 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Deep Learning Inference in Trusted Execution Environments
Paper and Code
Apr 30, 2021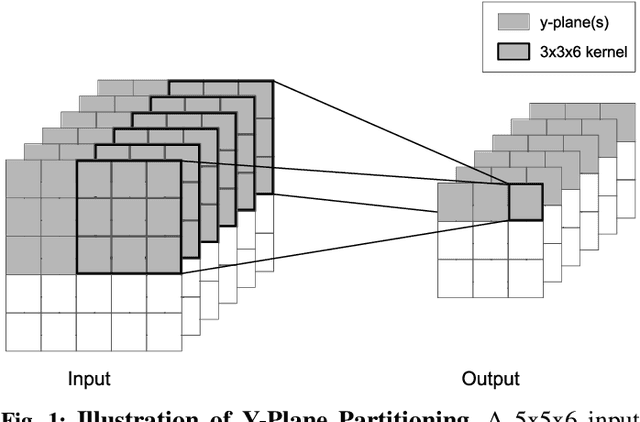
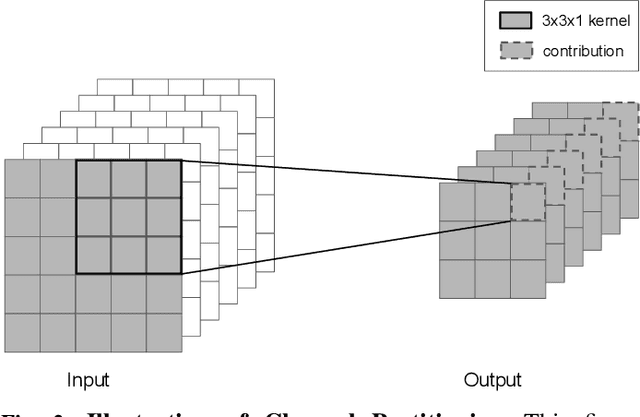
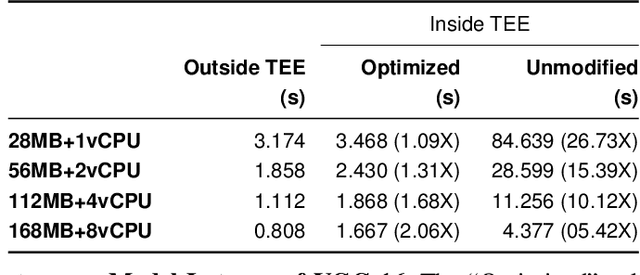
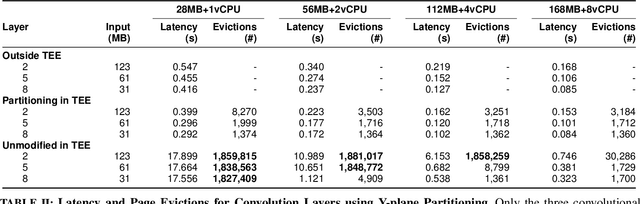
This study identifies and proposes techniques to alleviate two key bottlenecks to executing deep neural networks in trusted execution environments (TEEs): page thrashing during the execution of convolutional layers and the decryption of large weight matrices in fully-connected layers. For the former, we propose a novel partitioning scheme, y-plane partitioning, designed to (ii) provide consistent execution time when the layer output is large compared to the TEE secure memory; and (ii) significantly reduce the memory footprint of convolutional layers. For the latter, we leverage quantization and compression. In our evaluation, the proposed optimizations incurred latency overheads ranging from 1.09X to 2X baseline for a wide range of TEE sizes; in contrast, an unmodified implementation incurred latencies of up to 26X when running inside of the TEE.