 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Concurrency Mechanisms for NVIDIA GPUs under Deep Learning Workloads
Oct 01, 2021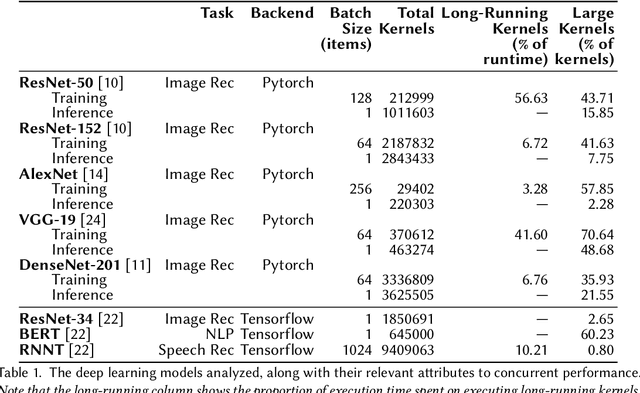
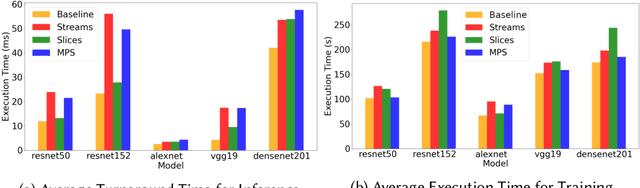
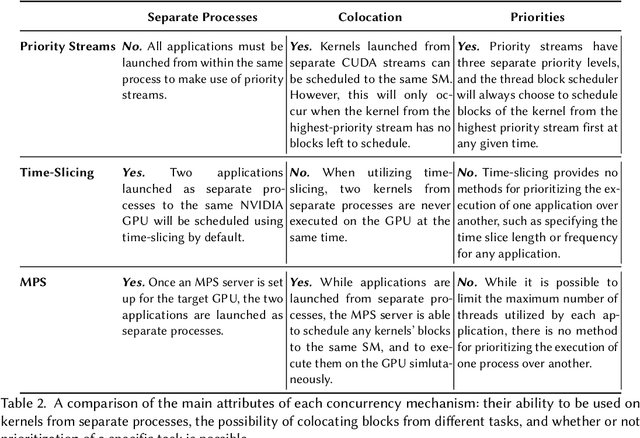

We investigate the performance of the concurrency mechanisms available on NVIDIA's new Ampere GPU microarchitecture under deep learning training and inference workloads. In contrast to previous studies that treat the GPU as a black box, we examine scheduling at the microarchitectural level. We find that the lack of fine-grained preemption mechanisms, robust task prioritization options, and contention-aware thread block placement policies limits the effectiveness of NVIDIA's concurrency mechanisms. In summary, the sequential nature of deep learning workloads and their fluctuating resource requirements and kernel runtimes make executing such workloads while maintaining consistently high utilization and low, predictable turnaround times difficult on current NVIDIA hardware.
Memory-Efficient Deep Learning Inference in Trusted Execution Environments
Apr 30, 2021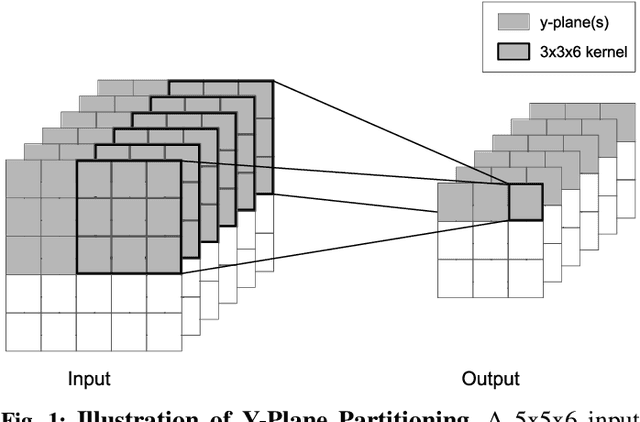
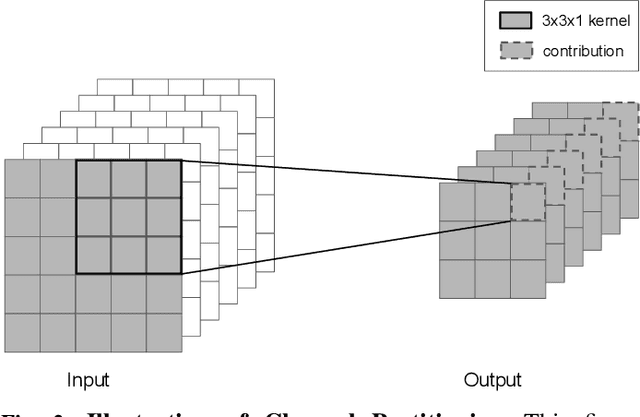
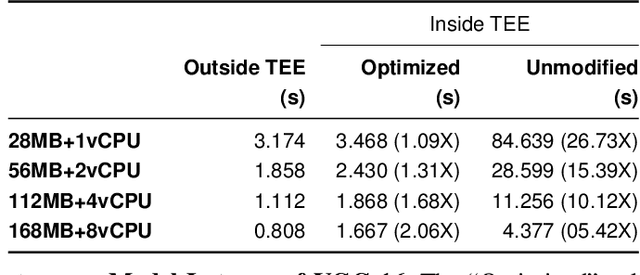
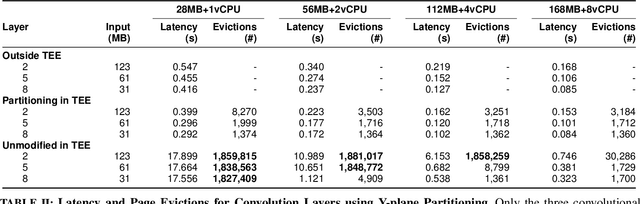
This study identifies and proposes techniques to alleviate two key bottlenecks to executing deep neural networks in trusted execution environments (TEEs): page thrashing during the execution of convolutional layers and the decryption of large weight matrices in fully-connected layers. For the former, we propose a novel partitioning scheme, y-plane partitioning, designed to (ii) provide consistent execution time when the layer output is large compared to the TEE secure memory; and (ii) significantly reduce the memory footprint of convolutional layers. For the latter, we leverage quantization and compression. In our evaluation, the proposed optimizations incurred latency overheads ranging from 1.09X to 2X baseline for a wide range of TEE sizes; in contrast, an unmodified implementation incurred latencies of up to 26X when running inside of the TEE.
Characterizing and Modeling Distributed Training with Transient Cloud GPU Servers
Apr 07, 2020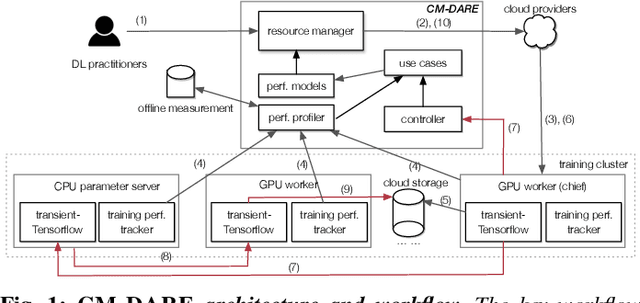
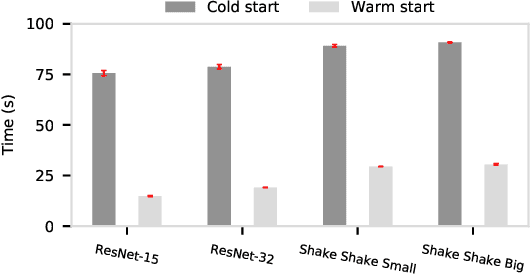
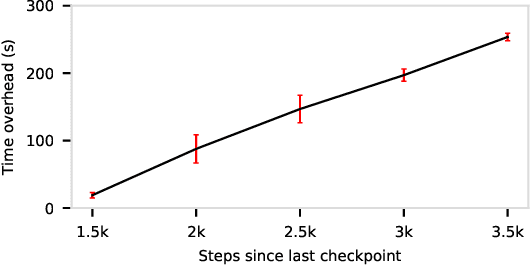
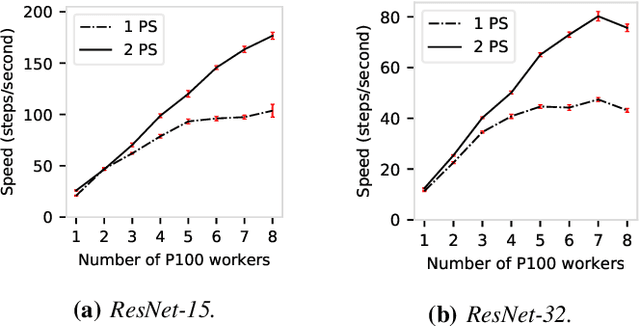
Cloud GPU servers have become the de facto way for deep learning practitioners to train complex models on large-scale datasets. However, it is challenging to determine the appropriate cluster configuration---e.g., server type and number---for different training workloads while balancing the trade-offs in training time, cost, and model accuracy. Adding to the complexity is the potential to reduce the monetary cost by using cheaper, but revocable, transient GPU servers. In this work, we analyze distributed training performance under diverse cluster configurations using CM-DARE, a cloud-based measurement and training framework. Our empirical datasets include measurements from three GPU types, six geographic regions, twenty convolutional neural networks, and thousands of Google Cloud servers. We also demonstrate the feasibility of predicting training speed and overhead using regression-based models. Finally, we discuss potential use cases of our performance modeling such as detecting and mitigating performance bottlenecks.
Confidential Deep Learning: Executing Proprietary Models on Untrusted Devices
Aug 28, 2019
Performing deep learning on end-user devices provides fast offline inference results and can help protect the user's privacy. However, running models on untrusted client devices reveals model information which may be proprietary, i.e., the operating system or other applications on end-user devices may be manipulated to copy and redistribute this information, infringing on the model provider's intellectual property. We propose the use of ARM TrustZone, a hardware-based security feature present in most phones, to confidentially run a proprietary model on an untrusted end-user device. We explore the limitations and design challenges of using TrustZone and examine potential approaches for confidential deep learning within this environment. Of particular interest is providing robust protection of proprietary model information while minimizing total performance overhead.
Speeding up Deep Learning with Transient Servers
Feb 28, 2019

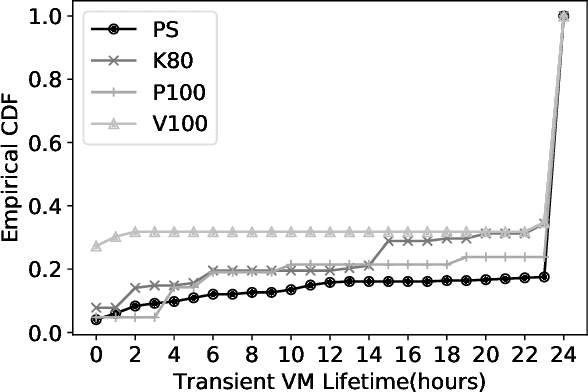
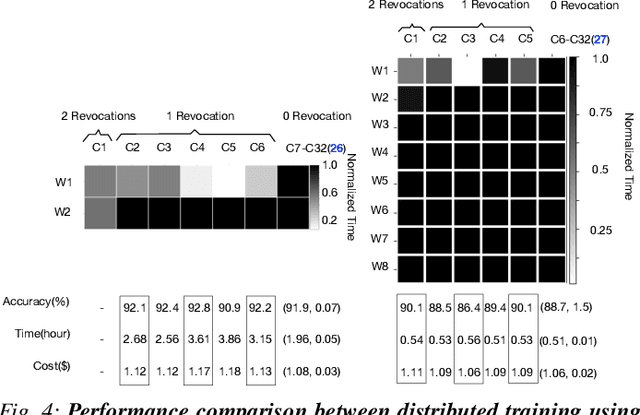
Distributed training frameworks, like TensorFlow, have been proposed as a means to reduce the training time of deep learning models by using a cluster of GPU servers. While such speedups are often desirable---e.g., for rapidly evaluating new model designs---they often come with significantly higher monetary costs due to sublinear scalability. In this paper, we investigate the feasibility of using training clusters composed of cheaper transient GPU servers to get the benefits of distributed training without the high costs. We conduct the first large-scale empirical analysis, launching more than a thousand GPU servers of various capacities, aimed at understanding the characteristics of transient GPU servers and their impact on distributed training performance. Our study demonstrates the potential of transient servers with a speedup of 7.7X with more than 62.9% monetary savings for some cluster configurations. We also identify a number of important challenges and opportunities for redesigning distributed training frameworks to be transient-aware. For example, the dynamic cost and availability characteristics of transient servers suggest the need for frameworks to dynamically change cluster configurations to best take advantage of current conditions.