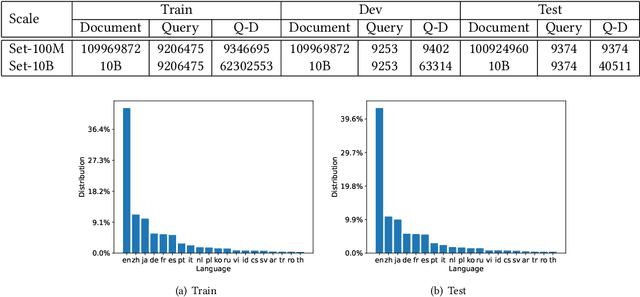
Recent breakthroughs in large models have highlighted the critical significance of data scale, labels and modals. In this paper, we introduce MS MARCO Web Search, the first large-scale information-rich web dataset, featuring millions of real clicked query-document labels. This dataset closely mimics real-world web document and query distribution, provides rich information for various kinds of downstream tasks and encourages research in various areas, such as generic end-to-end neural indexer models, generic embedding models, and next generation information access system with large language models. MS MARCO Web Search offers a retrieval benchmark with three web retrieval challenge tasks that demand innovations in both machine learning and information retrieval system research domains. As the first dataset that meets large, real and rich data requirements, MS MARCO Web Search paves the way for future advancements in AI and system research. MS MARCO Web Search dataset is available at: https://github.com/microsoft/MS-MARCO-Web-Search.
PipeRAG: Fast Retrieval-Augmented Generation via Algorithm-System Co-design
Mar 08, 2024



Retrieval-augmented generation (RAG) can enhance the generation quality of large language models (LLMs) by incorporating external token databases. However, retrievals from large databases can constitute a substantial portion of the overall generation time, particularly when retrievals are periodically performed to align the retrieved content with the latest states of generation. In this paper, we introduce PipeRAG, a novel algorithm-system co-design approach to reduce generation latency and enhance generation quality. PipeRAG integrates (1) pipeline parallelism to enable concurrent retrieval and generation processes, (2) flexible retrieval intervals to maximize the efficiency of pipeline parallelism, and (3) a performance model to automatically balance retrieval quality and latency based on the generation states and underlying hardware. Our evaluation shows that, by combining the three aforementioned methods, PipeRAG achieves up to 2.6$\times$ speedup in end-to-end generation latency while improving generation quality. These promising results showcase the effectiveness of co-designing algorithms with underlying systems, paving the way for the adoption of PipeRAG in future RAG systems.
Chameleon: a Heterogeneous and Disaggregated Accelerator System for Retrieval-Augmented Language Models
Oct 15, 2023



A Retrieval-Augmented Language Model (RALM) augments a generative language model by retrieving context-specific knowledge from an external database. This strategy facilitates impressive text generation quality even with smaller models, thus reducing orders of magnitude of computational demands. However, RALMs introduce unique system design challenges due to (a) the diverse workload characteristics between LM inference and retrieval and (b) the various system requirements and bottlenecks for different RALM configurations such as model sizes, database sizes, and retrieval frequencies. We propose Chameleon, a heterogeneous accelerator system that integrates both LM and retrieval accelerators in a disaggregated architecture. The heterogeneity ensures efficient acceleration of both LM inference and retrieval, while the accelerator disaggregation enables the system to independently scale both types of accelerators to fulfill diverse RALM requirements. Our Chameleon prototype implements retrieval accelerators on FPGAs and assigns LM inference to GPUs, with a CPU server orchestrating these accelerators over the network. Compared to CPU-based and CPU-GPU vector search systems, Chameleon achieves up to 23.72x speedup and 26.2x energy efficiency. Evaluated on various RALMs, Chameleon exhibits up to 2.16x reduction in latency and 3.18x speedup in throughput compared to the hybrid CPU-GPU architecture. These promising results pave the way for bringing accelerator heterogeneity and disaggregation into future RALM systems.
Co-design Hardware and Algorithm for Vector Search
Jul 06, 2023Vector search has emerged as the foundation for large-scale information retrieval and machine learning systems, with search engines like Google and Bing processing tens of thousands of queries per second on petabyte-scale document datasets by evaluating vector similarities between encoded query texts and web documents. As performance demands for vector search systems surge, accelerated hardware offers a promising solution in the post-Moore's Law era. We introduce \textit{FANNS}, an end-to-end and scalable vector search framework on FPGAs. Given a user-provided recall requirement on a dataset and a hardware resource budget, \textit{FANNS} automatically co-designs hardware and algorithm, subsequently generating the corresponding accelerator. The framework also supports scale-out by incorporating a hardware TCP/IP stack in the accelerator. \textit{FANNS} attains up to 23.0$\times$ and 37.2$\times$ speedup compared to FPGA and CPU baselines, respectively, and demonstrates superior scalability to GPUs, achieving 5.5$\times$ and 7.6$\times$ speedup in median and 95\textsuperscript{th} percentile (P95) latency within an eight-accelerator configuration. The remarkable performance of \textit{FANNS} lays a robust groundwork for future FPGA integration in data centers and AI supercomputers.
Switch Spaces: Learning Product Spaces with Sparse Gating
Feb 17, 2021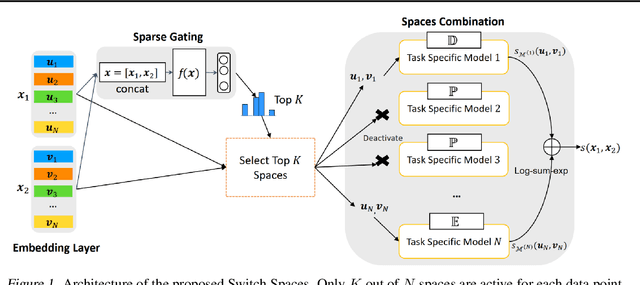
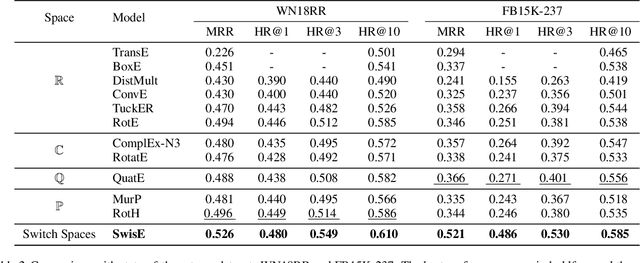
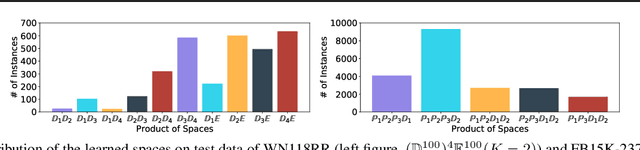
Learning embedding spaces of suitable geometry is critical for representation learning. In order for learned representations to be effective and efficient, it is ideal that the geometric inductive bias aligns well with the underlying structure of the data. In this paper, we propose Switch Spaces, a data-driven approach for learning representations in product space. Specifically, product spaces (or manifolds) are spaces of mixed curvature, i.e., a combination of multiple euclidean and non-euclidean (hyperbolic, spherical) manifolds. To this end, we introduce sparse gating mechanisms that learn to choose, combine and switch spaces, allowing them to be switchable depending on the input data with specialization. Additionally, the proposed method is also efficient and has a constant computational complexity regardless of the model size. Experiments on knowledge graph completion and item recommendations show that the proposed switch space achieves new state-of-the-art performances, outperforming pure product spaces and recently proposed task-specific models.
MicroRec: Accelerating Deep Recommendation Systems to Microseconds by Hardware and Data Structure Solutions
Oct 12, 2020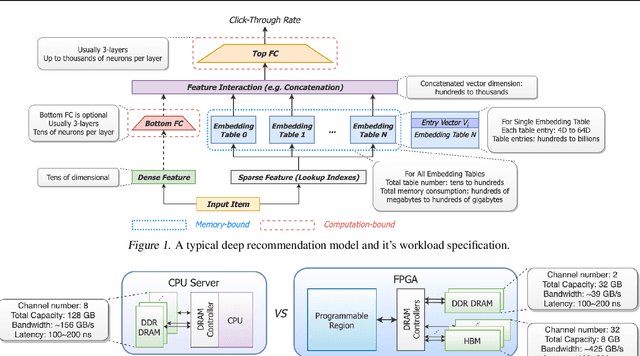
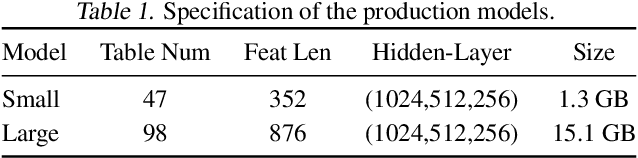
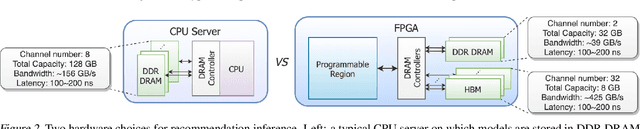
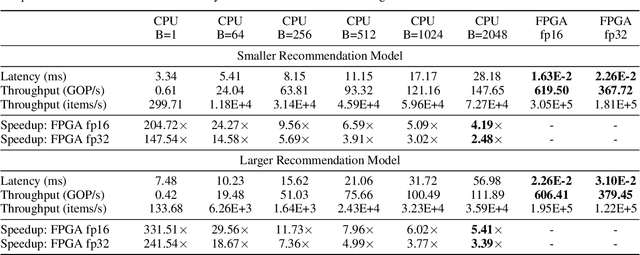
Deep neural networks are widely used in personalized recommendation systems. Unlike regular DNN inference workloads, recommendation inference is memory-bound due to the many random memory accesses needed to lookup the embedding tables. The inference is also heavily constrained in terms of latency because producing a recommendation for a user must be done in about tens of milliseconds. In this paper, we propose MicroRec, a high-performance inference engine for recommendation systems. MicroRec accelerates recommendation inference by (1) redesigning the data structures involved in the embeddings to reduce the number of lookups needed and (2) taking advantage of the availability of High-Bandwidth Memory (HBM) in FPGA accelerators to tackle the latency by enabling parallel lookups. We have implemented the resulting design on an FPGA board including the embedding lookup step as well as the complete inference process. Compared to the optimized CPU baseline (16 vCPU, AVX2-enabled), MicroRec achieves 13.8~14.7x speedup on embedding lookup alone and 2.5$~5.4x speedup for the entire recommendation inference in terms of throughput. As for latency, CPU-based engines needs milliseconds for inferring a recommendation while MicroRec only takes microseconds, a significant advantage in real-time recommendation systems.
Dynamic Sampling and Selective Masking for Communication-Efficient Federated Learning
Mar 21, 2020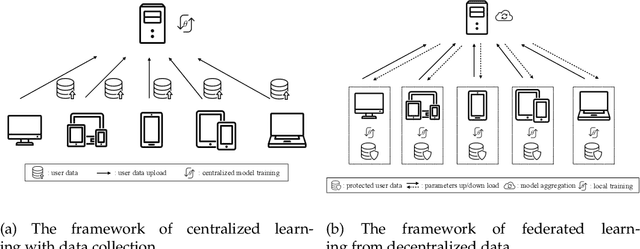

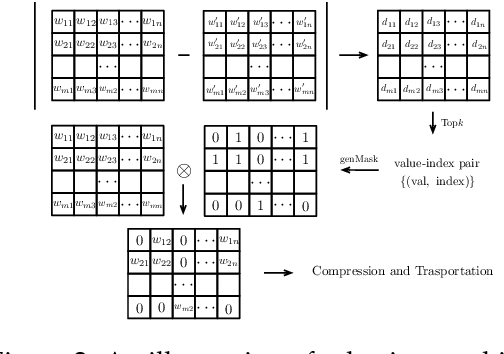
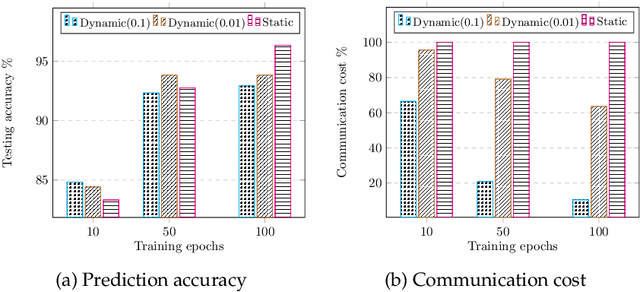
Federated learning (FL) is a novel machine learning setting which enables on-device intelligence via decentralized training and federated optimization. The rapid development of deep neural networks facilitates the learning techniques for modeling complex problems and emerges into federated deep learning under the federated setting. However, the tremendous amount of model parameters burdens the communication network with a high load of transportation. This paper introduces two approaches for improving communication efficiency by dynamic sampling and top-$k$ selective masking. The former controls the fraction of selected client models dynamically, while the latter selects parameters with top-$k$ largest values of difference for federated updating. Experiments on convolutional image classification and recurrent language modeling are conducted on three public datasets to show the effectiveness of our proposed methods.