 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN4MC: Neural 4D Mesh Compression
Feb 23, 2026We present N4MC, the first 4D neural compression framework to efficiently compress time-varying mesh sequences by exploiting their temporal redundancy. Unlike prior neural mesh compression methods that treat each mesh frame independently, N4MC takes inspiration from inter-frame compression in 2D video codecs, and learns motion compensation in long mesh sequences. Specifically, N4MC converts consecutive irregular mesh frames into regular 4D tensors to provide a uniform and compact representation. These tensors are then condensed using an auto-decoder, which captures both spatial and temporal correlations for redundancy removal. To enhance temporal coherence, we introduce a transformer-based interpolation model that predicts intermediate mesh frames conditioned on latent embeddings derived from tracked volume centers, eliminating motion ambiguities. Extensive evaluations show that N4MC outperforms state-of-the-art in rate-distortion performance, while enabling real-time decoding of 4D mesh sequences. The implementation of our method is available at: https://github.com/frozzzen3/N4MC.
Grasp-HGN: Grasping the Unexpected
Aug 11, 2025For transradial amputees, robotic prosthetic hands promise to regain the capability to perform daily living activities. To advance next-generation prosthetic hand control design, it is crucial to address current shortcomings in robustness to out of lab artifacts, and generalizability to new environments. Due to the fixed number of object to interact with in existing datasets, contrasted with the virtually infinite variety of objects encountered in the real world, current grasp models perform poorly on unseen objects, negatively affecting users' independence and quality of life. To address this: (i) we define semantic projection, the ability of a model to generalize to unseen object types and show that conventional models like YOLO, despite 80% training accuracy, drop to 15% on unseen objects. (ii) we propose Grasp-LLaVA, a Grasp Vision Language Model enabling human-like reasoning to infer the suitable grasp type estimate based on the object's physical characteristics resulting in a significant 50.2% accuracy over unseen object types compared to 36.7% accuracy of an SOTA grasp estimation model. Lastly, to bridge the performance-latency gap, we propose Hybrid Grasp Network (HGN), an edge-cloud deployment infrastructure enabling fast grasp estimation on edge and accurate cloud inference as a fail-safe, effectively expanding the latency vs. accuracy Pareto. HGN with confidence calibration (DC) enables dynamic switching between edge and cloud models, improving semantic projection accuracy by 5.6% (to 42.3%) with 3.5x speedup over the unseen object types. Over a real-world sample mix, it reaches 86% average accuracy (12.2% gain over edge-only), and 2.2x faster inference than Grasp-LLaVA alone.
CleAR: Robust Context-Guided Generative Lighting Estimation for Mobile Augmented Reality
Nov 04, 2024


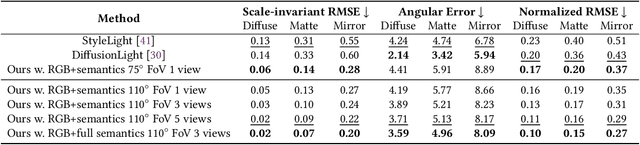
High-quality environment lighting is the foundation of creating immersive user experiences in mobile augmented reality (AR) applications. However, achieving visually coherent environment lighting estimation for Mobile AR is challenging due to several key limitations associated with AR device sensing capabilities, including limitations in device camera FoV and pixel dynamic ranges. Recent advancements in generative AI, which can generate high-quality images from different types of prompts, including texts and images, present a potential solution for high-quality lighting estimation. Still, to effectively use generative image diffusion models, we must address their key limitations of generation hallucination and slow inference process. To do so, in this work, we design and implement a generative lighting estimation system called CleAR that can produce high-quality and diverse environment maps in the format of 360$^\circ$ images. Specifically, we design a two-step generation pipeline guided by AR environment context data to ensure the results follow physical environment visual context and color appearances. To improve the estimation robustness under different lighting conditions, we design a real-time refinement component to adjust lighting estimation results on AR devices. To train and test our generative models, we curate a large-scale environment lighting estimation dataset with diverse lighting conditions. Through quantitative evaluation and user study, we show that CleAR outperforms state-of-the-art lighting estimation methods on both estimation accuracy and robustness. Moreover, CleAR supports real-time refinement of lighting estimation results, ensuring robust and timely environment lighting updates for AR applications. Our end-to-end generative estimation takes as fast as 3.2 seconds, outperforming state-of-the-art methods by 110x.
RoVaR: Robust Multi-agent Tracking through Dual-layer Diversity in Visual and RF Sensor Fusion
Jul 06, 2022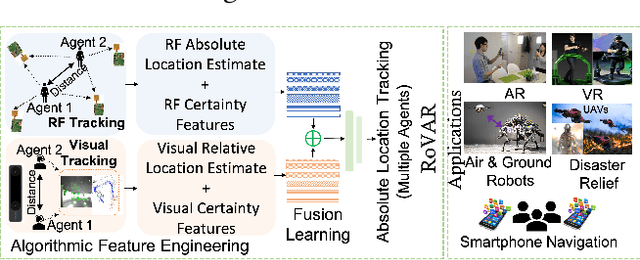



The plethora of sensors in our commodity devices provides a rich substrate for sensor-fused tracking. Yet, today's solutions are unable to deliver robust and high tracking accuracies across multiple agents in practical, everyday environments - a feature central to the future of immersive and collaborative applications. This can be attributed to the limited scope of diversity leveraged by these fusion solutions, preventing them from catering to the multiple dimensions of accuracy, robustness (diverse environmental conditions) and scalability (multiple agents) simultaneously. In this work, we take an important step towards this goal by introducing the notion of dual-layer diversity to the problem of sensor fusion in multi-agent tracking. We demonstrate that the fusion of complementary tracking modalities, - passive/relative (e.g., visual odometry) and active/absolute tracking (e.g., infrastructure-assisted RF localization) offer a key first layer of diversity that brings scalability while the second layer of diversity lies in the methodology of fusion, where we bring together the complementary strengths of algorithmic (for robustness) and data-driven (for accuracy) approaches. RoVaR is an embodiment of such a dual-layer diversity approach that intelligently attends to cross-modal information using algorithmic and data-driven techniques that jointly share the burden of accurately tracking multiple agents in the wild. Extensive evaluations reveal RoVaR's multi-dimensional benefits in terms of tracking accuracy (median of 15cm), robustness (in unseen environments), light weight (runs in real-time on mobile platforms such as Jetson Nano/TX2), to enable practical multi-agent immersive applications in everyday environments.