 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Sampling and Selective Masking for Communication-Efficient Federated Learning
Paper and Code
Mar 21, 2020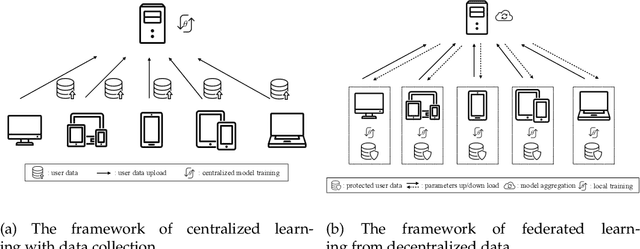

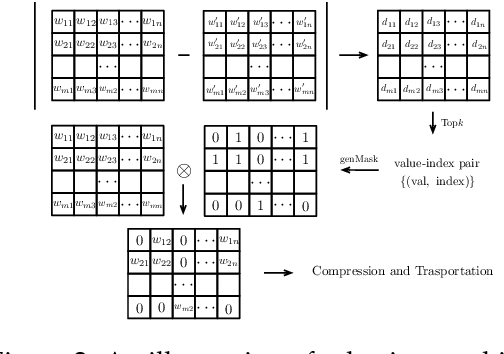
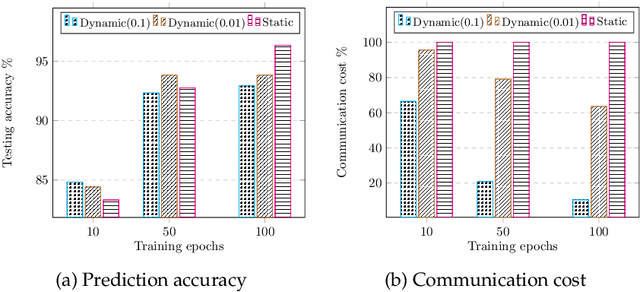
Federated learning (FL) is a novel machine learning setting which enables on-device intelligence via decentralized training and federated optimization. The rapid development of deep neural networks facilitates the learning techniques for modeling complex problems and emerges into federated deep learning under the federated setting. However, the tremendous amount of model parameters burdens the communication network with a high load of transportation. This paper introduces two approaches for improving communication efficiency by dynamic sampling and top-$k$ selective masking. The former controls the fraction of selected client models dynamically, while the latter selects parameters with top-$k$ largest values of difference for federated updating. Experiments on convolutional image classification and recurrent language modeling are conducted on three public datasets to show the effectiveness of our proposed methods.