 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Quality Enhancement for G-PCC Compressed Dynamic Point Clouds
Mar 25, 2026Point cloud compression often introduces noticeable reconstruction artifacts, which makes quality enhancement necessary. Existing approaches typically assume prior knowledge of the distortion level and train multiple models with identical architectures, each designed for a specific distortion setting. This significantly limits their practical applicability in scenarios where the distortion level is unknown and computational resources are limited. To overcome these limitations, we propose the first blind quality enhancement (BQE) model for compressed dynamic point clouds. BQE enhances compressed point clouds under unknown distortion levels by exploiting temporal dependencies and jointly modeling feature similarity and differences across multiple distortion levels. It consists of a joint progressive feature extraction branch and an adaptive feature fusion branch. In the joint progressive feature extraction branch, consecutive reconstructed frames are first fed into a recoloring-based motion compensation module to generate temporally aligned virtual reference frames. These frames are then fused by a temporal correlation-guided cross-attention module and processed by a progressive feature extraction module to obtain hierarchical features at different distortion levels. In the adaptive feature fusion branch, the current reconstructed frame is input to a quality estimation module to predict a weighting distribution that guides the adaptive weighted fusion of these hierarchical features. When applied to the latest geometry-based point cloud compression (G-PCC) reference software, i.e., test model category13 version 28, BQE achieved average PSNR improvements of 0.535 dB, 0.403 dB, and 0.453 dB, with BD-rates of -17.4%, -20.5%, and -20.1% for the Luma, Cb, and Cr components, respectively.
A High-Fidelity Robotic Manipulator Teleoperation Framework for Human-Centered Augmented Reality Evaluation
Feb 06, 2026Validating Augmented Reality (AR) tracking and interaction models requires precise, repeatable ground-truth motion. However, human users cannot reliably perform consistent motion due to biomechanical variability. Robotic manipulators are promising to act as human motion proxies if they can mimic human movements. In this work, we design and implement ARBot, a real-time teleoperation platform that can effectively capture natural human motion and accurately replay the movements via robotic manipulators. ARBot includes two capture models: stable wrist motion capture via a custom CV and IMU pipeline, and natural 6-DOF control via a mobile application. We design a proactively-safe QP controller to ensure smooth, jitter-free execution of the robotic manipulator, enabling it to function as a high-fidelity record and replay physical proxy. We open-source ARBot and release a benchmark dataset of 132 human and synthetic trajectories captured using ARBot to support controllable and scalable AR evaluation.
Learning Dynamic Scene Reconstruction with Sinusoidal Geometric Priors
Dec 25, 2025We propose SirenPose, a novel loss function that combines the periodic activation properties of sinusoidal representation networks with geometric priors derived from keypoint structures to improve the accuracy of dynamic 3D scene reconstruction. Existing approaches often struggle to maintain motion modeling accuracy and spatiotemporal consistency in fast moving and multi target scenes. By introducing physics inspired constraint mechanisms, SirenPose enforces coherent keypoint predictions across both spatial and temporal dimensions. We further expand the training dataset to 600,000 annotated instances to support robust learning. Experimental results demonstrate that models trained with SirenPose achieve significant improvements in spatiotemporal consistency metrics compared to prior methods, showing superior performance in handling rapid motion and complex scene changes.
UGAE: Unified Geometry and Attribute Enhancement for G-PCC Compressed Point Clouds
Oct 27, 2025Lossy compression of point clouds reduces storage and transmission costs; however, it inevitably leads to irreversible distortion in geometry structure and attribute information. To address these issues, we propose a unified geometry and attribute enhancement (UGAE) framework, which consists of three core components: post-geometry enhancement (PoGE), pre-attribute enhancement (PAE), and post-attribute enhancement (PoAE). In PoGE, a Transformer-based sparse convolutional U-Net is used to reconstruct the geometry structure with high precision by predicting voxel occupancy probabilities. Building on the refined geometry structure, PAE introduces an innovative enhanced geometry-guided recoloring strategy, which uses a detail-aware K-Nearest Neighbors (DA-KNN) method to achieve accurate recoloring and effectively preserve high-frequency details before attribute compression. Finally, at the decoder side, PoAE uses an attribute residual prediction network with a weighted mean squared error (W-MSE) loss to enhance the quality of high-frequency regions while maintaining the fidelity of low-frequency regions. UGAE significantly outperformed existing methods on three benchmark datasets: 8iVFB, Owlii, and MVUB. Compared to the latest G-PCC test model (TMC13v29), UGAE achieved an average BD-PSNR gain of 9.98 dB and 90.98% BD-bitrate savings for geometry under the D1 metric, as well as a 3.67 dB BD-PSNR improvement with 56.88% BD-bitrate savings for attributes on the Y component. Additionally, it improved perceptual quality significantly.
AR as an Evaluation Playground: Bridging Metrics and Visual Perception of Computer Vision Models
Aug 06, 2025Human perception studies can provide complementary insights to qualitative evaluation for understanding computer vision (CV) model performance. However, conducting human perception studies remains a non-trivial task, it often requires complex, end-to-end system setups that are time-consuming and difficult to scale. In this paper, we explore the unique opportunity presented by augmented reality (AR) for helping CV researchers to conduct perceptual studies. We design ARCADE, an evaluation platform that allows researchers to easily leverage AR's rich context and interactivity for human-centered CV evaluation. Specifically, ARCADE supports cross-platform AR data collection, custom experiment protocols via pluggable model inference, and AR streaming for user studies. We demonstrate ARCADE using two types of CV models, depth and lighting estimation and show that AR tasks can be effectively used to elicit human perceptual judgments of model quality. We also evaluate the systems usability and performance across different deployment and study settings, highlighting its flexibility and effectiveness as a human-centered evaluation platform.
STQE: Spatial-Temporal Quality Enhancement for G-PCC Compressed Dynamic Point Clouds
Jul 23, 2025Very few studies have addressed quality enhancement for compressed dynamic point clouds. In particular, the effective exploitation of spatial-temporal correlations between point cloud frames remains largely unexplored. Addressing this gap, we propose a spatial-temporal attribute quality enhancement (STQE) network that exploits both spatial and temporal correlations to improve the visual quality of G-PCC compressed dynamic point clouds. Our contributions include a recoloring-based motion compensation module that remaps reference attribute information to the current frame geometry to achieve precise inter-frame geometric alignment, a channel-aware temporal attention module that dynamically highlights relevant regions across bidirectional reference frames, a Gaussian-guided neighborhood feature aggregation module that efficiently captures spatial dependencies between geometry and color attributes, and a joint loss function based on the Pearson correlation coefficient, designed to alleviate over-smoothing effects typical of point-wise mean squared error optimization. When applied to the latest G-PCC test model, STQE achieved improvements of 0.855 dB, 0.682 dB, and 0.828 dB in delta PSNR, with Bj{\o}ntegaard Delta rate (BD-rate) reductions of -25.2%, -31.6%, and -32.5% for the Luma, Cb, and Cr components, respectively.
CS-Net:Contribution-based Sampling Network for Point Cloud Simplification
Jan 18, 2025



Point cloud sampling plays a crucial role in reducing computation costs and storage requirements for various vision tasks. Traditional sampling methods, such as farthest point sampling, lack task-specific information and, as a result, cannot guarantee optimal performance in specific applications. Learning-based methods train a network to sample the point cloud for the targeted downstream task. However, they do not guarantee that the sampled points are the most relevant ones. Moreover, they may result in duplicate sampled points, which requires completion of the sampled point cloud through post-processing techniques. To address these limitations, we propose a contribution-based sampling network (CS-Net), where the sampling operation is formulated as a Top-k operation. To ensure that the network can be trained in an end-to-end way using gradient descent algorithms, we use a differentiable approximation to the Top-k operation via entropy regularization of an optimal transport problem. Our network consists of a feature embedding module, a cascade attention module, and a contribution scoring module. The feature embedding module includes a specifically designed spatial pooling layer to reduce parameters while preserving important features. The cascade attention module combines the outputs of three skip connected offset attention layers to emphasize the attractive features and suppress less important ones. The contribution scoring module generates a contribution score for each point and guides the sampling process to prioritize the most important ones. Experiments on the ModelNet40 and PU147 showed that CS-Net achieved state-of-the-art performance in two semantic-based downstream tasks (classification and registration) and two reconstruction-based tasks (compression and surface reconstruction).
CleAR: Robust Context-Guided Generative Lighting Estimation for Mobile Augmented Reality
Nov 04, 2024


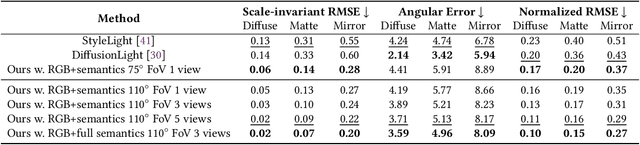
High-quality environment lighting is the foundation of creating immersive user experiences in mobile augmented reality (AR) applications. However, achieving visually coherent environment lighting estimation for Mobile AR is challenging due to several key limitations associated with AR device sensing capabilities, including limitations in device camera FoV and pixel dynamic ranges. Recent advancements in generative AI, which can generate high-quality images from different types of prompts, including texts and images, present a potential solution for high-quality lighting estimation. Still, to effectively use generative image diffusion models, we must address their key limitations of generation hallucination and slow inference process. To do so, in this work, we design and implement a generative lighting estimation system called CleAR that can produce high-quality and diverse environment maps in the format of 360$^\circ$ images. Specifically, we design a two-step generation pipeline guided by AR environment context data to ensure the results follow physical environment visual context and color appearances. To improve the estimation robustness under different lighting conditions, we design a real-time refinement component to adjust lighting estimation results on AR devices. To train and test our generative models, we curate a large-scale environment lighting estimation dataset with diverse lighting conditions. Through quantitative evaluation and user study, we show that CleAR outperforms state-of-the-art lighting estimation methods on both estimation accuracy and robustness. Moreover, CleAR supports real-time refinement of lighting estimation results, ensuring robust and timely environment lighting updates for AR applications. Our end-to-end generative estimation takes as fast as 3.2 seconds, outperforming state-of-the-art methods by 110x.
SPAC: Sampling-based Progressive Attribute Compression for Dense Point Clouds
Sep 16, 2024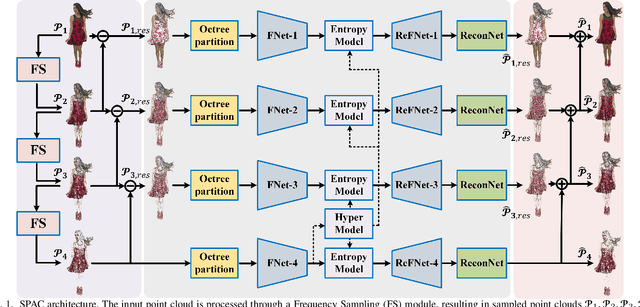
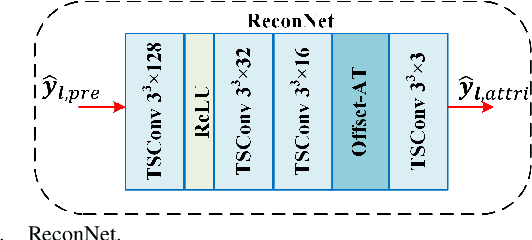
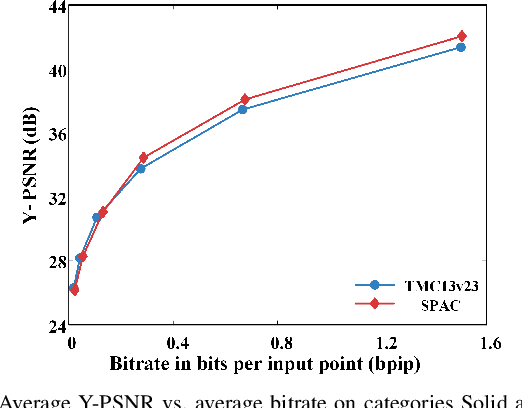
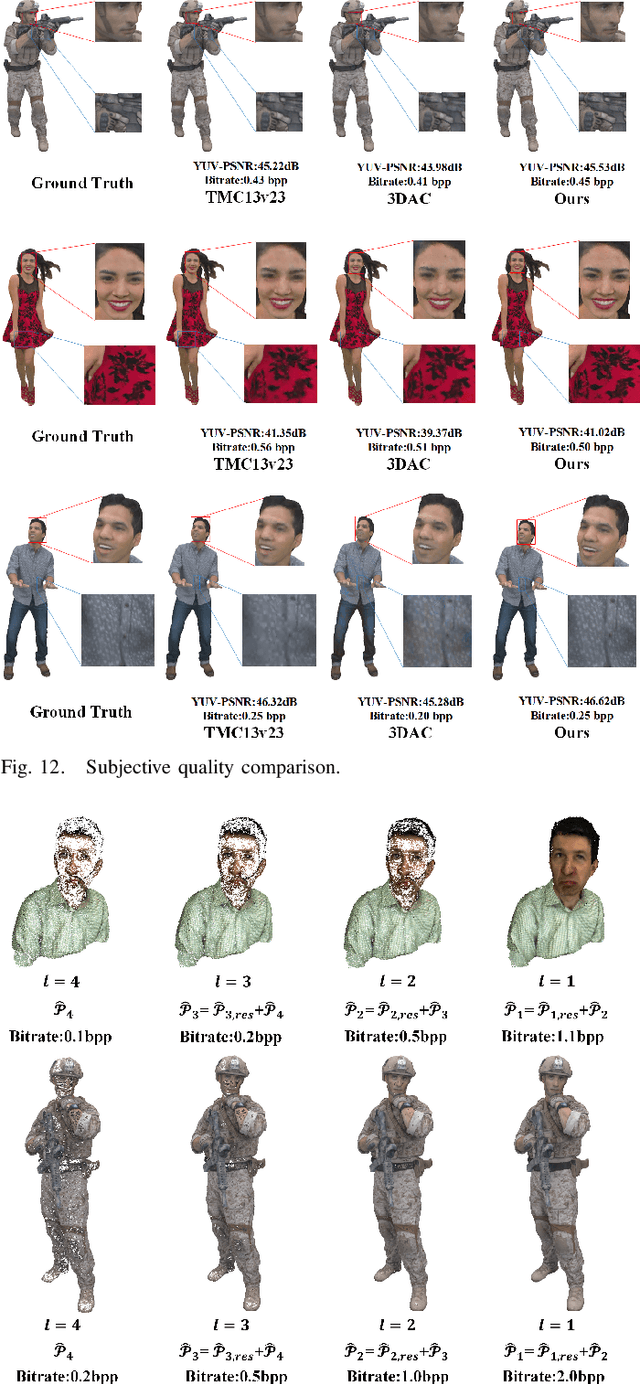
We propose an end-to-end attribute compression method for dense point clouds. The proposed method combines a frequency sampling module, an adaptive scale feature extraction module with geometry assistance, and a global hyperprior entropy model. The frequency sampling module uses a Hamming window and the Fast Fourier Transform to extract high-frequency components of the point cloud. The difference between the original point cloud and the sampled point cloud is divided into multiple sub-point clouds. These sub-point clouds are then partitioned using an octree, providing a structured input for feature extraction. The feature extraction module integrates adaptive convolutional layers and uses offset-attention to capture both local and global features. Then, a geometry-assisted attribute feature refinement module is used to refine the extracted attribute features. Finally, a global hyperprior model is introduced for entropy encoding. This model propagates hyperprior parameters from the deepest (base) layer to the other layers, further enhancing the encoding efficiency. At the decoder, a mirrored network is used to progressively restore features and reconstruct the color attribute through transposed convolutional layers. The proposed method encodes base layer information at a low bitrate and progressively adds enhancement layer information to improve reconstruction accuracy. Compared to the latest G-PCC test model (TMC13v23) under the MPEG common test conditions (CTCs), the proposed method achieved an average Bjontegaard delta bitrate reduction of 24.58% for the Y component (21.23% for YUV combined) on the MPEG Category Solid dataset and 22.48% for the Y component (17.19% for YUV combined) on the MPEG Category Dense dataset. This is the first instance of a learning-based codec outperforming the G-PCC standard on these datasets under the MPEG CTCs.
HybridDepth: Robust Depth Fusion for Mobile AR by Leveraging Depth from Focus and Single-Image Priors
Jul 26, 2024



We propose HYBRIDDEPTH, a robust depth estimation pipeline that addresses the unique challenges of depth estimation for mobile AR, such as scale ambiguity, hardware heterogeneity, and generalizability. HYBRIDDEPTH leverages the camera features available on mobile devices. It effectively combines the scale accuracy inherent in Depth from Focus (DFF) methods with the generalization capabilities enabled by strong single-image depth priors. By utilizing the focal planes of a mobile camera, our approach accurately captures depth values from focused pixels and applies these values to compute scale and shift parameters for transforming relative depths into metric depths. We test our pipeline as an end-to-end system, with a newly developed mobile client to capture focal stacks, which are then sent to a GPU-powered server for depth estimation. Through comprehensive quantitative and qualitative analyses, we demonstrate that HYBRIDDEPTH not only outperforms state-of-the-art (SOTA) models in common datasets (DDFF12, NYU Depth v2) and a real-world AR dataset ARKitScenes but also demonstrates strong zero-shot generalization. For example, HYBRIDDEPTH trained on NYU Depth v2 achieves comparable performance on the DDFF12 to existing models trained on DDFF12. it also outperforms all the SOTA models in zero-shot performance on the ARKitScenes dataset. Additionally, we conduct a qualitative comparison between our model and the ARCore framework, demonstrating that our models output depth maps are significantly more accurate in terms of structural details and metric accuracy. The source code of this project is available at github.