 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR as an Evaluation Playground: Bridging Metrics and Visual Perception of Computer Vision Models
Aug 06, 2025Human perception studies can provide complementary insights to qualitative evaluation for understanding computer vision (CV) model performance. However, conducting human perception studies remains a non-trivial task, it often requires complex, end-to-end system setups that are time-consuming and difficult to scale. In this paper, we explore the unique opportunity presented by augmented reality (AR) for helping CV researchers to conduct perceptual studies. We design ARCADE, an evaluation platform that allows researchers to easily leverage AR's rich context and interactivity for human-centered CV evaluation. Specifically, ARCADE supports cross-platform AR data collection, custom experiment protocols via pluggable model inference, and AR streaming for user studies. We demonstrate ARCADE using two types of CV models, depth and lighting estimation and show that AR tasks can be effectively used to elicit human perceptual judgments of model quality. We also evaluate the systems usability and performance across different deployment and study settings, highlighting its flexibility and effectiveness as a human-centered evaluation platform.
CleAR: Robust Context-Guided Generative Lighting Estimation for Mobile Augmented Reality
Nov 04, 2024


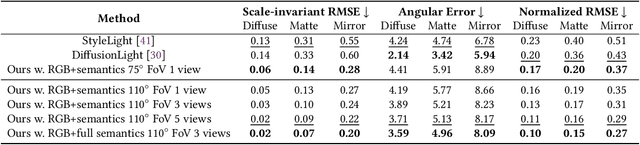
High-quality environment lighting is the foundation of creating immersive user experiences in mobile augmented reality (AR) applications. However, achieving visually coherent environment lighting estimation for Mobile AR is challenging due to several key limitations associated with AR device sensing capabilities, including limitations in device camera FoV and pixel dynamic ranges. Recent advancements in generative AI, which can generate high-quality images from different types of prompts, including texts and images, present a potential solution for high-quality lighting estimation. Still, to effectively use generative image diffusion models, we must address their key limitations of generation hallucination and slow inference process. To do so, in this work, we design and implement a generative lighting estimation system called CleAR that can produce high-quality and diverse environment maps in the format of 360$^\circ$ images. Specifically, we design a two-step generation pipeline guided by AR environment context data to ensure the results follow physical environment visual context and color appearances. To improve the estimation robustness under different lighting conditions, we design a real-time refinement component to adjust lighting estimation results on AR devices. To train and test our generative models, we curate a large-scale environment lighting estimation dataset with diverse lighting conditions. Through quantitative evaluation and user study, we show that CleAR outperforms state-of-the-art lighting estimation methods on both estimation accuracy and robustness. Moreover, CleAR supports real-time refinement of lighting estimation results, ensuring robust and timely environment lighting updates for AR applications. Our end-to-end generative estimation takes as fast as 3.2 seconds, outperforming state-of-the-art methods by 110x.
Mobile AR Depth Estimation: Challenges & Prospects -- Extended Version
Oct 22, 2023



Metric depth estimation plays an important role in mobile augmented reality (AR). With accurate metric depth, we can achieve more realistic user interactions such as object placement and occlusion detection. While specialized hardware like LiDAR demonstrates its promise, its restricted availability, i.e., only on selected high-end mobile devices, and performance limitations such as range and sensitivity to the environment, make it less ideal. Monocular depth estimation, on the other hand, relies solely on mobile cameras, which are ubiquitous, making it a promising alternative for mobile AR. In this paper, we investigate the challenges and opportunities of achieving accurate metric depth estimation in mobile AR. We tested four different state-of-the-art monocular depth estimation models on a newly introduced dataset (ARKitScenes) and identified three types of challenges: hard-ware, data, and model related challenges. Furthermore, our research provides promising future directions to explore and solve those challenges. These directions include (i) using more hardware-related information from the mobile device's camera and other available sensors, (ii) capturing high-quality data to reflect real-world AR scenarios, and (iii) designing a model architecture to utilize the new information.
LitAR: Visually Coherent Lighting for Mobile Augmented Reality
Jan 15, 2023



An accurate understanding of omnidirectional environment lighting is crucial for high-quality virtual object rendering in mobile augmented reality (AR). In particular, to support reflective rendering, existing methods have leveraged deep learning models to estimate or have used physical light probes to capture physical lighting, typically represented in the form of an environment map. However, these methods often fail to provide visually coherent details or require additional setups. For example, the commercial framework ARKit uses a convolutional neural network that can generate realistic environment maps; however the corresponding reflective rendering might not match the physical environments. In this work, we present the design and implementation of a lighting reconstruction framework called LitAR that enables realistic and visually-coherent rendering. LitAR addresses several challenges of supporting lighting information for mobile AR. First, to address the spatial variance problem, LitAR uses two-field lighting reconstruction to divide the lighting reconstruction task into the spatial variance-aware near-field reconstruction and the directional-aware far-field reconstruction. The corresponding environment map allows reflective rendering with correct color tones. Second, LitAR uses two noise-tolerant data capturing policies to ensure data quality, namely guided bootstrapped movement and motion-based automatic capturing. Third, to handle the mismatch between the mobile computation capability and the high computation requirement of lighting reconstruction, LitAR employs two novel real-time environment map rendering techniques called multi-resolution projection and anchor extrapolation. These two techniques effectively remove the need of time-consuming mesh reconstruction while maintaining visual quality.
Multi-Camera Lighting Estimation for Photorealistic Front-Facing Mobile Augmented Reality
Jan 15, 2023Lighting understanding plays an important role in virtual object composition, including mobile augmented reality (AR) applications. Prior work often targets recovering lighting from the physical environment to support photorealistic AR rendering. Because the common workflow is to use a back-facing camera to capture the physical world for overlaying virtual objects, we refer to this usage pattern as back-facing AR. However, existing methods often fall short in supporting emerging front-facing mobile AR applications, e.g., virtual try-on where a user leverages a front-facing camera to explore the effect of various products (e.g., glasses or hats) of different styles. This lack of support can be attributed to the unique challenges of obtaining 360$^\circ$ HDR environment maps, an ideal format of lighting representation, from the front-facing camera and existing techniques. In this paper, we propose to leverage dual-camera streaming to generate a high-quality environment map by combining multi-view lighting reconstruction and parametric directional lighting estimation. Our preliminary results show improved rendering quality using a dual-camera setup for front-facing AR compared to a commercial solution.
PointAR: Efficient Lighting Estimation for Mobile Augmented Reality
Mar 30, 2020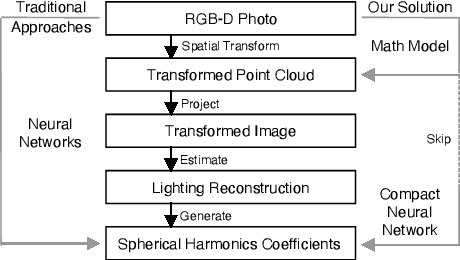
We propose an efficient lighting estimation pipeline that is suitable to run on modern mobile devices, with comparable resource complexities to state-of-the-art on-device deep learning models. Our pipeline, referred to as PointAR, takes a single RGB-D image captured from the mobile camera and a 2D location in that image, and estimates a 2nd order spherical harmonics coefficients which can be directly utilized by rendering engines for indoor lighting in the context of augmented reality. Our key insight is to formulate the lighting estimation as a learning problem directly from point clouds, which is in part inspired by the Monte Carlo integration leveraged by real-time spherical harmonics lighting. While existing approaches estimate lighting information with complex deep learning pipelines, our method focuses on reducing the computational complexity. Through both quantitative and qualitative experiments, we demonstrate that PointAR achieves lower lighting estimation errors compared to state-of-the-art methods. Further, our method requires an order of magnitude lower resource, comparable to that of mobile-specific DNNs.