 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment Policy Optimization: Effective Segment-Level Credit Assignment in RL for Large Language Models
May 29, 2025Enhancing the reasoning capabilities of large language models effectively using reinforcement learning (RL) remains a crucial challenge. Existing approaches primarily adopt two contrasting advantage estimation granularities: Token-level methods (e.g., PPO) aim to provide the fine-grained advantage signals but suffer from inaccurate estimation due to difficulties in training an accurate critic model. On the other extreme, trajectory-level methods (e.g., GRPO) solely rely on a coarse-grained advantage signal from the final reward, leading to imprecise credit assignment. To address these limitations, we propose Segment Policy Optimization (SPO), a novel RL framework that leverages segment-level advantage estimation at an intermediate granularity, achieving a better balance by offering more precise credit assignment than trajectory-level methods and requiring fewer estimation points than token-level methods, enabling accurate advantage estimation based on Monte Carlo (MC) without a critic model. SPO features three components with novel strategies: (1) flexible segment partition; (2) accurate segment advantage estimation; and (3) policy optimization using segment advantages, including a novel probability-mask strategy. We further instantiate SPO for two specific scenarios: (1) SPO-chain for short chain-of-thought (CoT), featuring novel cutpoint-based partition and chain-based advantage estimation, achieving $6$-$12$ percentage point improvements in accuracy over PPO and GRPO on GSM8K. (2) SPO-tree for long CoT, featuring novel tree-based advantage estimation, which significantly reduces the cost of MC estimation, achieving $7$-$11$ percentage point improvements over GRPO on MATH500 under 2K and 4K context evaluation. We make our code publicly available at https://github.com/AIFrameResearch/SPO.
TablePuppet: A Generic Framework for Relational Federated Learning
Mar 23, 2024Current federated learning (FL) approaches view decentralized training data as a single table, divided among participants either horizontally (by rows) or vertically (by columns). However, these approaches are inadequate for handling distributed relational tables across databases. This scenario requires intricate SQL operations like joins and unions to obtain the training data, which is either costly or restricted by privacy concerns. This raises the question: can we directly run FL on distributed relational tables? In this paper, we formalize this problem as relational federated learning (RFL). We propose TablePuppet, a generic framework for RFL that decomposes the learning process into two steps: (1) learning over join (LoJ) followed by (2) learning over union (LoU). In a nutshell, LoJ pushes learning down onto the vertical tables being joined, and LoU further pushes learning down onto the horizontal partitions of each vertical table. TablePuppet incorporates computation/communication optimizations to deal with the duplicate tuples introduced by joins, as well as differential privacy (DP) to protect against both feature and label leakages. We demonstrate the efficiency of TablePuppet in combination with two widely-used ML training algorithms, stochastic gradient descent (SGD) and alternating direction method of multipliers (ADMM), and compare their computation/communication complexity. We evaluate the SGD/ADMM algorithms developed atop TablePuppet by training diverse ML models. Our experimental results show that TablePuppet achieves model accuracy comparable to the centralized baselines running directly atop the SQL results. Moreover, ADMM takes less communication time than SGD to converge to similar model accuracy.
Stochastic Gradient Descent without Full Data Shuffle
Jun 12, 2022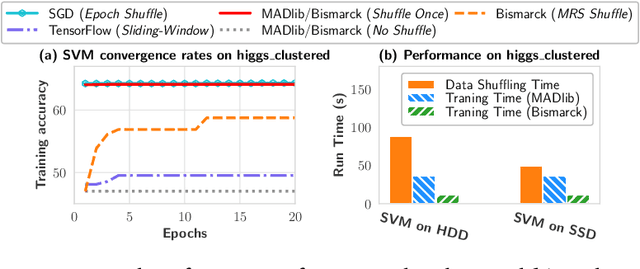

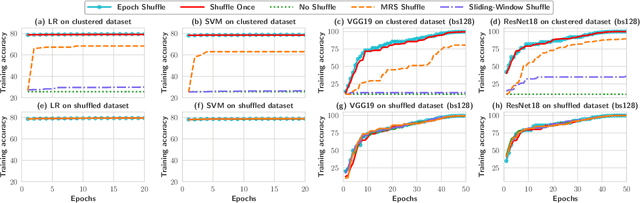
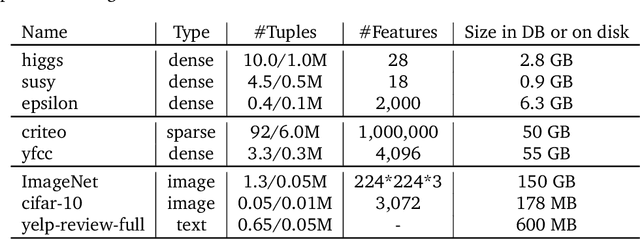
Stochastic gradient descent (SGD) is the cornerstone of modern machine learning (ML) systems. Despite its computational efficiency, SGD requires random data access that is inherently inefficient when implemented in systems that rely on block-addressable secondary storage such as HDD and SSD, e.g., TensorFlow/PyTorch and in-DB ML systems over large files. To address this impedance mismatch, various data shuffling strategies have been proposed to balance the convergence rate of SGD (which favors randomness) and its I/O performance (which favors sequential access). In this paper, we first conduct a systematic empirical study on existing data shuffling strategies, which reveals that all existing strategies have room for improvement -- they all suffer in terms of I/O performance or convergence rate. With this in mind, we propose a simple but novel hierarchical data shuffling strategy, CorgiPile. Compared with existing strategies, CorgiPile avoids a full data shuffle while maintaining comparable convergence rate of SGD as if a full shuffle were performed. We provide a non-trivial theoretical analysis of CorgiPile on its convergence behavior. We further integrate CorgiPile into PyTorch by designing new parallel/distributed shuffle operators inside a new CorgiPileDataSet API. We also integrate CorgiPile into PostgreSQL by introducing three new physical operators with optimizations. Our experimental results show that CorgiPile can achieve comparable convergence rate with the full shuffle based SGD for both deep learning and generalized linear models. For deep learning models on ImageNet dataset, CorgiPile is 1.5X faster than PyTorch with full data shuffle. For in-DB ML with linear models, CorgiPile is 1.6X-12.8X faster than two state-of-the-art in-DB ML systems, Apache MADlib and Bismarck, on both HDD and SSD.
Sync-Switch: Hybrid Parameter Synchronization for Distributed Deep Learning
Apr 20, 2021Stochastic Gradient Descent (SGD) has become the de facto way to train deep neural networks in distributed clusters. A critical factor in determining the training throughput and model accuracy is the choice of the parameter synchronization protocol. For example, while Bulk Synchronous Parallel (BSP) often achieves better converged accuracy, the corresponding training throughput can be negatively impacted by stragglers. In contrast, Asynchronous Parallel (ASP) can have higher throughput, but its convergence and accuracy can be impacted by stale gradients. To improve the performance of synchronization protocol, recent work often focuses on designing new protocols with a heavy reliance on hard-to-tune hyper-parameters. In this paper, we design a hybrid synchronization approach that exploits the benefits of both BSP and ASP, i.e., reducing training time while simultaneously maintaining the converged accuracy. Based on extensive empirical profiling, we devise a collection of adaptive policies that determine how and when to switch between synchronization protocols. Our policies include both offline ones that target recurring jobs and online ones for handling transient stragglers. We implement the proposed policies in a prototype system, called Sync-Switch, on top of TensorFlow, and evaluate the training performance with popular deep learning models and datasets. Our experiments show that Sync-Switch achieves up to 5.13X throughput speedup and similar converged accuracy when comparing to BSP. Further, we observe that Sync-Switch achieves 3.8% higher converged accuracy with just 1.23X the training time compared to training with ASP. Moreover, Sync-Switch can be used in settings when training with ASP leads to divergence errors. Sync-Switch achieves all of these benefits with very low overhead, e.g., the framework overhead can be as low as 1.7% of the total training time.
Speeding up Deep Learning with Transient Servers
Feb 28, 2019

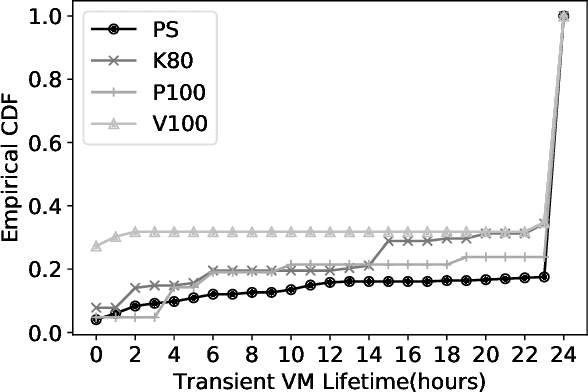
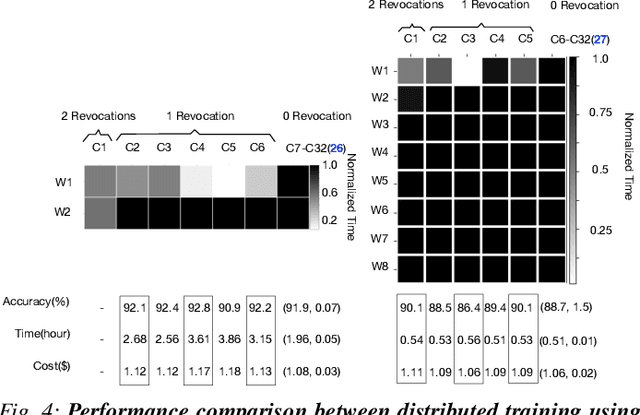
Distributed training frameworks, like TensorFlow, have been proposed as a means to reduce the training time of deep learning models by using a cluster of GPU servers. While such speedups are often desirable---e.g., for rapidly evaluating new model designs---they often come with significantly higher monetary costs due to sublinear scalability. In this paper, we investigate the feasibility of using training clusters composed of cheaper transient GPU servers to get the benefits of distributed training without the high costs. We conduct the first large-scale empirical analysis, launching more than a thousand GPU servers of various capacities, aimed at understanding the characteristics of transient GPU servers and their impact on distributed training performance. Our study demonstrates the potential of transient servers with a speedup of 7.7X with more than 62.9% monetary savings for some cluster configurations. We also identify a number of important challenges and opportunities for redesigning distributed training frameworks to be transient-aware. For example, the dynamic cost and availability characteristics of transient servers suggest the need for frameworks to dynamically change cluster configurations to best take advantage of current conditions.