 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssemLM: Spatial Reasoning Multimodal Large Language Models for Robotic Assembly
Apr 10, 2026Spatial reasoning is a fundamental capability for embodied intelligence, especially for fine-grained manipulation tasks such as robotic assembly. While recent vision-language models (VLMs) exhibit preliminary spatial awareness, they largely rely on coarse 2D perception and lack the ability to perform accurate reasoning over 3D geometry, which is crucial for precise assembly operations. To address this limitation, we propose AssemLM, a spatial multimodal large language model tailored for robotic assembly. AssemLM integrates assembly manuals, point clouds, and textual instructions to reason about and predict task-critical 6D assembly poses, enabling explicit geometric understanding throughout the assembly process. To effectively bridge raw 3D perception and high-level reasoning, we adopt a specialized point cloud encoder to capture fine-grained geometric and rotational features, which are then integrated into the multimodal language model to support accurate 3D spatial reasoning for assembly tasks. In addition, we construct AssemBench, a large-scale dataset and benchmark for assembly-oriented spatial reasoning, comprising over 900K multimodal samples with precise 6D pose annotations. AssemBench extends spatial reasoning evaluation beyond 2D and grounding tasks into full 3D geometric inference, filling a critical gap in existing embodied AI benchmarks. Extensive experiments demonstrate that AssemLM achieves state-of-the-art performance in 6D pose reasoning across diverse assembly scenarios. Furthermore, real-robot evaluations show that our model can support fine-grained and multi-step assembly execution in real-world settings, demonstrating its potential for robotic assembly applications.
Model-based Offline RL via Robust Value-Aware Model Learning with Implicitly Differentiable Adaptive Weighting
Mar 09, 2026Model-based offline reinforcement learning (RL) aims to enhance offline RL with a dynamics model that facilitates policy exploration. However, \textit{model exploitation} could occur due to inevitable model errors, degrading algorithm performance. Adversarial model learning offers a theoretical framework to mitigate model exploitation by solving a maximin formulation. Within such a paradigm, RAMBO~\citep{rigter2022rambo} has emerged as a representative and most popular method that provides a practical implementation with model gradient. However, we empirically reveal that severe Q-value underestimation and gradient explosion can occur in RAMBO with only slight hyperparameter tuning, suggesting that it tends to be overly conservative and suffers from unstable model updates. To address these issues, we propose \textbf{RO}bust value-aware \textbf{M}odel learning with \textbf{I}mplicitly differentiable adaptive weighting (ROMI). Instead of updating the dynamics model with model gradient, ROMI introduces a novel robust value-aware model learning approach. This approach requires the dynamics model to predict future states with values close to the minimum Q-value within a scale-adjustable state uncertainty set, enabling controllable conservatism and stable model updates. To further improve out-of-distribution (OOD) generalization during multi-step rollouts, we propose implicitly differentiable adaptive weighting, a bi-level optimization scheme that adaptively achieves dynamics- and value-aware model learning. Empirical results on D4RL and NeoRL datasets show that ROMI significantly outperforms RAMBO and achieves competitive or superior performance compared to other state-of-the-art methods on datasets where RAMBO typically underperforms. Code is available at https://github.com/zq2r/ROMI.git.
Deep Dense Exploration for LLM Reinforcement Learning via Pivot-Driven Resampling
Feb 15, 2026Effective exploration is a key challenge in reinforcement learning for large language models: discovering high-quality trajectories within a limited sampling budget from the vast natural language sequence space. Existing methods face notable limitations: GRPO samples exclusively from the root, saturating high-probability trajectories while leaving deep, error-prone states under-explored. Tree-based methods blindly disperse budgets across trivial or unrecoverable states, causing sampling dilution that fails to uncover rare correct suffixes and destabilizes local baselines. To address this, we propose Deep Dense Exploration (DDE), a strategy that focuses exploration on $\textit{pivots}$-deep, recoverable states within unsuccessful trajectories. We instantiate DDE with DEEP-GRPO, which introduces three key innovations: (1) a lightweight data-driven utility function that automatically balances recoverability and depth bias to identify pivot states; (2) local dense resampling at each pivot to increase the probability of discovering correct subsequent trajectories; and (3) a dual-stream optimization objective that decouples global policy learning from local corrective updates. Experiments on mathematical reasoning benchmarks demonstrate that our method consistently outperforms GRPO, tree-based methods, and other strong baselines.
SparVAR: Exploring Sparsity in Visual AutoRegressive Modeling for Training-Free Acceleration
Feb 04, 2026Visual AutoRegressive (VAR) modeling has garnered significant attention for its innovative next-scale prediction paradigm. However, mainstream VAR paradigms attend to all tokens across historical scales at each autoregressive step. As the next scale resolution grows, the computational complexity of attention increases quartically with resolution, causing substantial latency. Prior accelerations often skip high-resolution scales, which speeds up inference but discards high-frequency details and harms image quality. To address these problems, we present SparVAR, a training-free acceleration framework that exploits three properties of VAR attention: (i) strong attention sinks, (ii) cross-scale activation similarity, and (iii) pronounced locality. Specifically, we dynamically predict the sparse attention pattern of later high-resolution scales from a sparse decision scale, and construct scale self-similar sparse attention via an efficient index-mapping mechanism, enabling high-efficiency sparse attention computation at large scales. Furthermore, we propose cross-scale local sparse attention and implement an efficient block-wise sparse kernel, which achieves $\mathbf{> 5\times}$ faster forward speed than FlashAttention. Extensive experiments demonstrate that the proposed SparseVAR can reduce the generation time of an 8B model producing $1024\times1024$ high-resolution images to the 1s, without skipping the last scales. Compared with the VAR baseline accelerated by FlashAttention, our method achieves a $\mathbf{1.57\times}$ speed-up while preserving almost all high-frequency details. When combined with existing scale-skipping strategies, SparseVAR attains up to a $\mathbf{2.28\times}$ acceleration, while maintaining competitive visual generation quality. Code is available at https://github.com/CAS-CLab/SparVAR.
USIM and U0: A Vision-Language-Action Dataset and Model for General Underwater Robots
Oct 09, 2025



Underwater environments present unique challenges for robotic operation, including complex hydrodynamics, limited visibility, and constrained communication. Although data-driven approaches have advanced embodied intelligence in terrestrial robots and enabled task-specific autonomous underwater robots, developing underwater intelligence capable of autonomously performing multiple tasks remains highly challenging, as large-scale, high-quality underwater datasets are still scarce. To address these limitations, we introduce USIM, a simulation-based multi-task Vision-Language-Action (VLA) dataset for underwater robots. USIM comprises over 561K frames from 1,852 trajectories, totaling approximately 15.6 hours of BlueROV2 interactions across 20 tasks in 9 diverse scenarios, ranging from visual navigation to mobile manipulation. Building upon this dataset, we propose U0, a VLA model for general underwater robots, which integrates binocular vision and other sensor modalities through multimodal fusion, and further incorporates a convolution-attention-based perception focus enhancement module (CAP) to improve spatial understanding and mobile manipulation. Across tasks such as inspection, obstacle avoidance, scanning, and dynamic tracking, the framework achieves a success rate of 80%, while in challenging mobile manipulation tasks, it reduces the distance to the target by 21.2% compared with baseline methods, demonstrating its effectiveness. USIM and U0 show that VLA models can be effectively applied to underwater robotic applications, providing a foundation for scalable dataset construction, improved task autonomy, and the practical realization of intelligent general underwater robots.
LatticeWorld: A Multimodal Large Language Model-Empowered Framework for Interactive Complex World Generation
Sep 05, 2025

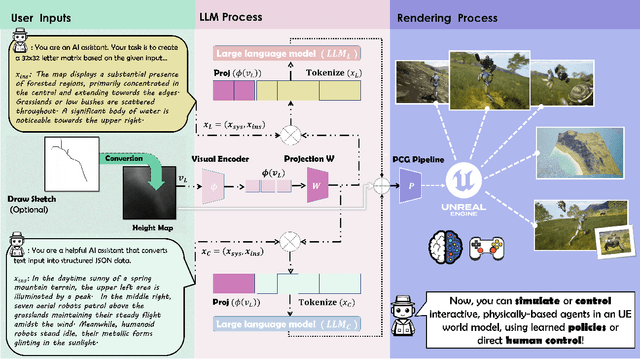
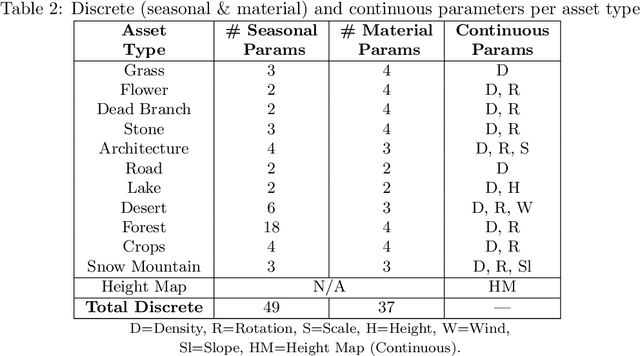
Recent research has been increasingly focusing on developing 3D world models that simulate complex real-world scenarios. World models have found broad applications across various domains, including embodied AI, autonomous driving, entertainment, etc. A more realistic simulation with accurate physics will effectively narrow the sim-to-real gap and allow us to gather rich information about the real world conveniently. While traditional manual modeling has enabled the creation of virtual 3D scenes, modern approaches have leveraged advanced machine learning algorithms for 3D world generation, with most recent advances focusing on generative methods that can create virtual worlds based on user instructions. This work explores such a research direction by proposing LatticeWorld, a simple yet effective 3D world generation framework that streamlines the industrial production pipeline of 3D environments. LatticeWorld leverages lightweight LLMs (LLaMA-2-7B) alongside the industry-grade rendering engine (e.g., Unreal Engine 5) to generate a dynamic environment. Our proposed framework accepts textual descriptions and visual instructions as multimodal inputs and creates large-scale 3D interactive worlds with dynamic agents, featuring competitive multi-agent interaction, high-fidelity physics simulation, and real-time rendering. We conduct comprehensive experiments to evaluate LatticeWorld, showing that it achieves superior accuracy in scene layout generation and visual fidelity. Moreover, LatticeWorld achieves over a $90\times$ increase in industrial production efficiency while maintaining high creative quality compared with traditional manual production methods. Our demo video is available at https://youtu.be/8VWZXpERR18
Segment Policy Optimization: Effective Segment-Level Credit Assignment in RL for Large Language Models
May 29, 2025Enhancing the reasoning capabilities of large language models effectively using reinforcement learning (RL) remains a crucial challenge. Existing approaches primarily adopt two contrasting advantage estimation granularities: Token-level methods (e.g., PPO) aim to provide the fine-grained advantage signals but suffer from inaccurate estimation due to difficulties in training an accurate critic model. On the other extreme, trajectory-level methods (e.g., GRPO) solely rely on a coarse-grained advantage signal from the final reward, leading to imprecise credit assignment. To address these limitations, we propose Segment Policy Optimization (SPO), a novel RL framework that leverages segment-level advantage estimation at an intermediate granularity, achieving a better balance by offering more precise credit assignment than trajectory-level methods and requiring fewer estimation points than token-level methods, enabling accurate advantage estimation based on Monte Carlo (MC) without a critic model. SPO features three components with novel strategies: (1) flexible segment partition; (2) accurate segment advantage estimation; and (3) policy optimization using segment advantages, including a novel probability-mask strategy. We further instantiate SPO for two specific scenarios: (1) SPO-chain for short chain-of-thought (CoT), featuring novel cutpoint-based partition and chain-based advantage estimation, achieving $6$-$12$ percentage point improvements in accuracy over PPO and GRPO on GSM8K. (2) SPO-tree for long CoT, featuring novel tree-based advantage estimation, which significantly reduces the cost of MC estimation, achieving $7$-$11$ percentage point improvements over GRPO on MATH500 under 2K and 4K context evaluation. We make our code publicly available at https://github.com/AIFrameResearch/SPO.
Revisiting Multi-Agent World Modeling from a Diffusion-Inspired Perspective
May 27, 2025



World models have recently attracted growing interest in Multi-Agent Reinforcement Learning (MARL) due to their ability to improve sample efficiency for policy learning. However, accurately modeling environments in MARL is challenging due to the exponentially large joint action space and highly uncertain dynamics inherent in multi-agent systems. To address this, we reduce modeling complexity by shifting from jointly modeling the entire state-action transition dynamics to focusing on the state space alone at each timestep through sequential agent modeling. Specifically, our approach enables the model to progressively resolve uncertainty while capturing the structured dependencies among agents, providing a more accurate representation of how agents influence the state. Interestingly, this sequential revelation of agents' actions in a multi-agent system aligns with the reverse process in diffusion models--a class of powerful generative models known for their expressiveness and training stability compared to autoregressive or latent variable models. Leveraging this insight, we develop a flexible and robust world model for MARL using diffusion models. Our method, Diffusion-Inspired Multi-Agent world model (DIMA), achieves state-of-the-art performance across multiple multi-agent control benchmarks, significantly outperforming prior world models in terms of final return and sample efficiency, including MAMuJoCo and Bi-DexHands. DIMA establishes a new paradigm for constructing multi-agent world models, advancing the frontier of MARL research.
A novel gesture interaction control method for rehabilitation lower extremity exoskeleton
Apr 02, 2025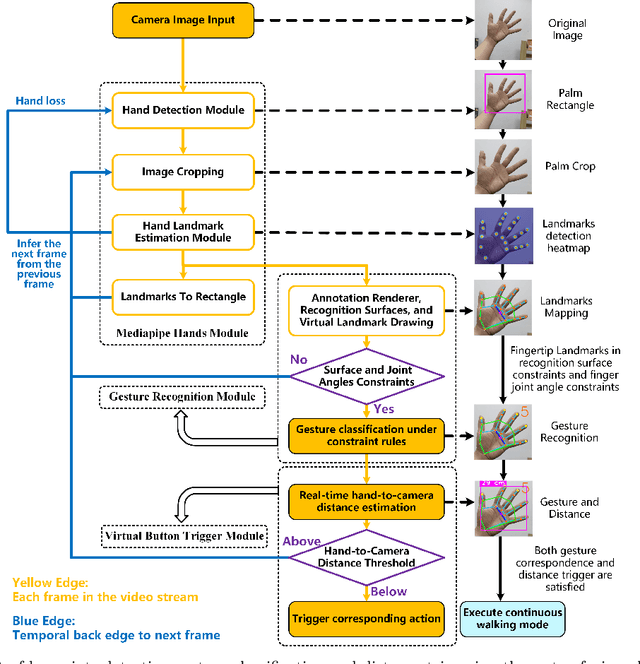
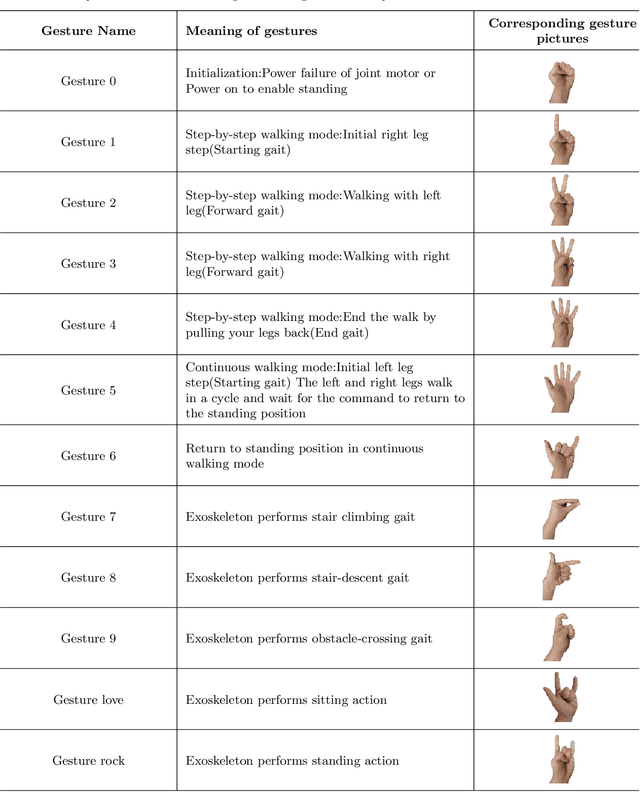
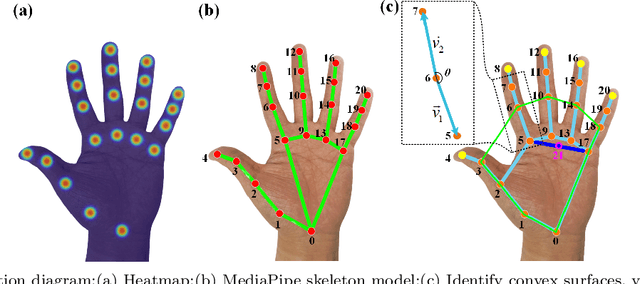
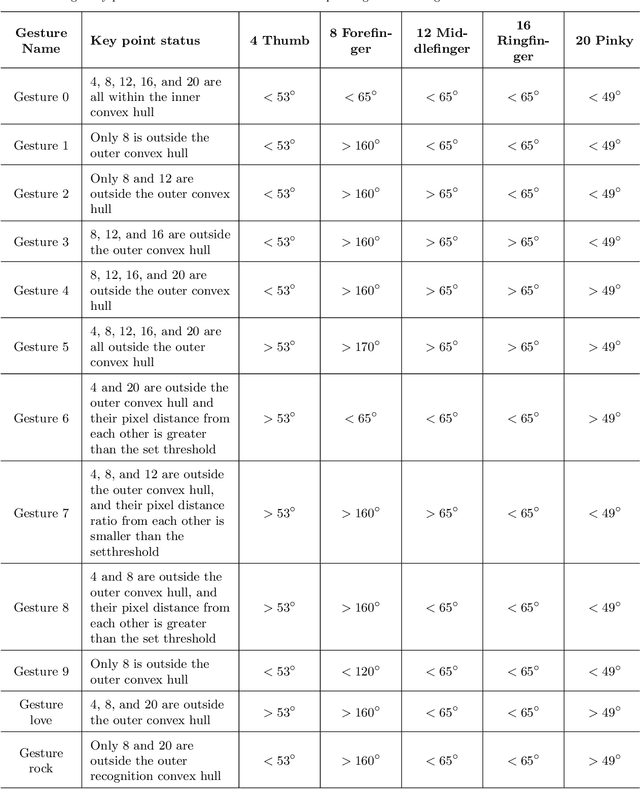
With the rapid development of Rehabilitation Lower Extremity Robotic Exoskeletons (RLEEX) technology, significant advancements have been made in Human-Robot Interaction (HRI) methods. These include traditional physical HRI methods that are easily recognizable and various bio-electrical signal-based HRI methods that can visualize and predict actions. However, most of these HRI methods are contact-based, facing challenges such as operational complexity, sensitivity to interference, risks associated with implantable devices, and, most importantly, limitations in comfort. These challenges render the interaction less intuitive and natural, which can negatively impact patient motivation for rehabilitation. To address these issues, this paper proposes a novel non-contact gesture interaction control method for RLEEX, based on RGB monocular camera depth estimation. This method integrates three key steps: detecting keypoints, recognizing gestures, and assessing distance, thereby applying gesture information and augmented reality triggering technology to control gait movements of RLEEX. Results indicate that this approach provides a feasible solution to the problems of poor comfort, low reliability, and high latency in HRI for RLEEX platforms. Specifically, it achieves a gesture-controlled exoskeleton motion accuracy of 94.11\% and an average system response time of 0.615 seconds through non-contact HRI. The proposed non-contact HRI method represents a pioneering advancement in control interactions for RLEEX, paving the way for further exploration and development in this field.
Integrating Language-Image Prior into EEG Decoding for Cross-Task Zero-Calibration RSVP-BCI
Jan 06, 2025



Rapid Serial Visual Presentation (RSVP)-based Brain-Computer Interface (BCI) is an effective technology used for information detection by detecting Event-Related Potentials (ERPs). The current RSVP decoding methods can perform well in decoding EEG signals within a single RSVP task, but their decoding performance significantly decreases when directly applied to different RSVP tasks without calibration data from the new tasks. This limits the rapid and efficient deployment of RSVP-BCI systems for detecting different categories of targets in various scenarios. To overcome this limitation, this study aims to enhance the cross-task zero-calibration RSVP decoding performance. First, we design three distinct RSVP tasks for target image retrieval and build an open-source dataset containing EEG signals and corresponding stimulus images. Then we propose an EEG with Language-Image Prior fusion Transformer (ELIPformer) for cross-task zero-calibration RSVP decoding. Specifically, we propose a prompt encoder based on the language-image pre-trained model to extract language-image features from task-specific prompts and stimulus images as prior knowledge for enhancing EEG decoding. A cross bidirectional attention mechanism is also adopted to facilitate the effective feature fusion and alignment between the EEG and language-image features. Extensive experiments demonstrate that the proposed model achieves superior performance in cross-task zero-calibration RSVP decoding, which promotes the RSVP-BCI system from research to practical application.