 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Deep Learning Inference in Trusted Execution Environments
Apr 30, 2021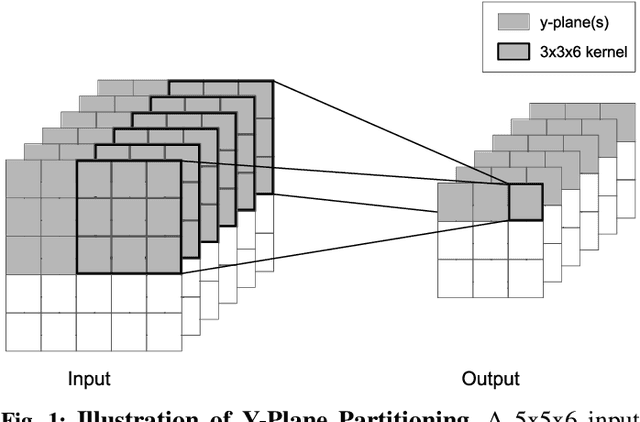
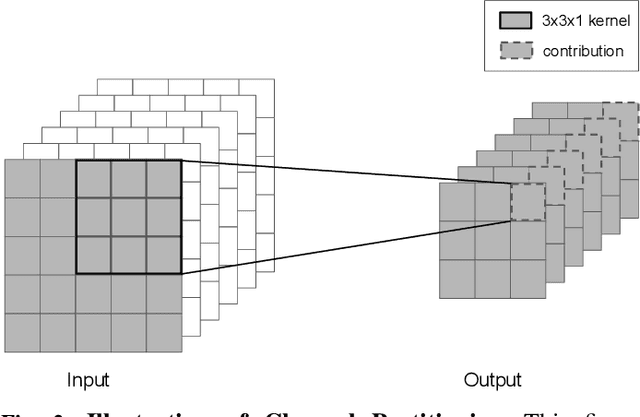
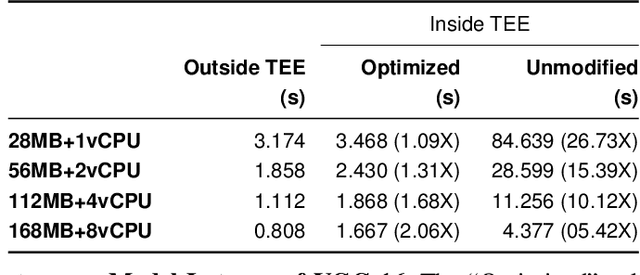
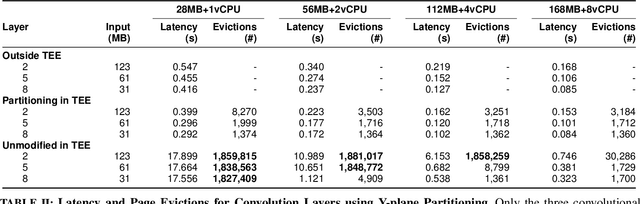
This study identifies and proposes techniques to alleviate two key bottlenecks to executing deep neural networks in trusted execution environments (TEEs): page thrashing during the execution of convolutional layers and the decryption of large weight matrices in fully-connected layers. For the former, we propose a novel partitioning scheme, y-plane partitioning, designed to (ii) provide consistent execution time when the layer output is large compared to the TEE secure memory; and (ii) significantly reduce the memory footprint of convolutional layers. For the latter, we leverage quantization and compression. In our evaluation, the proposed optimizations incurred latency overheads ranging from 1.09X to 2X baseline for a wide range of TEE sizes; in contrast, an unmodified implementation incurred latencies of up to 26X when running inside of the TEE.
Data-Free Model Extraction
Nov 30, 2020



Current model extraction attacks assume that the adversary has access to a surrogate dataset with characteristics similar to the proprietary data used to train the victim model. This requirement precludes the use of existing model extraction techniques on valuable models, such as those trained on rare or hard to acquire datasets. In contrast, we propose data-free model extraction methods that do not require a surrogate dataset. Our approach adapts techniques from the area of data-free knowledge transfer for model extraction. As part of our study, we identify that the choice of loss is critical to ensuring that the extracted model is an accurate replica of the victim model. Furthermore, we address difficulties arising from the adversary's limited access to the victim model in a black-box setting. For example, we recover the model's logits from its probability predictions to approximate gradients. We find that the proposed data-free model extraction approach achieves high-accuracy with reasonable query complexity -- 0.99x and 0.92x the victim model accuracy on SVHN and CIFAR-10 datasets given 2M and 20M queries respectively.