 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Attention Expert Prediction and Prefetching for Mixture-of-Experts Large Language Models
Nov 10, 2025Mixture-of-Experts (MoE) Large Language Models (LLMs) efficiently scale-up the model while keeping relatively low inference cost. As MoE models only activate part of the experts, related work has proposed expert prediction and caching methods to prefetch the experts for faster inference. However, existing approaches utilize the activations from the previous layer for prediction, incurring low accuracy and leave the first layer unoptimized. Applying complex layers or even training standalone networks for better prediction introduces high computation overhead. In this paper, we propose pre-attention expert prediction to achieve accurate and lightweight expert prefetching. The key insight is that some functions in LLMs are ranking-preserving, indicating that matching the ranking of selected experts using simple linear functions is possible. Therefore, we utilize the activations before the attention block in the same layer with 2 linear functions and ranking-aware loss to achieve accurate prediction, which also supports prefetching in the first layer. Our lightweight, pre-attention expert routers achieve 93.03% accuracy on DeepSeek V2 Lite, 94.69% on Qwen3-30B, and 97.62% on Phi-mini-MoE, showing about 15% improvement on absolute accuracy over the state-of-the-art methods.
RAGO: Systematic Performance Optimization for Retrieval-Augmented Generation Serving
Mar 21, 2025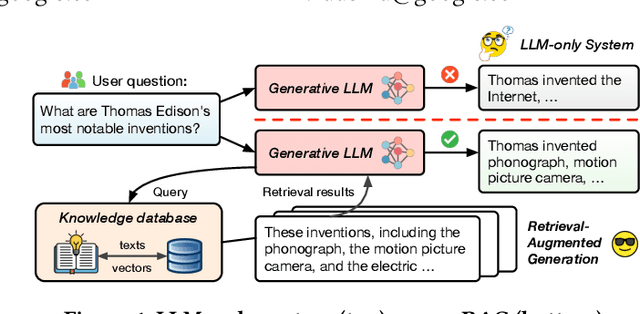



Retrieval-augmented generation (RAG), which combines large language models (LLMs) with retrievals from external knowledge databases, is emerging as a popular approach for reliable LLM serving. However, efficient RAG serving remains an open challenge due to the rapid emergence of many RAG variants and the substantial differences in workload characteristics across them. In this paper, we make three fundamental contributions to advancing RAG serving. First, we introduce RAGSchema, a structured abstraction that captures the wide range of RAG algorithms, serving as a foundation for performance optimization. Second, we analyze several representative RAG workloads with distinct RAGSchema, revealing significant performance variability across these workloads. Third, to address this variability and meet diverse performance requirements, we propose RAGO (Retrieval-Augmented Generation Optimizer), a system optimization framework for efficient RAG serving. Our evaluation shows that RAGO achieves up to a 2x increase in QPS per chip and a 55% reduction in time-to-first-token latency compared to RAG systems built on LLM-system extensions.
WARP: An Efficient Engine for Multi-Vector Retrieval
Jan 29, 2025



We study the efficiency of multi-vector retrieval methods like ColBERT and its recent variant XTR. We introduce WARP, a retrieval engine that drastically improves the efficiency of XTR-based ColBERT retrievers through three key innovations: (1) WARP$_\text{SELECT}$ for dynamic similarity imputation, (2) implicit decompression to bypass costly vector reconstruction, and (3) a two-stage reduction process for efficient scoring. Combined with optimized C++ kernels and specialized inference runtimes, WARP reduces end-to-end latency by 41x compared to XTR's reference implementation and thereby achieves a 3x speedup over PLAID from the the official ColBERT implementation. We study the efficiency of multi-vector retrieval methods like ColBERT and its recent variant XTR. We introduce WARP, a retrieval engine that drastically improves the efficiency of XTR-based ColBERT retrievers through three key innovations: (1) WARP$_\text{SELECT}$ for dynamic similarity imputation, (2) implicit decompression during retrieval, and (3) a two-stage reduction process for efficient scoring. Thanks also to highly-optimized C++ kernels and to the adoption of specialized inference runtimes, WARP can reduce end-to-end query latency relative to XTR's reference implementation by 41x. And it thereby achieves a 3x speedup over the official ColBERTv2 PLAID engine, while preserving retrieval quality.
In-Network Preprocessing of Recommender Systems on Multi-Tenant SmartNICs
Jan 21, 2025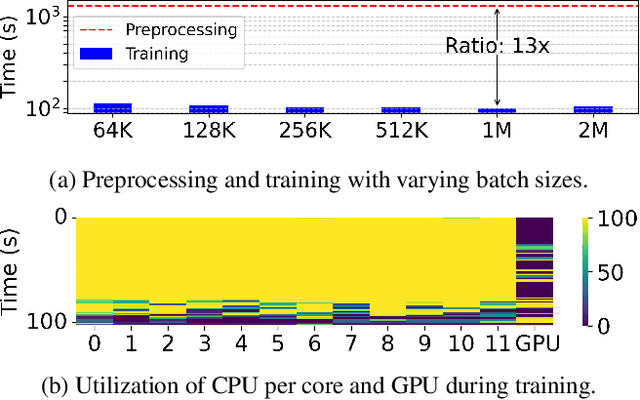

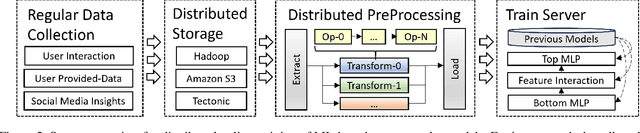

Keeping ML-based recommender models up-to-date as data drifts and evolves is essential to maintain accuracy. As a result, online data preprocessing plays an increasingly important role in serving recommender systems. Existing solutions employ multiple CPU workers to saturate the input bandwidth of a single training node. Such an approach results in high deployment costs and energy consumption. For instance, a recent report from industrial deployments shows that data storage and ingestion pipelines can account for over 60\% of the power consumption in a recommender system. In this paper, we tackle the issue from a hardware perspective by introducing Piper, a flexible and network-attached accelerator that executes data loading and preprocessing pipelines in a streaming fashion. As part of the design, we define MiniPipe, the smallest pipeline unit enabling multi-pipeline implementation by executing various data preprocessing tasks across the single board, giving Piper the ability to be reconfigured at runtime. Our results, using publicly released commercial pipelines, show that Piper, prototyped on a power-efficient FPGA, achieves a 39$\sim$105$\times$ speedup over a server-grade, 128-core CPU and 3$\sim$17$\times$ speedup over GPUs like RTX 3090 and A100 in multiple pipelines. The experimental analysis demonstrates that Piper provides advantages in both latency and energy efficiency for preprocessing tasks in recommender systems, providing an alternative design point for systems that today are in very high demand.
TablePuppet: A Generic Framework for Relational Federated Learning
Mar 23, 2024Current federated learning (FL) approaches view decentralized training data as a single table, divided among participants either horizontally (by rows) or vertically (by columns). However, these approaches are inadequate for handling distributed relational tables across databases. This scenario requires intricate SQL operations like joins and unions to obtain the training data, which is either costly or restricted by privacy concerns. This raises the question: can we directly run FL on distributed relational tables? In this paper, we formalize this problem as relational federated learning (RFL). We propose TablePuppet, a generic framework for RFL that decomposes the learning process into two steps: (1) learning over join (LoJ) followed by (2) learning over union (LoU). In a nutshell, LoJ pushes learning down onto the vertical tables being joined, and LoU further pushes learning down onto the horizontal partitions of each vertical table. TablePuppet incorporates computation/communication optimizations to deal with the duplicate tuples introduced by joins, as well as differential privacy (DP) to protect against both feature and label leakages. We demonstrate the efficiency of TablePuppet in combination with two widely-used ML training algorithms, stochastic gradient descent (SGD) and alternating direction method of multipliers (ADMM), and compare their computation/communication complexity. We evaluate the SGD/ADMM algorithms developed atop TablePuppet by training diverse ML models. Our experimental results show that TablePuppet achieves model accuracy comparable to the centralized baselines running directly atop the SQL results. Moreover, ADMM takes less communication time than SGD to converge to similar model accuracy.
ACCL+: an FPGA-Based Collective Engine for Distributed Applications
Dec 18, 2023FPGAs are increasingly prevalent in cloud deployments, serving as Smart NICs or network-attached accelerators. Despite their potential, developing distributed FPGA-accelerated applications remains cumbersome due to the lack of appropriate infrastructure and communication abstractions. To facilitate the development of distributed applications with FPGAs, in this paper we propose ACCL+, an open-source versatile FPGA-based collective communication library. Portable across different platforms and supporting UDP, TCP, as well as RDMA, ACCL+ empowers FPGA applications to initiate direct FPGA-to-FPGA collective communication. Additionally, it can serve as a collective offload engine for CPU applications, freeing the CPU from networking tasks. It is user-extensible, allowing new collectives to be implemented and deployed without having to re-synthesize the FPGA circuit. We evaluated ACCL+ on an FPGA cluster with 100 Gb/s networking, comparing its performance against software MPI over RDMA. The results demonstrate ACCL+'s significant advantages for FPGA-based distributed applications and highly competitive performance for CPU applications. We showcase ACCL+'s dual role with two use cases: seamlessly integrating as a collective offload engine to distribute CPU-based vector-matrix multiplication, and serving as a crucial and efficient component in designing fully FPGA-based distributed deep-learning recommendation inference.
Chameleon: a Heterogeneous and Disaggregated Accelerator System for Retrieval-Augmented Language Models
Oct 15, 2023



A Retrieval-Augmented Language Model (RALM) augments a generative language model by retrieving context-specific knowledge from an external database. This strategy facilitates impressive text generation quality even with smaller models, thus reducing orders of magnitude of computational demands. However, RALMs introduce unique system design challenges due to (a) the diverse workload characteristics between LM inference and retrieval and (b) the various system requirements and bottlenecks for different RALM configurations such as model sizes, database sizes, and retrieval frequencies. We propose Chameleon, a heterogeneous accelerator system that integrates both LM and retrieval accelerators in a disaggregated architecture. The heterogeneity ensures efficient acceleration of both LM inference and retrieval, while the accelerator disaggregation enables the system to independently scale both types of accelerators to fulfill diverse RALM requirements. Our Chameleon prototype implements retrieval accelerators on FPGAs and assigns LM inference to GPUs, with a CPU server orchestrating these accelerators over the network. Compared to CPU-based and CPU-GPU vector search systems, Chameleon achieves up to 23.72x speedup and 26.2x energy efficiency. Evaluated on various RALMs, Chameleon exhibits up to 2.16x reduction in latency and 3.18x speedup in throughput compared to the hybrid CPU-GPU architecture. These promising results pave the way for bringing accelerator heterogeneity and disaggregation into future RALM systems.
Co-design Hardware and Algorithm for Vector Search
Jul 06, 2023Vector search has emerged as the foundation for large-scale information retrieval and machine learning systems, with search engines like Google and Bing processing tens of thousands of queries per second on petabyte-scale document datasets by evaluating vector similarities between encoded query texts and web documents. As performance demands for vector search systems surge, accelerated hardware offers a promising solution in the post-Moore's Law era. We introduce \textit{FANNS}, an end-to-end and scalable vector search framework on FPGAs. Given a user-provided recall requirement on a dataset and a hardware resource budget, \textit{FANNS} automatically co-designs hardware and algorithm, subsequently generating the corresponding accelerator. The framework also supports scale-out by incorporating a hardware TCP/IP stack in the accelerator. \textit{FANNS} attains up to 23.0$\times$ and 37.2$\times$ speedup compared to FPGA and CPU baselines, respectively, and demonstrates superior scalability to GPUs, achieving 5.5$\times$ and 7.6$\times$ speedup in median and 95\textsuperscript{th} percentile (P95) latency within an eight-accelerator configuration. The remarkable performance of \textit{FANNS} lays a robust groundwork for future FPGA integration in data centers and AI supercomputers.
Towards Demystifying Serverless Machine Learning Training
May 17, 2021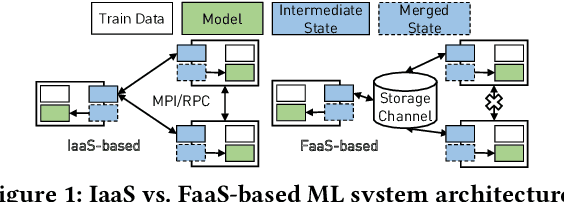
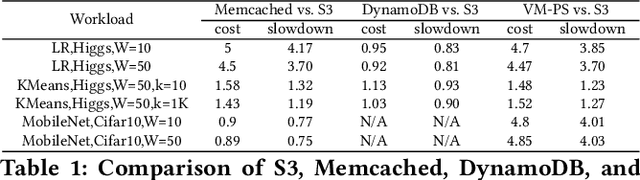
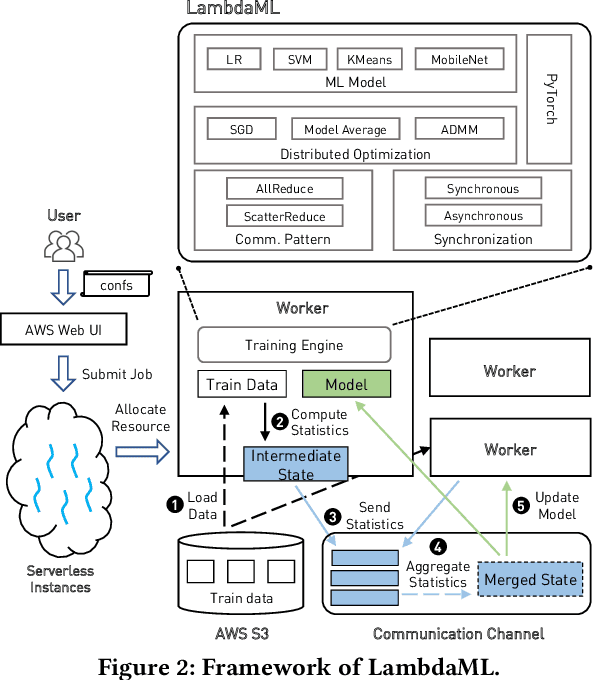
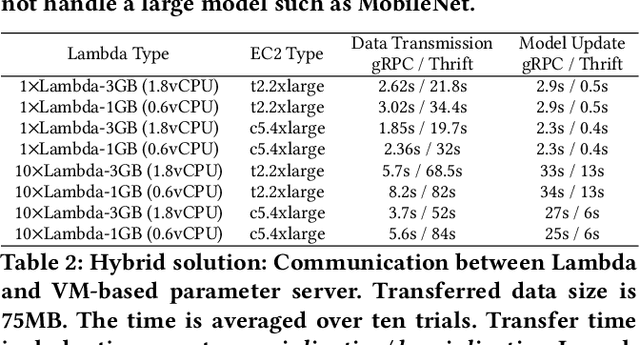
The appeal of serverless (FaaS) has triggered a growing interest on how to use it in data-intensive applications such as ETL, query processing, or machine learning (ML). Several systems exist for training large-scale ML models on top of serverless infrastructures (e.g., AWS Lambda) but with inconclusive results in terms of their performance and relative advantage over "serverful" infrastructures (IaaS). In this paper we present a systematic, comparative study of distributed ML training over FaaS and IaaS. We present a design space covering design choices such as optimization algorithms and synchronization protocols, and implement a platform, LambdaML, that enables a fair comparison between FaaS and IaaS. We present experimental results using LambdaML, and further develop an analytic model to capture cost/performance tradeoffs that must be considered when opting for a serverless infrastructure. Our results indicate that ML training pays off in serverless only for models with efficient (i.e., reduced) communication and that quickly converge. In general, FaaS can be much faster but it is never significantly cheaper than IaaS.
MicroRec: Accelerating Deep Recommendation Systems to Microseconds by Hardware and Data Structure Solutions
Oct 12, 2020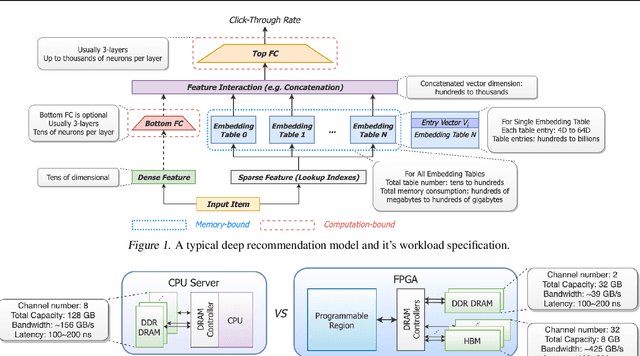
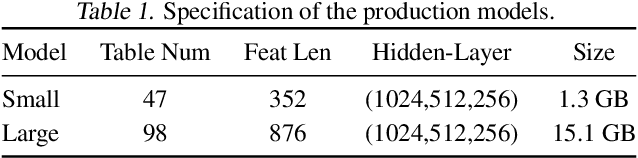
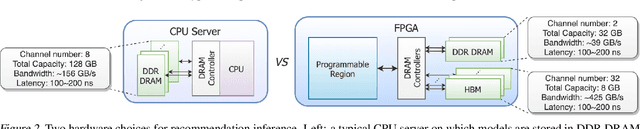
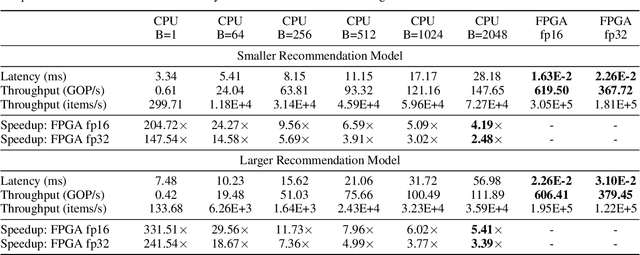
Deep neural networks are widely used in personalized recommendation systems. Unlike regular DNN inference workloads, recommendation inference is memory-bound due to the many random memory accesses needed to lookup the embedding tables. The inference is also heavily constrained in terms of latency because producing a recommendation for a user must be done in about tens of milliseconds. In this paper, we propose MicroRec, a high-performance inference engine for recommendation systems. MicroRec accelerates recommendation inference by (1) redesigning the data structures involved in the embeddings to reduce the number of lookups needed and (2) taking advantage of the availability of High-Bandwidth Memory (HBM) in FPGA accelerators to tackle the latency by enabling parallel lookups. We have implemented the resulting design on an FPGA board including the embedding lookup step as well as the complete inference process. Compared to the optimized CPU baseline (16 vCPU, AVX2-enabled), MicroRec achieves 13.8~14.7x speedup on embedding lookup alone and 2.5$~5.4x speedup for the entire recommendation inference in terms of throughput. As for latency, CPU-based engines needs milliseconds for inferring a recommendation while MicroRec only takes microseconds, a significant advantage in real-time recommendation systems.