 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Concurrency Mechanisms for NVIDIA GPUs under Deep Learning Workloads
Paper and Code
Oct 01, 2021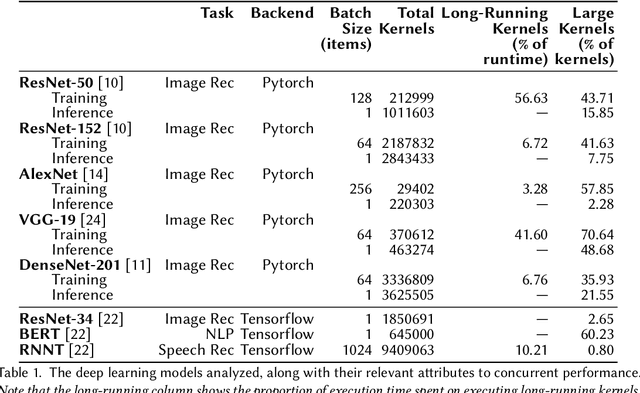
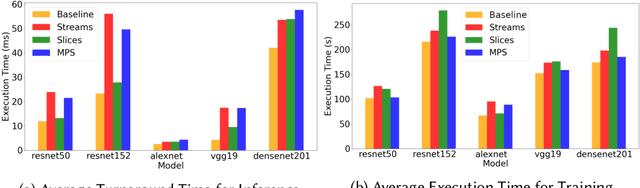
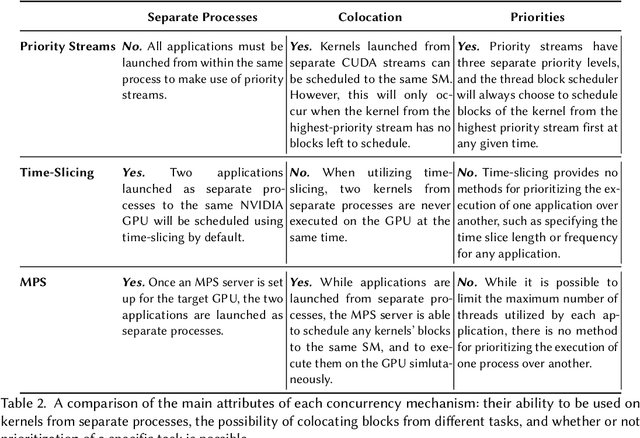

We investigate the performance of the concurrency mechanisms available on NVIDIA's new Ampere GPU microarchitecture under deep learning training and inference workloads. In contrast to previous studies that treat the GPU as a black box, we examine scheduling at the microarchitectural level. We find that the lack of fine-grained preemption mechanisms, robust task prioritization options, and contention-aware thread block placement policies limits the effectiveness of NVIDIA's concurrency mechanisms. In summary, the sequential nature of deep learning workloads and their fluctuating resource requirements and kernel runtimes make executing such workloads while maintaining consistently high utilization and low, predictable turnaround times difficult on current NVIDIA hardware.