 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels
Paper and Code
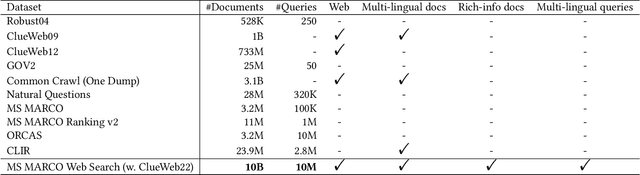
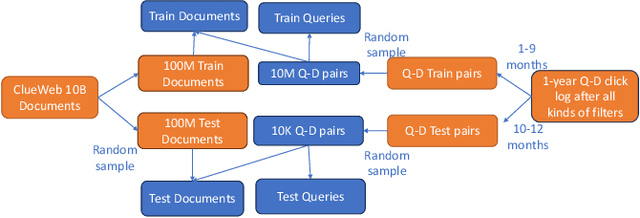
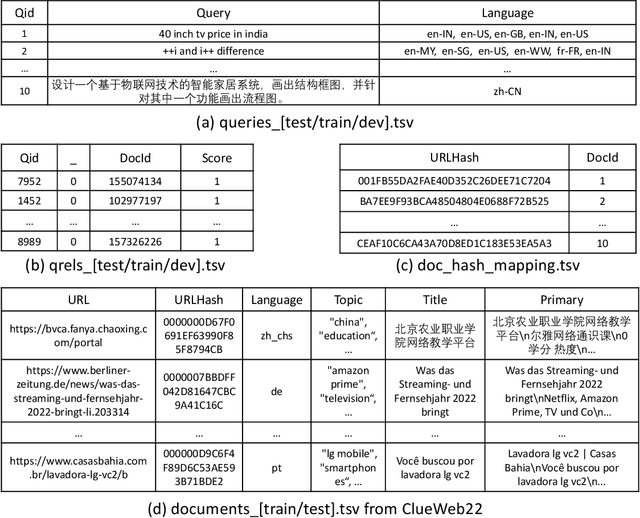
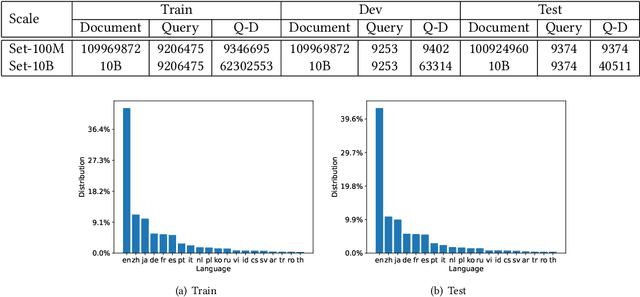
Recent breakthroughs in large models have highlighted the critical significance of data scale, labels and modals. In this paper, we introduce MS MARCO Web Search, the first large-scale information-rich web dataset, featuring millions of real clicked query-document labels. This dataset closely mimics real-world web document and query distribution, provides rich information for various kinds of downstream tasks and encourages research in various areas, such as generic end-to-end neural indexer models, generic embedding models, and next generation information access system with large language models. MS MARCO Web Search offers a retrieval benchmark with three web retrieval challenge tasks that demand innovations in both machine learning and information retrieval system research domains. As the first dataset that meets large, real and rich data requirements, MS MARCO Web Search paves the way for future advancements in AI and system research. MS MARCO Web Search dataset is available at: https://github.com/microsoft/MS-MARCO-Web-Search.